 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrusted Source Alignment in Large Language Models
Nov 12, 2023



Large language models (LLMs) are trained on web-scale corpora that inevitably include contradictory factual information from sources of varying reliability. In this paper, we propose measuring an LLM property called trusted source alignment (TSA): the model's propensity to align with content produced by trusted publishers in the face of uncertainty or controversy. We present FactCheckQA, a TSA evaluation dataset based on a corpus of fact checking articles. We describe a simple protocol for evaluating TSA and offer a detailed analysis of design considerations including response extraction, claim contextualization, and bias in prompt formulation. Applying the protocol to PaLM-2, we find that as we scale up the model size, the model performance on FactCheckQA improves from near-random to up to 80% balanced accuracy in aligning with trusted sources.
SMILE: Evaluation and Domain Adaptation for Social Media Language Understanding
Jun 30, 2023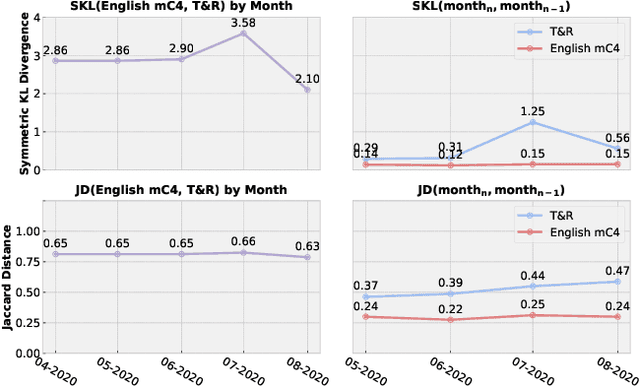



We study the ability of transformer-based language models (LMs) to understand social media language. Social media (SM) language is distinct from standard written language, yet existing benchmarks fall short of capturing LM performance in this socially, economically, and politically important domain. We quantify the degree to which social media language differs from conventional language and conclude that the difference is significant both in terms of token distribution and rate of linguistic shift. Next, we introduce a new benchmark for Social MedIa Language Evaluation (SMILE) that covers four SM platforms and eleven tasks. Finally, we show that learning a tokenizer and pretraining on a mix of social media and conventional language yields an LM that outperforms the best similar-sized alternative by 4.2 points on the overall SMILE score.
Temporal Poisson Square Root Graphical Models
May 12, 2020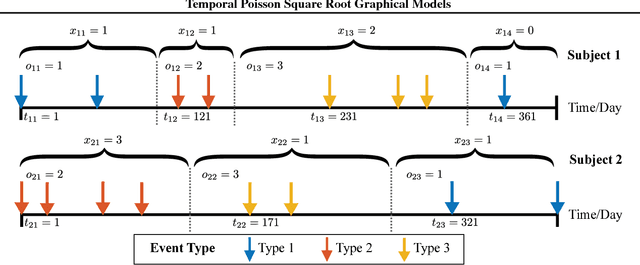
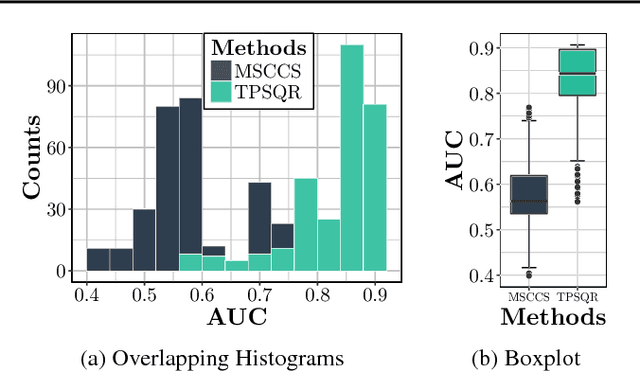
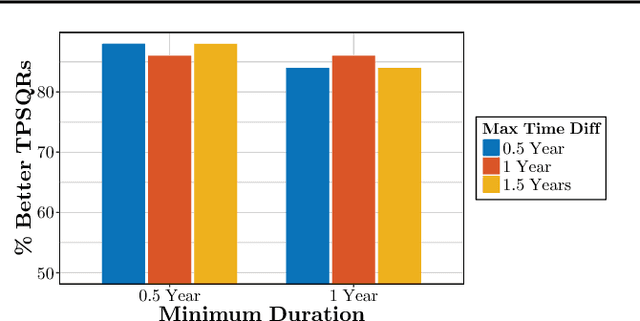
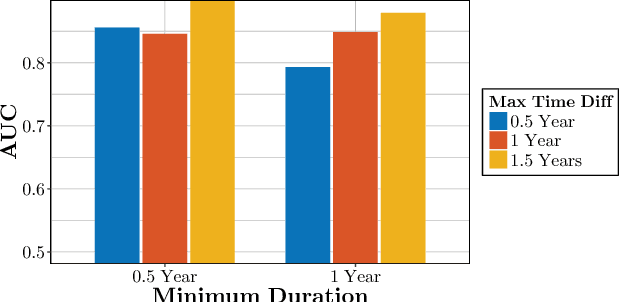
