 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Partial Disentanglement via Mechanism Sparsity: Sparse Actions, Interventions and Sparse Temporal Dependencies
Jan 10, 2024This work introduces a novel principle for disentanglement we call mechanism sparsity regularization, which applies when the latent factors of interest depend sparsely on observed auxiliary variables and/or past latent factors. We propose a representation learning method that induces disentanglement by simultaneously learning the latent factors and the sparse causal graphical model that explains them. We develop a nonparametric identifiability theory that formalizes this principle and shows that the latent factors can be recovered by regularizing the learned causal graph to be sparse. More precisely, we show identifiablity up to a novel equivalence relation we call "consistency", which allows some latent factors to remain entangled (hence the term partial disentanglement). To describe the structure of this entanglement, we introduce the notions of entanglement graphs and graph preserving functions. We further provide a graphical criterion which guarantees complete disentanglement, that is identifiability up to permutations and element-wise transformations. We demonstrate the scope of the mechanism sparsity principle as well as the assumptions it relies on with several worked out examples. For instance, the framework shows how one can leverage multi-node interventions with unknown targets on the latent factors to disentangle them. We further draw connections between our nonparametric results and the now popular exponential family assumption. Lastly, we propose an estimation procedure based on variational autoencoders and a sparsity constraint and demonstrate it on various synthetic datasets. This work is meant to be a significantly extended version of Lachapelle et al. (2022).
Discovering Latent Causal Variables via Mechanism Sparsity: A New Principle for Nonlinear ICA
Jul 21, 2021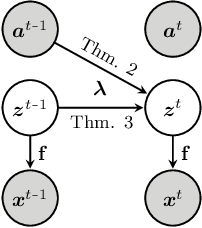
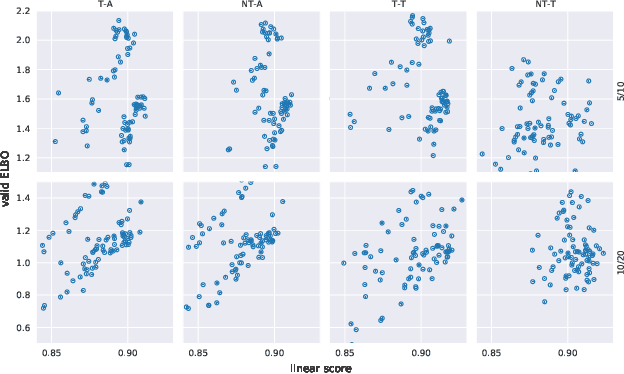
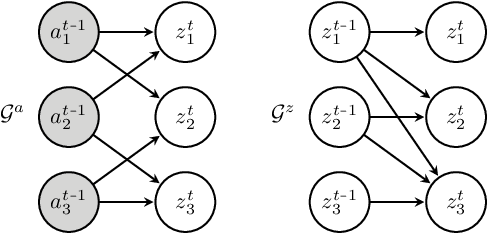
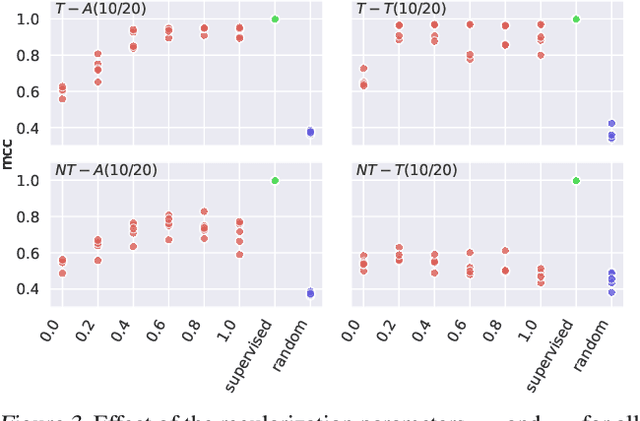
It can be argued that finding an interpretable low-dimensional representation of a potentially high-dimensional phenomenon is central to the scientific enterprise. Independent component analysis (ICA) refers to an ensemble of methods which formalize this goal and provide estimation procedure for practical application. This work proposes mechanism sparsity regularization as a new principle to achieve nonlinear ICA when latent factors depend sparsely on observed auxiliary variables and/or past latent factors. We show that the latent variables can be recovered up to a permutation if one regularizes the latent mechanisms to be sparse and if some graphical criterion is satisfied by the data generating process. As a special case, our framework shows how one can leverage unknown-target interventions on the latent factors to disentangle them, thus drawing further connections between ICA and causality. We validate our theoretical results with toy experiments.
