 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay attention to the activations: a modular attention mechanism for fine-grained image recognition
Paper and Code
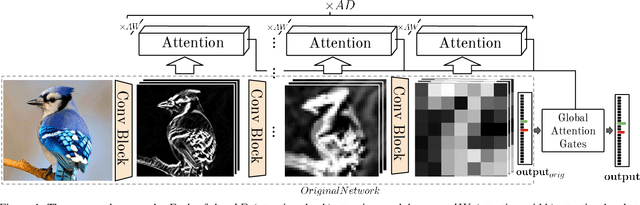
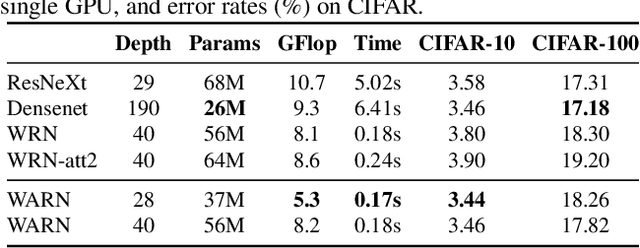
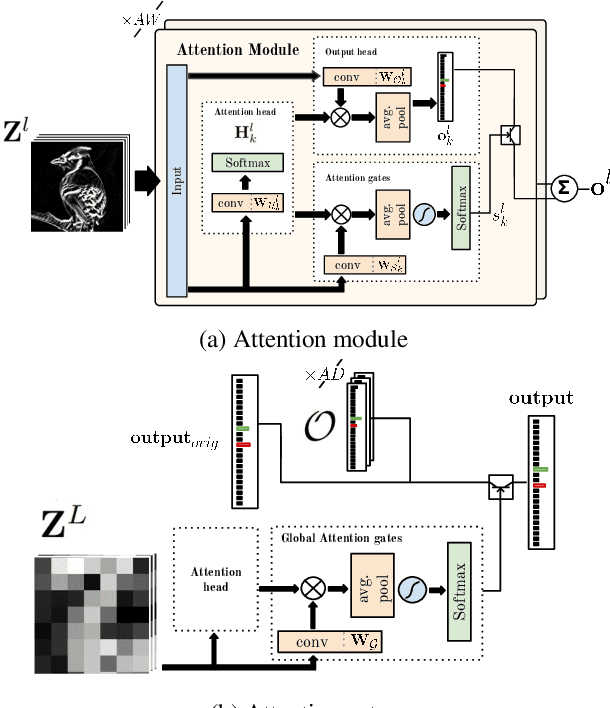
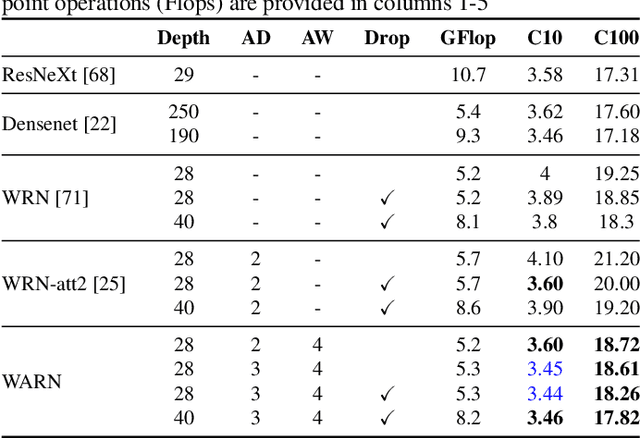
Fine-grained image recognition is central to many multimedia tasks such as search, retrieval and captioning. Unfortunately, these tasks are still challenging since the appearance of samples of the same class can be more different than those from different classes. Attention has been typically implemented in neural networks by selecting the most informative regions of the image that improve classification. In contrast, in this paper, attention is not applied at the image level but to the convolutional feature activations. In essence, with our approach, the neural model learns to attend to lower-level feature activations without requiring part annotations and uses those activations to update and rectify the output likelihood distribution. The proposed mechanism is modular, architecture-independent and efficient in terms of both parameters and computation required. Experiments demonstrate that well-known networks such as Wide Residual Networks and ResNeXt, when augmented with our approach, systematically improve their classification accuracy and become more robust to changes in deformation and pose and to the presence of clutter. As a result, our proposal reaches state-of-the-art classification accuracies in CIFAR-10, the Adience gender recognition task, Stanford Dogs, and UEC-Food100 while obtaining competitive performance in ImageNet, CIFAR-100, CUB200 Birds, and Stanford Cars. In addition, we analyze the different components of our model, showing that the proposed attention modules succeed in finding the most discriminative regions of the image. Finally, as a proof of concept, we demonstrate that with only local predictions, an augmented neural network can successfully classify an image before reaching any fully connected layer, thus reducing the computational amount up to 10%.