 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMQA: Semi-Extractive Multi-Source Question Answering
Nov 08, 2023Recently proposed long-form question answering (QA) systems, supported by large language models (LLMs), have shown promising capabilities. Yet, attributing and verifying their generated abstractive answers can be difficult, and automatically evaluating their accuracy remains an ongoing challenge. In this work, we introduce a new QA task for answering multi-answer questions by summarizing multiple diverse sources in a semi-extractive fashion. Specifically, Semi-extractive Multi-source QA (SEMQA) requires models to output a comprehensive answer, while mixing factual quoted spans -- copied verbatim from given input sources -- and non-factual free-text connectors that glue these spans together into a single cohesive passage. This setting bridges the gap between the outputs of well-grounded but constrained extractive QA systems and more fluent but harder to attribute fully abstractive answers. Particularly, it enables a new mode for language models that leverages their advanced language generation capabilities, while also producing fine in-line attributions by-design that are easy to verify, interpret, and evaluate. To study this task, we create the first dataset of this kind, QuoteSum, with human-written semi-extractive answers to natural and generated questions, and define text-based evaluation metrics. Experimenting with several LLMs in various settings, we find this task to be surprisingly challenging, demonstrating the importance of QuoteSum for developing and studying such consolidation capabilities.
SDOH-NLI: a Dataset for Inferring Social Determinants of Health from Clinical Notes
Oct 27, 2023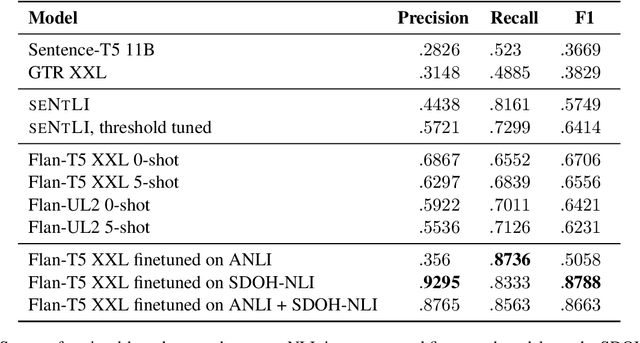
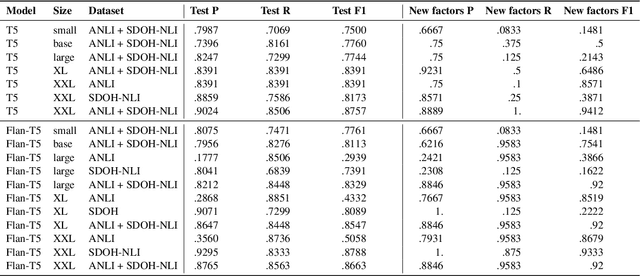
Social and behavioral determinants of health (SDOH) play a significant role in shaping health outcomes, and extracting these determinants from clinical notes is a first step to help healthcare providers systematically identify opportunities to provide appropriate care and address disparities. Progress on using NLP methods for this task has been hindered by the lack of high-quality publicly available labeled data, largely due to the privacy and regulatory constraints on the use of real patients' information. This paper introduces a new dataset, SDOH-NLI, that is based on publicly available notes and which we release publicly. We formulate SDOH extraction as a natural language inference (NLI) task, and provide binary textual entailment labels obtained from human raters for a cross product of a set of social history snippets as premises and SDOH factors as hypotheses. Our dataset differs from standard NLI benchmarks in that our premises and hypotheses are obtained independently. We evaluate both "off-the-shelf" entailment models as well as models fine-tuned on our data, and highlight the ways in which our dataset appears more challenging than commonly used NLI datasets.
How Does Generative Retrieval Scale to Millions of Passages?
