 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Visual Reasoning with Controlled Visual Inputs
Dec 19, 2025End-to-end Vision-language Models (VLMs) often answer visual questions by exploiting spurious correlations instead of causal visual evidence, and can become more shortcut-prone when fine-tuned. We introduce VISTA (Visual-Information Separation for Text-based Analysis), a modular framework that decouples perception from reasoning via an explicit information bottleneck. A frozen VLM sensor is restricted to short, objective perception queries, while a text-only LLM reasoner decomposes each question, plans queries, and aggregates visual facts in natural language. This controlled interface defines a reward-aligned environment for training unbiased visual reasoning with reinforcement learning. Instantiated with Qwen2.5-VL and Llama3.2-Vision sensors, and trained with GRPO from only 641 curated multi-step questions, VISTA significantly improves robustness to real-world spurious correlations on SpuriVerse (+16.29% with Qwen-2.5-VL-7B and +6.77% with Llama-3.2-Vision-11B), while remaining competitive on MMVP and a balanced SeedBench subset. VISTA transfers robustly across unseen VLM sensors and is able to recognize and recover from VLM perception failures. Human analysis further shows that VISTA's reasoning traces are more neutral, less reliant on spurious attributes, and more explicitly grounded in visual evidence than end-to-end VLM baselines.
CC-LEARN: Cohort-based Consistency Learning
Jun 18, 2025Large language models excel at many tasks but still struggle with consistent, robust reasoning. We introduce Cohort-based Consistency Learning (CC-Learn), a reinforcement learning framework that improves the reliability of LLM reasoning by training on cohorts of similar questions derived from shared programmatic abstractions. To enforce cohort-level consistency, we define a composite objective combining cohort accuracy, a retrieval bonus for effective problem decomposition, and a rejection penalty for trivial or invalid lookups that reinforcement learning can directly optimize, unlike supervised fine-tuning. Optimizing this reward guides the model to adopt uniform reasoning patterns across all cohort members. Experiments on challenging reasoning benchmarks (including ARC-Challenge and StrategyQA) show that CC-Learn boosts both accuracy and reasoning stability over pretrained and SFT baselines. These results demonstrate that cohort-level RL effectively enhances reasoning consistency in LLMs.
QA-LIGN: Aligning LLMs through Constitutionally Decomposed QA
Jun 09, 2025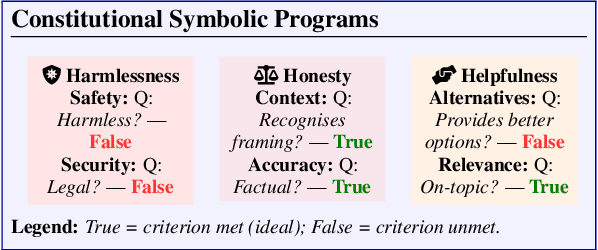
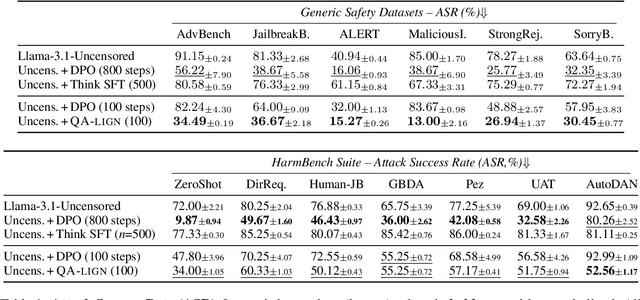

Alignment of large language models with explicit principles (such as helpfulness, honesty, and harmlessness) is crucial for ensuring safe and reliable AI systems. However, standard reward-based alignment methods typically collapse diverse feedback into a single scalar reward, entangling multiple objectives into one opaque training signal, which hinders interpretability. In this work, we introduce QA-LIGN, an automatic symbolic reward decomposition approach that preserves the structure of each constitutional principle within the reward mechanism. Instead of training a black-box reward model that outputs a monolithic score, QA-LIGN formulates principle-specific evaluation questions and derives separate reward components for each principle, making it a drop-in reward model replacement. Experiments aligning an uncensored large language model with a set of constitutional principles demonstrate that QA-LIGN offers greater transparency and adaptability in the alignment process. At the same time, our approach achieves performance on par with or better than a DPO baseline. Overall, these results represent a step toward more interpretable and controllable alignment of language models, achieved without sacrificing end-task performance.
ToW: Thoughts of Words Improve Reasoning in Large Language Models
Oct 21, 2024