We propose temporal Poisson square root graphical models (TPSQRs), a generalization of Poisson square root graphical models (PSQRs) specifically designed for modeling longitudinal event data. By estimating the temporal relationships for all possible pairs of event types, TPSQRs can offer a holistic perspective about whether the occurrences of any given event type could excite or inhibit any other type. A TPSQR is learned by estimating a collection of interrelated PSQRs that share the same template parameterization. These PSQRs are estimated jointly in a pseudo-likelihood fashion, where Poisson pseudo-likelihood is used to approximate the original more computationally-intensive pseudo-likelihood problem stemming from PSQRs. Theoretically, we demonstrate that under mild assumptions, the Poisson pseudo-likelihood approximation is sparsistent for recovering the underlying PSQR. Empirically, we learn TPSQRs from Marshfield Clinic electronic health records (EHRs) with millions of drug prescription and condition diagnosis events, for adverse drug reaction (ADR) detection. Experimental results demonstrate that the learned TPSQRs can recover ADR signals from the EHR effectively and efficiently.
Stochastic Learning for Sparse Discrete Markov Random Fields with Controlled Gradient Approximation Error
May 12, 2020
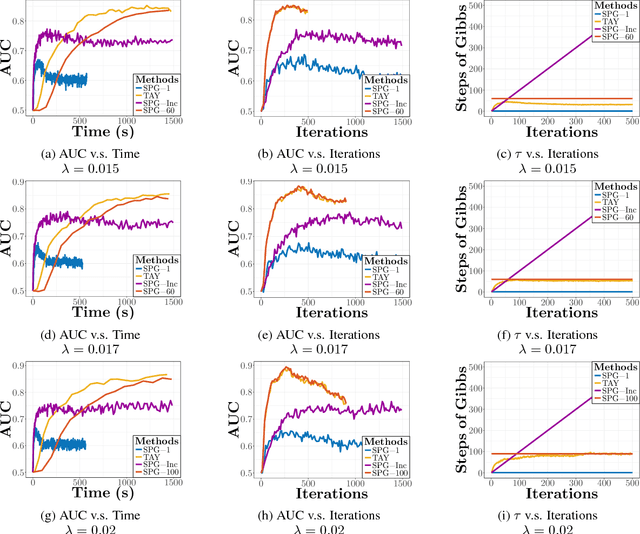
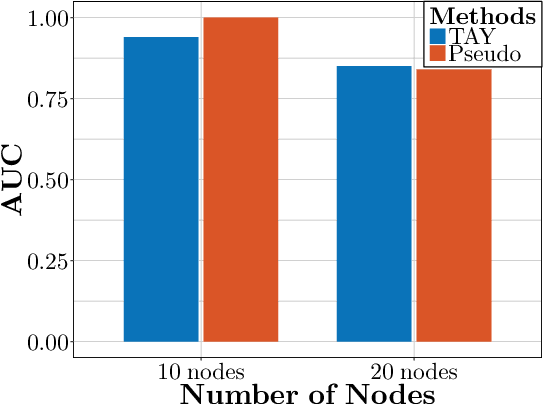
We study the $L_1$-regularized maximum likelihood estimator/estimation (MLE) problem for discrete Markov random fields (MRFs), where efficient and scalable learning requires both sparse regularization and approximate inference. To address these challenges, we consider a stochastic learning framework called stochastic proximal gradient (SPG; Honorio 2012a, Atchade et al. 2014,Miasojedow and Rejchel 2016). SPG is an inexact proximal gradient algorithm [Schmidtet al., 2011], whose inexactness stems from the stochastic oracle (Gibbs sampling) for gradient approximation - exact gradient evaluation is infeasible in general due to the NP-hard inference problem for discrete MRFs [Koller and Friedman, 2009]. Theoretically, we provide novel verifiable bounds to inspect and control the quality of gradient approximation. Empirically, we propose the tighten asymptotically (TAY) learning strategy based on the verifiable bounds to boost the performance of SPG.
