 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Inference over Wireless Channels with Feature Differential Privacy
Oct 25, 2024



Collaborative inference among multiple wireless edge devices has the potential to significantly enhance Artificial Intelligence (AI) applications, particularly for sensing and computer vision. This approach typically involves a three-stage process: a) data acquisition through sensing, b) feature extraction, and c) feature encoding for transmission. However, transmitting the extracted features poses a significant privacy risk, as sensitive personal data can be exposed during the process. To address this challenge, we propose a novel privacy-preserving collaborative inference mechanism, wherein each edge device in the network secures the privacy of extracted features before transmitting them to a central server for inference. Our approach is designed to achieve two primary objectives: 1) reducing communication overhead and 2) ensuring strict privacy guarantees during feature transmission, while maintaining effective inference performance. Additionally, we introduce an over-the-air pooling scheme specifically designed for classification tasks, which provides formal guarantees on the privacy of transmitted features and establishes a lower bound on classification accuracy.
Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts
Sep 24, 2024



Deep learning for time series forecasting has seen significant advancements over the past decades. However, despite the success of large-scale pre-training in language and vision domains, pre-trained time series models remain limited in scale and operate at a high cost, hindering the development of larger capable forecasting models in real-world applications. In response, we introduce Time-MoE, a scalable and unified architecture designed to pre-train larger, more capable forecasting foundation models while reducing inference costs. By leveraging a sparse mixture-of-experts (MoE) design, Time-MoE enhances computational efficiency by activating only a subset of networks for each prediction, reducing computational load while maintaining high model capacity. This allows Time-MoE to scale effectively without a corresponding increase in inference costs. Time-MoE comprises a family of decoder-only transformer models that operate in an auto-regressive manner and support flexible forecasting horizons with varying input context lengths. We pre-trained these models on our newly introduced large-scale data Time-300B, which spans over 9 domains and encompassing over 300 billion time points. For the first time, we scaled a time series foundation model up to 2.4 billion parameters, achieving significantly improved forecasting precision. Our results validate the applicability of scaling laws for training tokens and model size in the context of time series forecasting. Compared to dense models with the same number of activated parameters or equivalent computation budgets, our models consistently outperform them by large margin. These advancements position Time-MoE as a state-of-the-art solution for tackling real-world time series forecasting challenges with superior capability, efficiency, and flexibility.
Unlocking the Power of LSTM for Long Term Time Series Forecasting
Aug 19, 2024


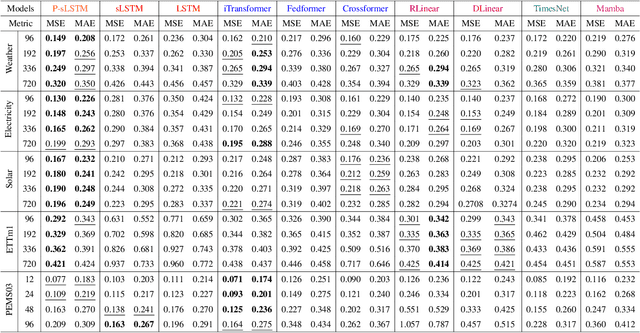
Traditional recurrent neural network architectures, such as long short-term memory neural networks (LSTM), have historically held a prominent role in time series forecasting (TSF) tasks. While the recently introduced sLSTM for Natural Language Processing (NLP) introduces exponential gating and memory mixing that are beneficial for long term sequential learning, its potential short memory issue is a barrier to applying sLSTM directly in TSF. To address this, we propose a simple yet efficient algorithm named P-sLSTM, which is built upon sLSTM by incorporating patching and channel independence. These modifications substantially enhance sLSTM's performance in TSF, achieving state-of-the-art results. Furthermore, we provide theoretical justifications for our design, and conduct extensive comparative and analytical experiments to fully validate the efficiency and superior performance of our model.
Large Language Models for Mobility in Transportation Systems: A Survey on Forecasting Tasks
May 03, 2024

