 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScratchpad Patching: Decoupling Compute from Patch Size in Byte-Level Language Models
May 10, 2026Tokenizer-free language models eliminate the tokenizer step of the language modeling pipeline by operating directly on bytes; patch-based variants further aggregate contiguous byte spans into patches for efficiency. However, the average patch size chosen at the model design stage governs a tight trade-off: larger patches reduce compute and KV-cache footprint, but degrade modeling quality. We trace this trade-off to patch lag: until a patch is fully observed, byte predictions within it must rely on a stale representation from the previous patch to preserve causality; this lag widens as patches grow larger. We introduce Scratchpad Patching (SP), which inserts transient scratchpads inside each patch to aggregate the bytes seen so far and refresh patch-level context for subsequent predictions. SP triggers scratchpads using next-byte prediction entropy, selectively allocating compute to information-dense regions and enabling post-hoc adjustment of inference-time compute. Across experiments on natural language and code, SP improves model quality at the same patch size; for example, even at $16$ bytes per patch, SP-augmented models match or closely approach the byte-level baseline on downstream evaluations while using a $16\times$ smaller KV cache over patches and $3$-$4\times$ less inference compute.
Trusted Source Alignment in Large Language Models
Nov 12, 2023



Large language models (LLMs) are trained on web-scale corpora that inevitably include contradictory factual information from sources of varying reliability. In this paper, we propose measuring an LLM property called trusted source alignment (TSA): the model's propensity to align with content produced by trusted publishers in the face of uncertainty or controversy. We present FactCheckQA, a TSA evaluation dataset based on a corpus of fact checking articles. We describe a simple protocol for evaluating TSA and offer a detailed analysis of design considerations including response extraction, claim contextualization, and bias in prompt formulation. Applying the protocol to PaLM-2, we find that as we scale up the model size, the model performance on FactCheckQA improves from near-random to up to 80% balanced accuracy in aligning with trusted sources.
SMILE: Evaluation and Domain Adaptation for Social Media Language Understanding
Jun 30, 2023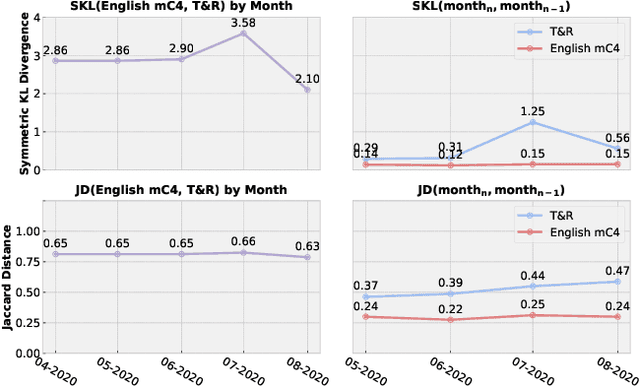



We study the ability of transformer-based language models (LMs) to understand social media language. Social media (SM) language is distinct from standard written language, yet existing benchmarks fall short of capturing LM performance in this socially, economically, and politically important domain. We quantify the degree to which social media language differs from conventional language and conclude that the difference is significant both in terms of token distribution and rate of linguistic shift. Next, we introduce a new benchmark for Social MedIa Language Evaluation (SMILE) that covers four SM platforms and eleven tasks. Finally, we show that learning a tokenizer and pretraining on a mix of social media and conventional language yields an LM that outperforms the best similar-sized alternative by 4.2 points on the overall SMILE score.
What do LLMs Know about Financial Markets? A Case Study on Reddit Market Sentiment Analysis
Dec 21, 2022



Market sentiment analysis on social media content requires knowledge of both financial markets and social media jargon, which makes it a challenging task for human raters. The resulting lack of high-quality labeled data stands in the way of conventional supervised learning methods. Instead, we approach this problem using semi-supervised learning with a large language model (LLM). Our pipeline generates weak financial sentiment labels for Reddit posts with an LLM and then uses that data to train a small model that can be served in production. We find that prompting the LLM to produce Chain-of-Thought summaries and forcing it through several reasoning paths helps generate more stable and accurate labels, while using a regression loss further improves distillation quality. With only a handful of prompts, the final model performs on par with existing supervised models. Though production applications of our model are limited by ethical considerations, the model's competitive performance points to the great potential of using LLMs for tasks that otherwise require skill-intensive annotation.