 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDOH-NLI: a Dataset for Inferring Social Determinants of Health from Clinical Notes
Oct 27, 2023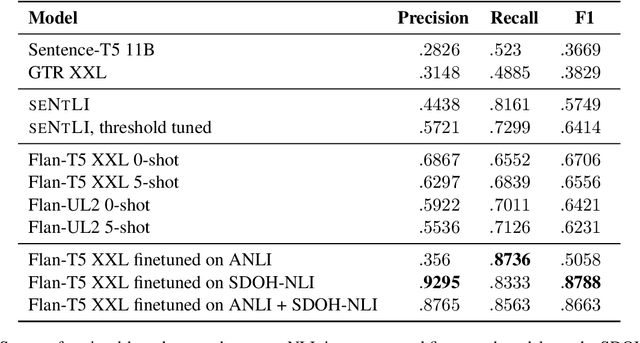
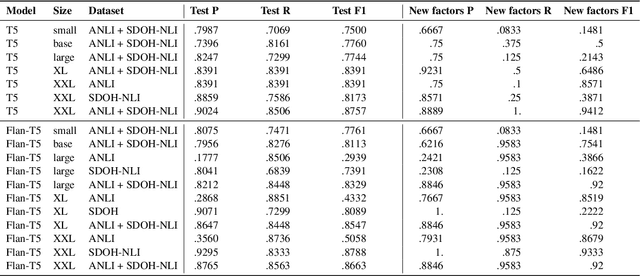
Social and behavioral determinants of health (SDOH) play a significant role in shaping health outcomes, and extracting these determinants from clinical notes is a first step to help healthcare providers systematically identify opportunities to provide appropriate care and address disparities. Progress on using NLP methods for this task has been hindered by the lack of high-quality publicly available labeled data, largely due to the privacy and regulatory constraints on the use of real patients' information. This paper introduces a new dataset, SDOH-NLI, that is based on publicly available notes and which we release publicly. We formulate SDOH extraction as a natural language inference (NLI) task, and provide binary textual entailment labels obtained from human raters for a cross product of a set of social history snippets as premises and SDOH factors as hypotheses. Our dataset differs from standard NLI benchmarks in that our premises and hypotheses are obtained independently. We evaluate both "off-the-shelf" entailment models as well as models fine-tuned on our data, and highlight the ways in which our dataset appears more challenging than commonly used NLI datasets.
Instability in clinical risk stratification models using deep learning
Nov 20, 2022



While it has been well known in the ML community that deep learning models suffer from instability, the consequences for healthcare deployments are under characterised. We study the stability of different model architectures trained on electronic health records, using a set of outpatient prediction tasks as a case study. We show that repeated training runs of the same deep learning model on the same training data can result in significantly different outcomes at a patient level even though global performance metrics remain stable. We propose two stability metrics for measuring the effect of randomness of model training, as well as mitigation strategies for improving model stability.
Machine learning for dynamically predicting the onset of renal replacement therapy in chronic kidney disease patients using claims data
Sep 03, 2022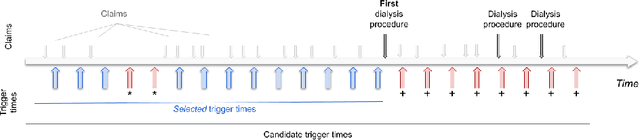
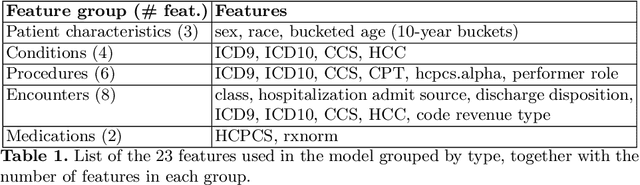