Ivy: Instrumental Variable Synthesis for Causal Inference
Apr 11, 2020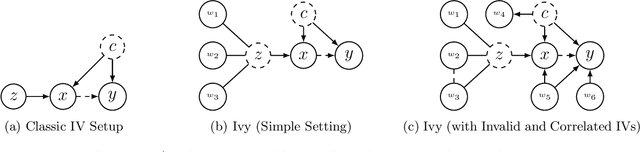
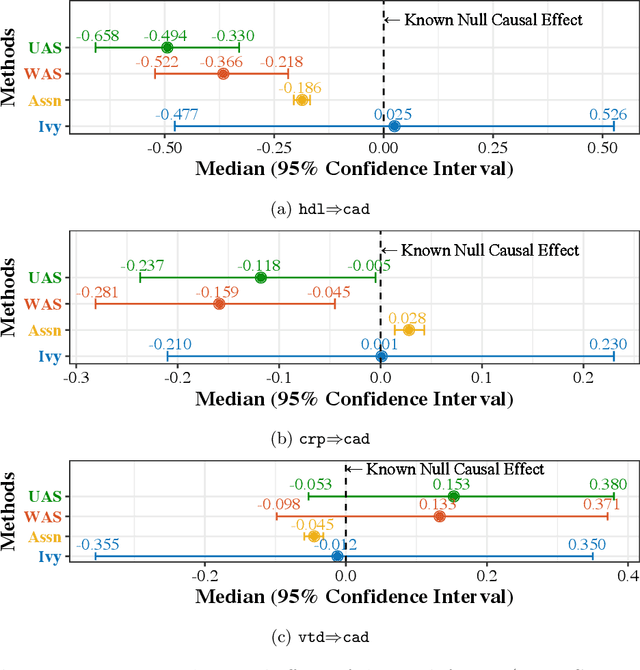
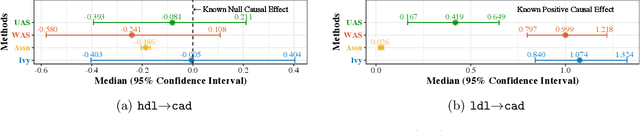
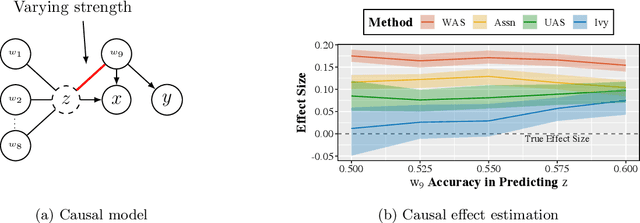
A popular way to estimate the causal effect of a variable x on y from observational data is to use an instrumental variable (IV): a third variable z that affects y only through x. The more strongly z is associated with x, the more reliable the estimate is, but such strong IVs are difficult to find. Instead, practitioners combine more commonly available IV candidates---which are not necessarily strong, or even valid, IVs---into a single "summary" that is plugged into causal effect estimators in place of an IV. In genetic epidemiology, such approaches are known as allele scores. Allele scores require strong assumptions---independence and validity of all IV candidates---for the resulting estimate to be reliable. To relax these assumptions, we propose Ivy, a new method to combine IV candidates that can handle correlated and invalid IV candidates in a robust manner. Theoretically, we characterize this robustness, its limits, and its impact on the resulting causal estimates. Empirically, Ivy can correctly identify the directionality of known relationships and is robust against false discovery (median effect size <= 0.025) on three real-world datasets with no causal effects, while allele scores return more biased estimates (median effect size >= 0.118).