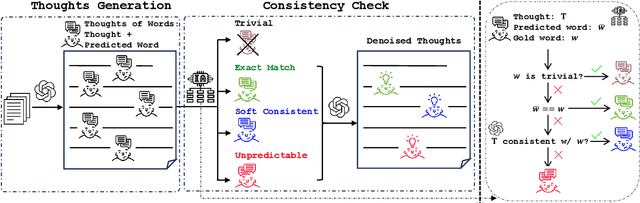
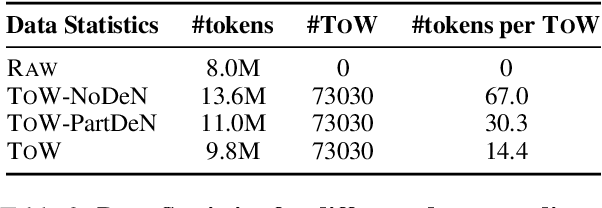
We introduce thoughts of words (ToW), a novel training-time data-augmentation method for next-word prediction. ToW views next-word prediction as a core reasoning task and injects fine-grained thoughts explaining what the next word should be and how it is related to the previous contexts in pre-training texts. Our formulation addresses two fundamental drawbacks of existing next-word prediction learning schemes: they induce factual hallucination and are inefficient for models to learn the implicit reasoning processes in raw texts. While there are many ways to acquire such thoughts of words, we explore the first step of acquiring ToW annotations through distilling from larger models. After continual pre-training with only 70K ToW annotations, we effectively improve models' reasoning performances by 7% to 9% on average and reduce model hallucination by up to 10%. At the same time, ToW is entirely agnostic to tasks and applications, introducing no additional biases on labels or semantics.
SysCaps: Language Interfaces for Simulation Surrogates of Complex Systems
May 30, 2024



Data-driven simulation surrogates help computational scientists study complex systems. They can also help inform impactful policy decisions. We introduce a learning framework for surrogate modeling where language is used to interface with the underlying system being simulated. We call a language description of a system a "system caption", or SysCap. To address the lack of datasets of paired natural language SysCaps and simulation runs, we use large language models (LLMs) to synthesize high-quality captions. Using our framework, we train multimodal text and timeseries regression models for two real-world simulators of complex energy systems. Our experiments demonstrate the feasibility of designing language interfaces for real-world surrogate models at comparable accuracy to standard baselines. We qualitatively and quantitatively show that SysCaps unlock text-prompt-style surrogate modeling and new generalization abilities beyond what was previously possible. We will release the generated SysCaps datasets and our code to support follow-on studies.
Zero-Knowledge Zero-Shot Learning for Novel Visual Category Discovery
Feb 09, 2023



Generalized Zero-Shot Learning (GZSL) and Open-Set Recognition (OSR) are two mainstream settings that greatly extend conventional visual object recognition. However, the limitations of their problem settings are not negligible. The novel categories in GZSL require pre-defined semantic labels, making the problem setting less realistic; the oversimplified unknown class in OSR fails to explore the innate fine-grained and mixed structures of novel categories. In light of this, we are motivated to consider a new problem setting named Zero-Knowledge Zero-Shot Learning (ZK-ZSL) that assumes no prior knowledge of novel classes and aims to classify seen and unseen samples and recover semantic attributes of the fine-grained novel categories for further interpretation. To achieve this, we propose a novel framework that recovers the clustering structures of both seen and unseen categories where the seen class structures are guided by source labels. In addition, a structural alignment loss is designed to aid the semantic learning of unseen categories with their recovered structures. Experimental results demonstrate our method's superior performance in classification and semantic recovery on four benchmark datasets.