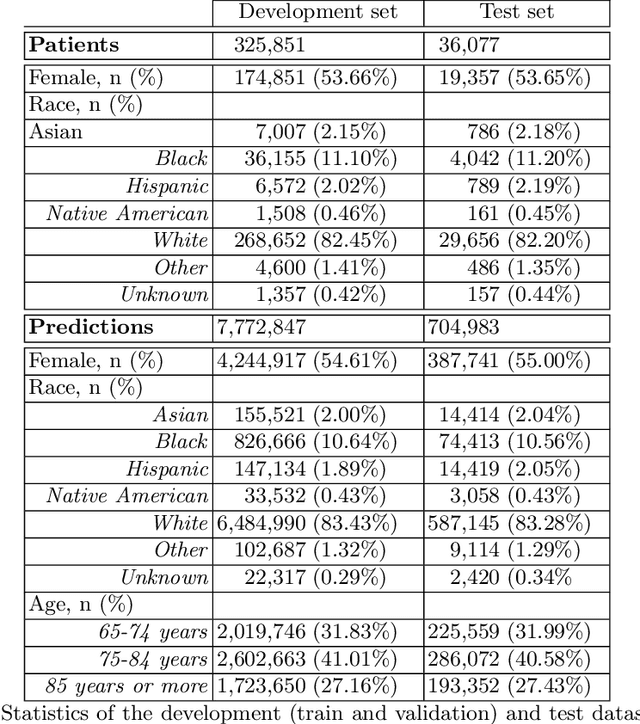
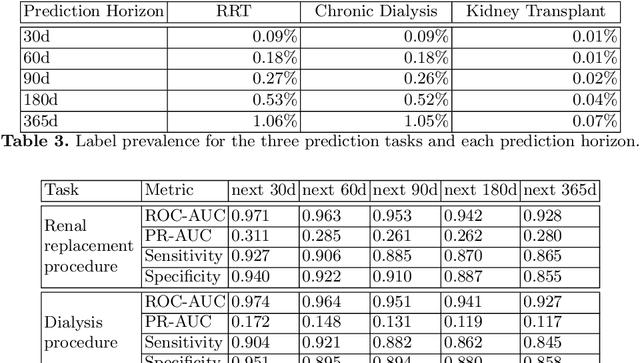
Chronic kidney disease (CKD) represents a slowly progressive disorder that can eventually require renal replacement therapy (RRT) including dialysis or renal transplantation. Early identification of patients who will require RRT (as much as 1 year in advance) improves patient outcomes, for example by allowing higher-quality vascular access for dialysis. Therefore, early recognition of the need for RRT by care teams is key to successfully managing the disease. Unfortunately, there is currently no commonly used predictive tool for RRT initiation. In this work, we present a machine learning model that dynamically identifies CKD patients at risk of requiring RRT up to one year in advance using only claims data. To evaluate the model, we studied approximately 3 million Medicare beneficiaries for which we made over 8 million predictions. We showed that the model can identify at risk patients with over 90% sensitivity and specificity. Although additional work is required before this approach is ready for clinical use, this study provides a basis for a screening tool to identify patients at risk within a time window that enables early proactive interventions intended to improve RRT outcomes.
Boosting the interpretability of clinical risk scores with intervention predictions
Jul 06, 2022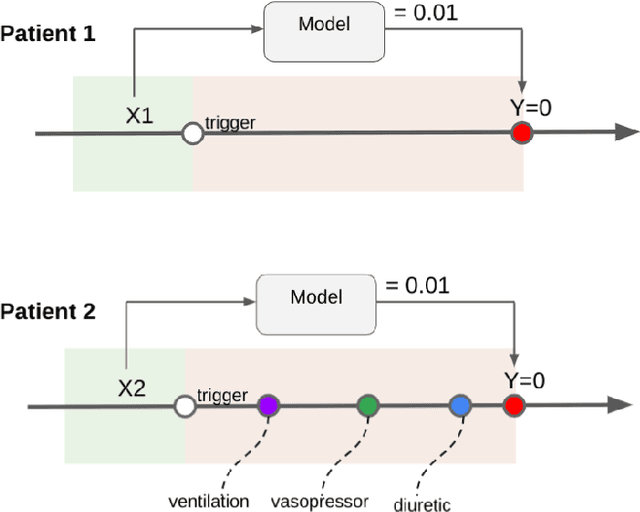
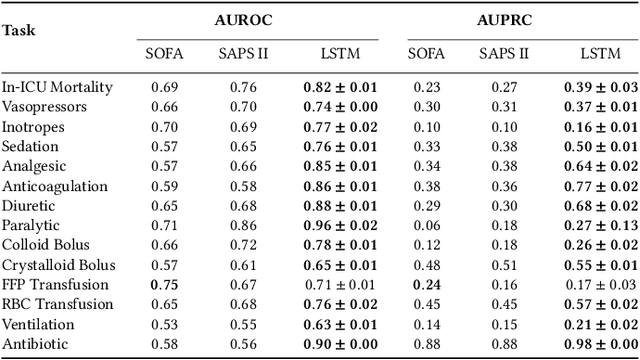
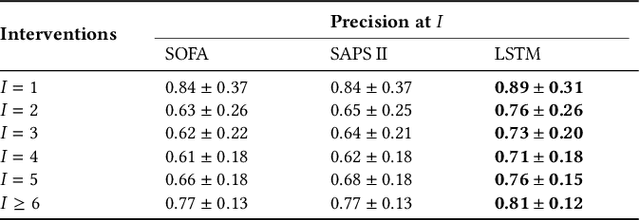
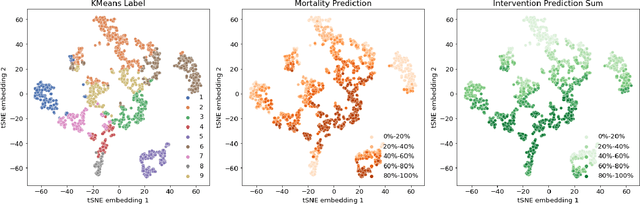
Machine learning systems show significant promise for forecasting patient adverse events via risk scores. However, these risk scores implicitly encode assumptions about future interventions that the patient is likely to receive, based on the intervention policy present in the training data. Without this important context, predictions from such systems are less interpretable for clinicians. We propose a joint model of intervention policy and adverse event risk as a means to explicitly communicate the model's assumptions about future interventions. We develop such an intervention policy model on MIMIC-III, a real world de-identified ICU dataset, and discuss some use cases that highlight the utility of this approach. We show how combining typical risk scores, such as the likelihood of mortality, with future intervention probability scores leads to more interpretable clinical predictions.