High-Throughput Machine Learning from Electronic Health Records
Jul 03, 2019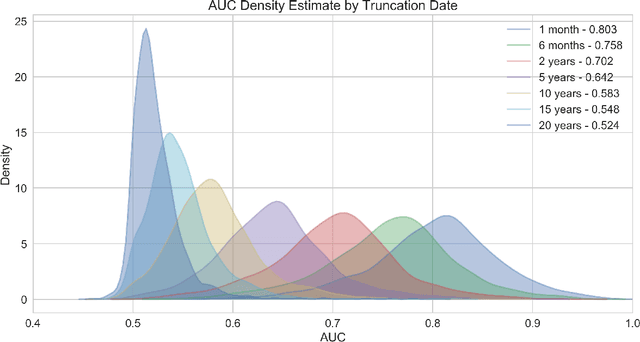
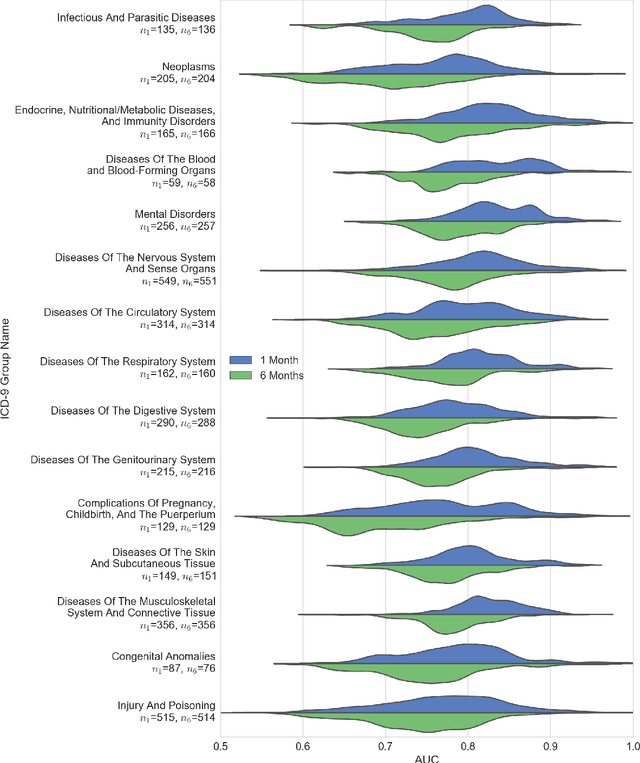

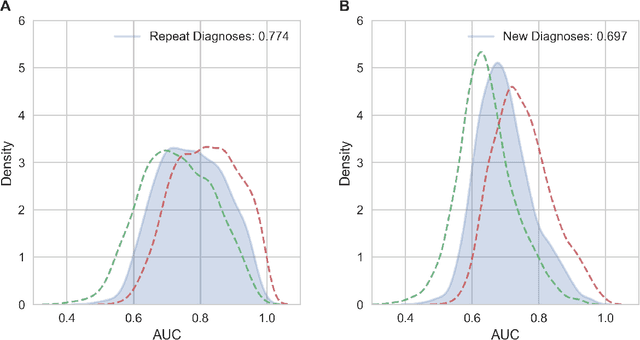
The widespread digitization of patient data via electronic health records (EHRs) has created an unprecedented opportunity to use machine learning algorithms to better predict disease risk at the patient level. Although predictive models have previously been constructed for a few important diseases, such as breast cancer and myocardial infarction, we currently know very little about how accurately the risk for most diseases or events can be predicted, and how far in advance. Machine learning algorithms use training data rather than preprogrammed rules to make predictions and are well suited for the complex task of disease prediction. Although there are thousands of conditions and illnesses patients can encounter, no prior research simultaneously predicts risks for thousands of diagnosis codes and thereby establishes a comprehensive patient risk profile. Here we show that such pandiagnostic prediction is possible with a high level of performance across diagnosis codes. For the tasks of predicting diagnosis risks both 1 and 6 months in advance, we achieve average areas under the receiver operating characteristic curve (AUCs) of 0.803 and 0.758, respectively, across thousands of prediction tasks. Finally, our research contributes a new clinical prediction dataset in which researchers can explore how well a diagnosis can be predicted and what health factors are most useful for prediction. For the first time, we can get a much more complete picture of how well risks for thousands of different diagnosis codes can be predicted.
