 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Throughput Machine Learning from Electronic Health Records
Paper and Code
Jul 03, 2019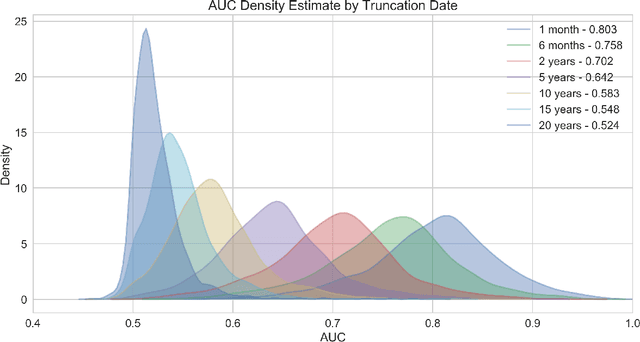
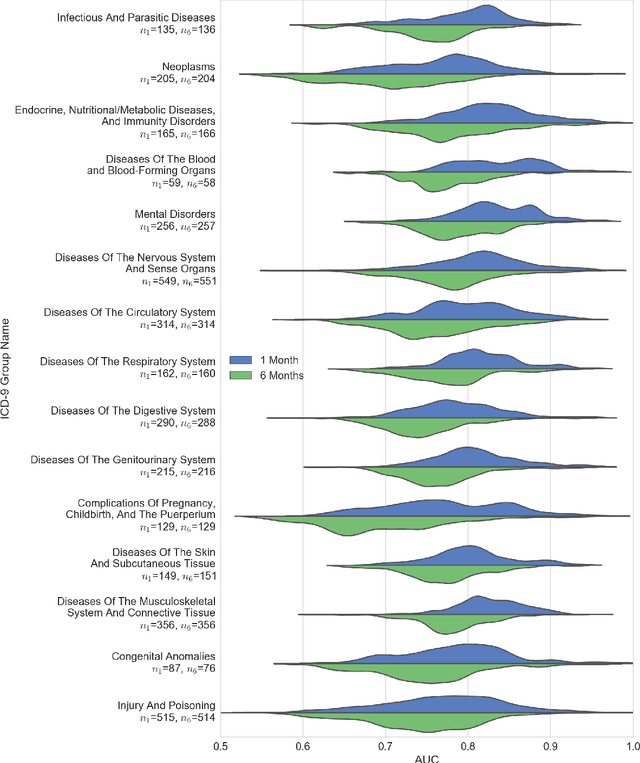

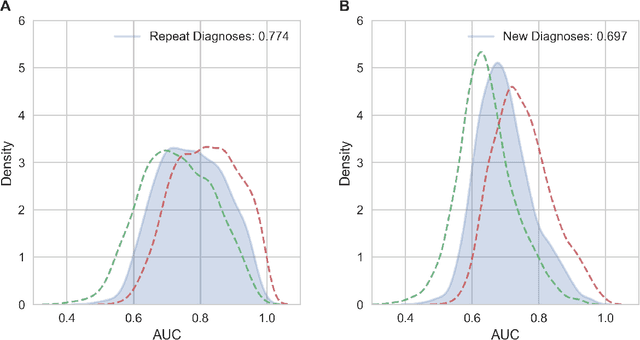
The widespread digitization of patient data via electronic health records (EHRs) has created an unprecedented opportunity to use machine learning algorithms to better predict disease risk at the patient level. Although predictive models have previously been constructed for a few important diseases, such as breast cancer and myocardial infarction, we currently know very little about how accurately the risk for most diseases or events can be predicted, and how far in advance. Machine learning algorithms use training data rather than preprogrammed rules to make predictions and are well suited for the complex task of disease prediction. Although there are thousands of conditions and illnesses patients can encounter, no prior research simultaneously predicts risks for thousands of diagnosis codes and thereby establishes a comprehensive patient risk profile. Here we show that such pandiagnostic prediction is possible with a high level of performance across diagnosis codes. For the tasks of predicting diagnosis risks both 1 and 6 months in advance, we achieve average areas under the receiver operating characteristic curve (AUCs) of 0.803 and 0.758, respectively, across thousands of prediction tasks. Finally, our research contributes a new clinical prediction dataset in which researchers can explore how well a diagnosis can be predicted and what health factors are most useful for prediction. For the first time, we can get a much more complete picture of how well risks for thousands of different diagnosis codes can be predicted.