Pay attention to the activations: a modular attention mechanism for fine-grained image recognition
Jul 30, 2019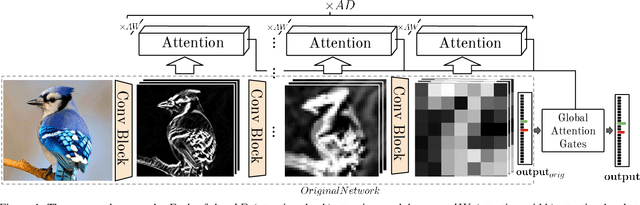
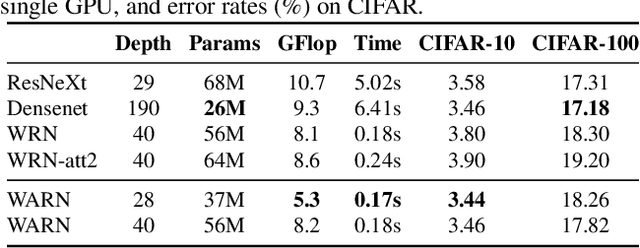
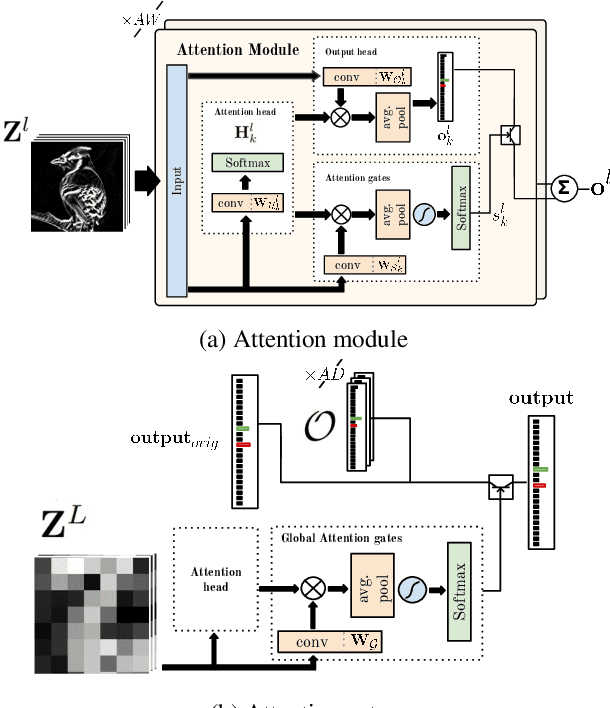
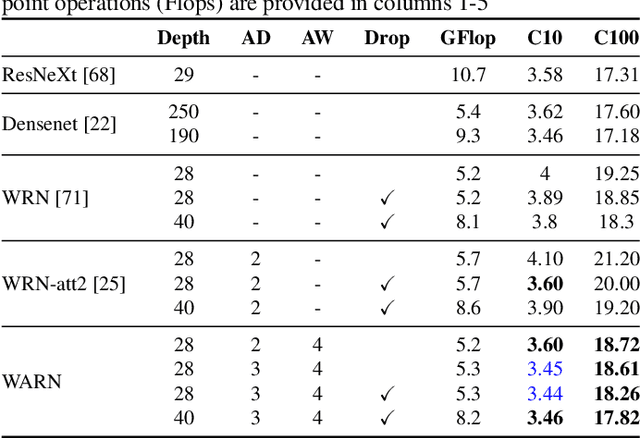
Fine-grained image recognition is central to many multimedia tasks such as search, retrieval and captioning. Unfortunately, these tasks are still challenging since the appearance of samples of the same class can be more different than those from different classes. Attention has been typically implemented in neural networks by selecting the most informative regions of the image that improve classification. In contrast, in this paper, attention is not applied at the image level but to the convolutional feature activations. In essence, with our approach, the neural model learns to attend to lower-level feature activations without requiring part annotations and uses those activations to update and rectify the output likelihood distribution. The proposed mechanism is modular, architecture-independent and efficient in terms of both parameters and computation required. Experiments demonstrate that well-known networks such as Wide Residual Networks and ResNeXt, when augmented with our approach, systematically improve their classification accuracy and become more robust to changes in deformation and pose and to the presence of clutter. As a result, our proposal reaches state-of-the-art classification accuracies in CIFAR-10, the Adience gender recognition task, Stanford Dogs, and UEC-Food100 while obtaining competitive performance in ImageNet, CIFAR-100, CUB200 Birds, and Stanford Cars. In addition, we analyze the different components of our model, showing that the proposed attention modules succeed in finding the most discriminative regions of the image. Finally, as a proof of concept, we demonstrate that with only local predictions, an augmented neural network can successfully classify an image before reaching any fully connected layer, thus reducing the computational amount up to 10%.