An Efficient Pseudo-likelihood Method for Sparse Binary Pairwise Markov Network Estimation
Apr 07, 2017



The pseudo-likelihood method is one of the most popular algorithms for learning sparse binary pairwise Markov networks. In this paper, we formulate the $L_1$ regularized pseudo-likelihood problem as a sparse multiple logistic regression problem. In this way, many insights and optimization procedures for sparse logistic regression can be applied to the learning of discrete Markov networks. Specifically, we use the coordinate descent algorithm for generalized linear models with convex penalties, combined with strong screening rules, to solve the pseudo-likelihood problem with $L_1$ regularization. Therefore a substantial speedup without losing any accuracy can be achieved. Furthermore, this method is more stable than the node-wise logistic regression approach on unbalanced high-dimensional data when penalized by small regularization parameters. Thorough numerical experiments on simulated data and real world data demonstrate the advantages of the proposed method.
Computational Drug Repositioning Using Continuous Self-controlled Case Series
Apr 20, 2016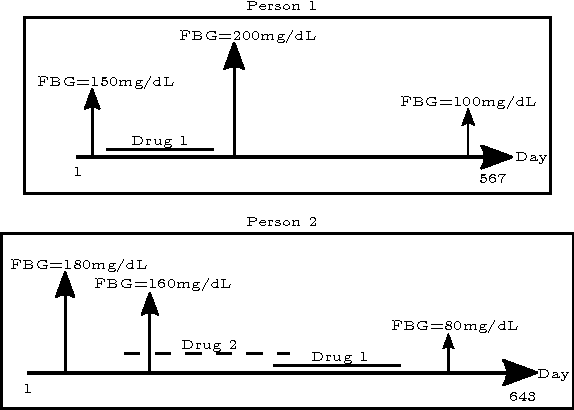
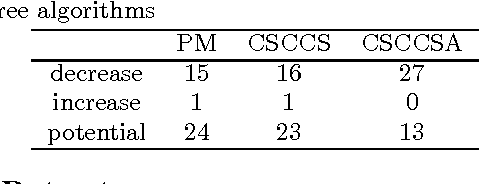
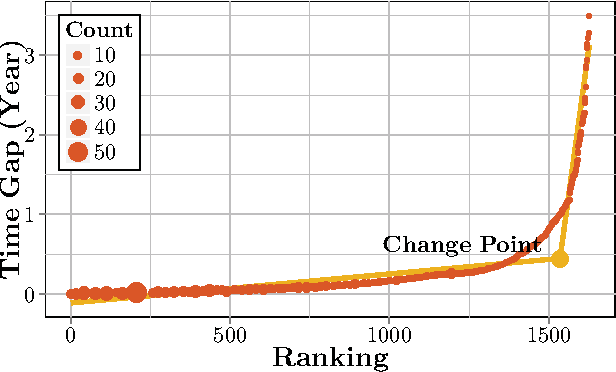
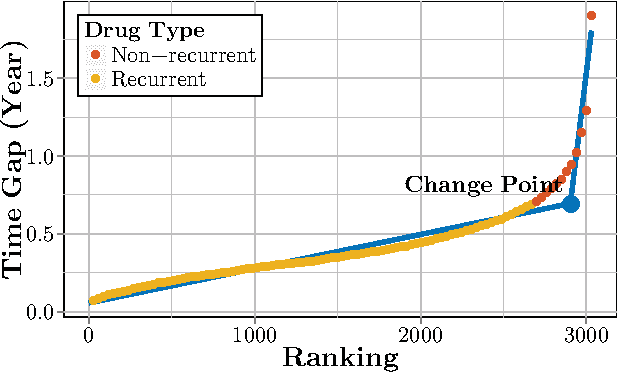
Computational Drug Repositioning (CDR) is the task of discovering potential new indications for existing drugs by mining large-scale heterogeneous drug-related data sources. Leveraging the patient-level temporal ordering information between numeric physiological measurements and various drug prescriptions provided in Electronic Health Records (EHRs), we propose a Continuous Self-controlled Case Series (CSCCS) model for CDR. As an initial evaluation, we look for drugs that can control Fasting Blood Glucose (FBG) level in our experiments. Applying CSCCS to the Marshfield Clinic EHR, well-known drugs that are indicated for controlling blood glucose level are rediscovered. Furthermore, some drugs with recent literature support for the potential effect of blood glucose level control are also identified.