May 19, 2023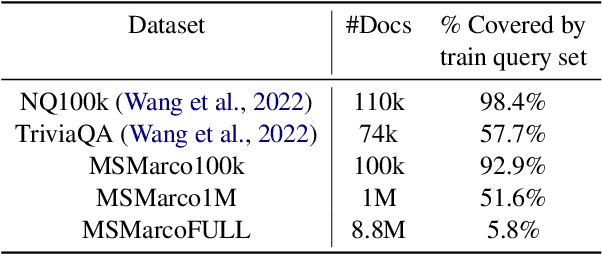
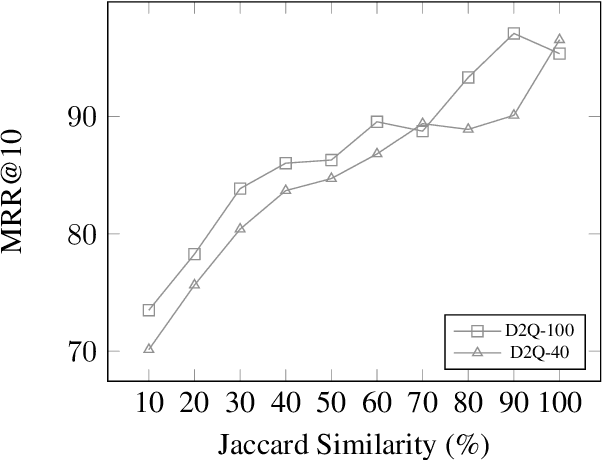
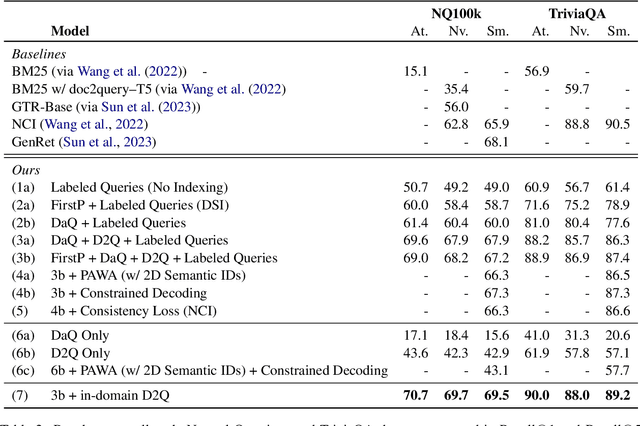
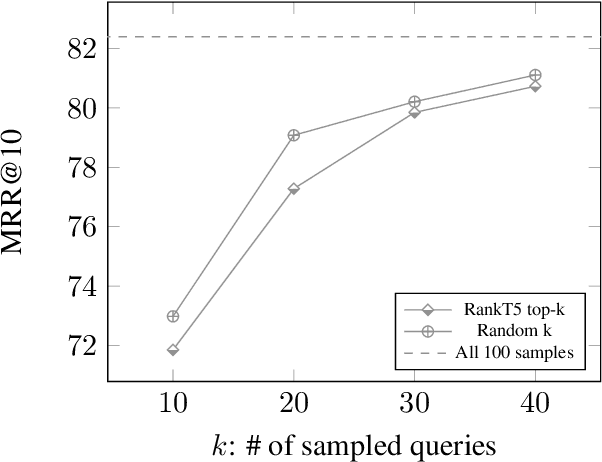
Popularized by the Differentiable Search Index, the emerging paradigm of generative retrieval re-frames the classic information retrieval problem into a sequence-to-sequence modeling task, forgoing external indices and encoding an entire document corpus within a single Transformer. Although many different approaches have been proposed to improve the effectiveness of generative retrieval, they have only been evaluated on document corpora on the order of 100k in size. We conduct the first empirical study of generative retrieval techniques across various corpus scales, ultimately scaling up to the entire MS MARCO passage ranking task with a corpus of 8.8M passages and evaluating model sizes up to 11B parameters. We uncover several findings about scaling generative retrieval to millions of passages; notably, the central importance of using synthetic queries as document representations during indexing, the ineffectiveness of existing proposed architecture modifications when accounting for compute cost, and the limits of naively scaling model parameters with respect to retrieval performance. While we find that generative retrieval is competitive with state-of-the-art dual encoders on small corpora, scaling to millions of passages remains an important and unsolved challenge. We believe these findings will be valuable for the community to clarify the current state of generative retrieval, highlight the unique challenges, and inspire new research directions.
Instability in clinical risk stratification models using deep learning
Nov 20, 2022



While it has been well known in the ML community that deep learning models suffer from instability, the consequences for healthcare deployments are under characterised. We study the stability of different model architectures trained on electronic health records, using a set of outpatient prediction tasks as a case study. We show that repeated training runs of the same deep learning model on the same training data can result in significantly different outcomes at a patient level even though global performance metrics remain stable. We propose two stability metrics for measuring the effect of randomness of model training, as well as mitigation strategies for improving model stability.