Mobility analysis is a crucial element in the research area of transportation systems. Forecasting traffic information offers a viable solution to address the conflict between increasing transportation demands and the limitations of transportation infrastructure. Predicting human travel is significant in aiding various transportation and urban management tasks, such as taxi dispatch and urban planning. Machine learning and deep learning methods are favored for their flexibility and accuracy. Nowadays, with the advent of large language models (LLMs), many researchers have combined these models with previous techniques or applied LLMs to directly predict future traffic information and human travel behaviors. However, there is a lack of comprehensive studies on how LLMs can contribute to this field. This survey explores existing approaches using LLMs for mobility forecasting problems. We provide a literature review concerning the forecasting applications within transportation systems, elucidating how researchers utilize LLMs, showcasing recent state-of-the-art advancements, and identifying the challenges that must be overcome to fully leverage LLMs in this domain.
Foundation Models for Time Series Analysis: A Tutorial and Survey
Mar 21, 2024Time series analysis stands as a focal point within the data mining community, serving as a cornerstone for extracting valuable insights crucial to a myriad of real-world applications. Recent advancements in Foundation Models (FMs) have fundamentally reshaped the paradigm of model design for time series analysis, boosting various downstream tasks in practice. These innovative approaches often leverage pre-trained or fine-tuned FMs to harness generalized knowledge tailored specifically for time series analysis. In this survey, we aim to furnish a comprehensive and up-to-date overview of FMs for time series analysis. While prior surveys have predominantly focused on either the application or the pipeline aspects of FMs in time series analysis, they have often lacked an in-depth understanding of the underlying mechanisms that elucidate why and how FMs benefit time series analysis. To address this gap, our survey adopts a model-centric classification, delineating various pivotal elements of time-series FMs, including model architectures, pre-training techniques, adaptation methods, and data modalities. Overall, this survey serves to consolidate the latest advancements in FMs pertinent to time series analysis, accentuating their theoretical underpinnings, recent strides in development, and avenues for future research exploration.
ST-MLP: A Cascaded Spatio-Temporal Linear Framework with Channel-Independence Strategy for Traffic Forecasting
Aug 14, 2023The criticality of prompt and precise traffic forecasting in optimizing traffic flow management in Intelligent Transportation Systems (ITS) has drawn substantial scholarly focus. Spatio-Temporal Graph Neural Networks (STGNNs) have been lauded for their adaptability to road graph structures. Yet, current research on STGNNs architectures often prioritizes complex designs, leading to elevated computational burdens with only minor enhancements in accuracy. To address this issue, we propose ST-MLP, a concise spatio-temporal model solely based on cascaded Multi-Layer Perceptron (MLP) modules and linear layers. Specifically, we incorporate temporal information, spatial information and predefined graph structure with a successful implementation of the channel-independence strategy - an effective technique in time series forecasting. Empirical results demonstrate that ST-MLP outperforms state-of-the-art STGNNs and other models in terms of accuracy and computational efficiency. Our finding encourages further exploration of more concise and effective neural network architectures in the field of traffic forecasting.
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nov 27, 2022We propose an efficient design of Transformer-based models for multivariate time series forecasting and self-supervised representation learning. It is based on two key components: (i) segmentation of time series into subseries-level patches which are served as input tokens to Transformer; (ii) channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series. Patching design naturally has three-fold benefit: local semantic information is retained in the embedding; computation and memory usage of the attention maps are quadratically reduced given the same look-back window; and the model can attend longer history. Our channel-independent patch time series Transformer (PatchTST) can improve the long-term forecasting accuracy significantly when compared with that of SOTA Transformer-based models. We also apply our model to self-supervised pre-training tasks and attain excellent fine-tuning performance, which outperforms supervised training on large datasets. Transferring of masked pre-trained representation on one dataset to others also produces SOTA forecasting accuracy. Code is available at: https://github.com/yuqinie98/PatchTST.
Neural network is heterogeneous: Phase matters more
Nov 27, 2021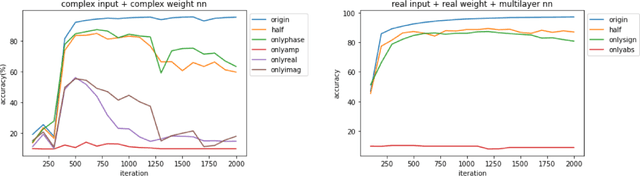
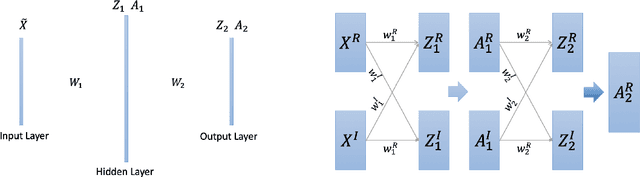
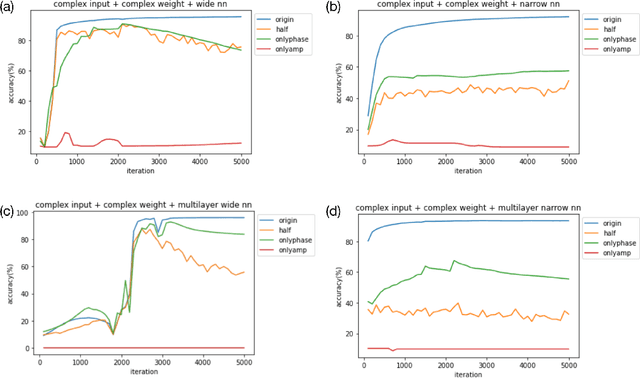

We find a heterogeneity in both complex and real valued neural networks with the insight from wave optics, claiming a much more important role of phase than its amplitude counterpart in the weight matrix. In complex-valued neural networks, we show that among different types of pruning, the weight matrix with only phase information preserved achieves the best accuracy, which holds robustly under various settings of depth and width. The conclusion can be generalized to real-valued neural networks, where signs take the place of phases. These inspiring findings enrich the techniques of network pruning and binary computation.