All Birds with One Stone: Multi-task Text Classification for Efficient Inference with One Forward Pass
May 22, 2022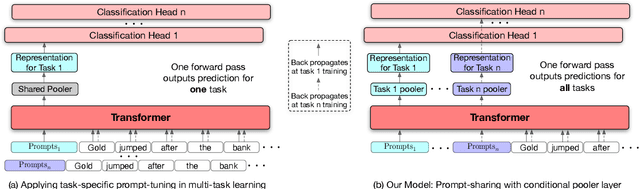
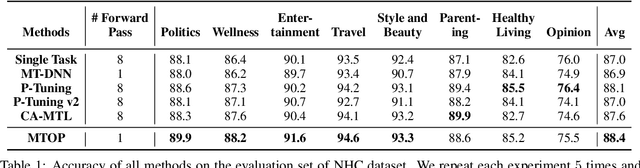
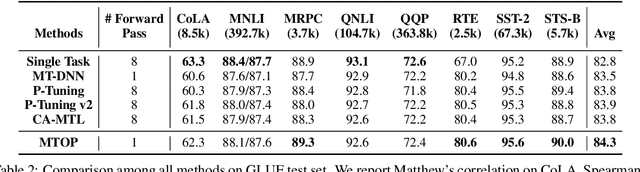
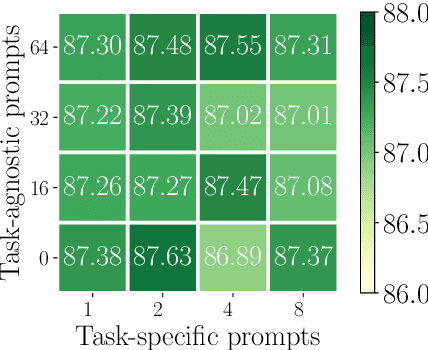
Multi-Task Learning (MTL) models have shown their robustness, effectiveness, and efficiency for transferring learned knowledge across tasks. In real industrial applications such as web content classification, multiple classification tasks are predicted from the same input text such as a web article. However, at the serving time, the existing multitask transformer models such as prompt or adaptor based approaches need to conduct N forward passes for N tasks with O(N) computation cost. To tackle this problem, we propose a scalable method that can achieve stronger performance with close to O(1) computation cost via only one forward pass. To illustrate real application usage, we release a multitask dataset on news topic and style classification. Our experiments show that our proposed method outperforms strong baselines on both the GLUE benchmark and our news dataset. Our code and dataset are publicly available at https://bit.ly/mtop-code.
AgreeSum: Agreement-Oriented Multi-Document Summarization
Jun 04, 2021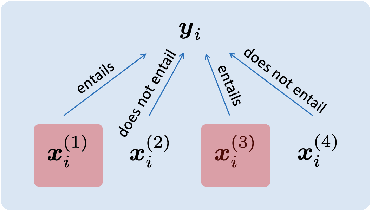

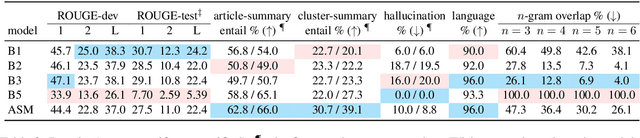
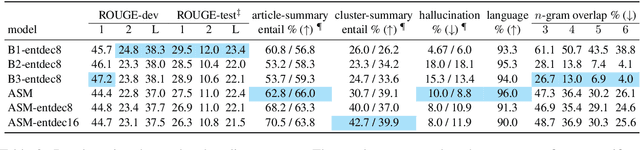
We aim to renew interest in a particular multi-document summarization (MDS) task which we call AgreeSum: agreement-oriented multi-document summarization. Given a cluster of articles, the goal is to provide abstractive summaries that represent information common and faithful to all input articles. Given the lack of existing datasets, we create a dataset for AgreeSum, and provide annotations on article-summary entailment relations for a subset of the clusters in the dataset. We aim to create strong baselines for the task by applying the top-performing pretrained single-document summarization model PEGASUS onto AgreeSum, leveraging both annotated clusters by supervised losses, and unannotated clusters by T5-based entailment-related and language-related losses. Compared to other baselines, both automatic evaluation and human evaluation show better article-summary and cluster-summary entailment in generated summaries. On a separate note, we hope that our article-summary entailment annotations contribute to the community's effort in improving abstractive summarization faithfulness.
Quiz-Style Question Generation for News Stories
Feb 18, 2021
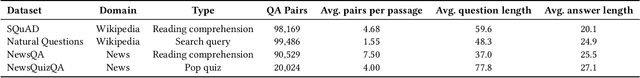


A large majority of American adults get at least some of their news from the Internet. Even though many online news products have the goal of informing their users about the news, they lack scalable and reliable tools for measuring how well they are achieving this goal, and therefore have to resort to noisy proxy metrics (e.g., click-through rates or reading time) to track their performance. As a first step towards measuring news informedness at a scale, we study the problem of quiz-style multiple-choice question generation, which may be used to survey users about their knowledge of recent news. In particular, we formulate the problem as two sequence-to-sequence tasks: question-answer generation (QAG) and distractor, or incorrect answer, generation (DG). We introduce NewsQuizQA, the first dataset intended for quiz-style question-answer generation, containing 20K human written question-answer pairs from 5K news article summaries. Using this dataset, we propose a series of novel techniques for applying large pre-trained Transformer encoder-decoder models, namely PEGASUS and T5, to the tasks of question-answer generation and distractor generation. We show that our models outperform strong baselines using both automated metrics and human raters. We provide a case study of running weekly quizzes on real-world users via the Google Surveys platform over the course of two months. We found that users generally found the automatically generated questions to be educational and enjoyable. Finally, to serve the research community, we are releasing the NewsQuizQA dataset.