 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGujarati-English Code-Switching Speech Recognition using ensemble prediction of spoken language
Mar 12, 2024An important and difficult task in code-switched speech recognition is to recognize the language, as lots of words in two languages can sound similar, especially in some accents. We focus on improving performance of end-to-end Automatic Speech Recognition models by conditioning transformer layers on language ID of words and character in the output in an per layer supervised manner. To this end, we propose two methods of introducing language specific parameters and explainability in the multi-head attention mechanism, and implement a Temporal Loss that helps maintain continuity in input alignment. Despite being unable to reduce WER significantly, our method shows promise in predicting the correct language from just spoken data. We introduce regularization in the language prediction by dropping LID in the sequence, which helps align long repeated output sequences.
Multilingual and code-switching ASR challenges for low resource Indian languages
Apr 01, 2021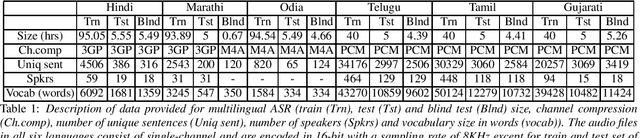
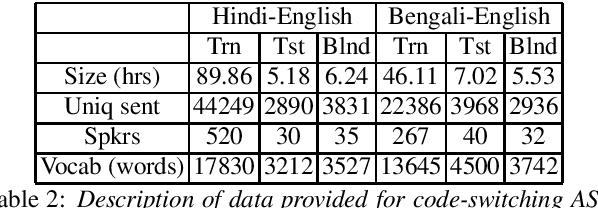
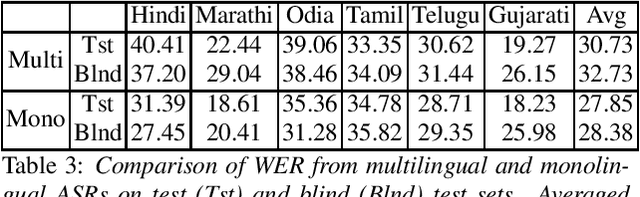
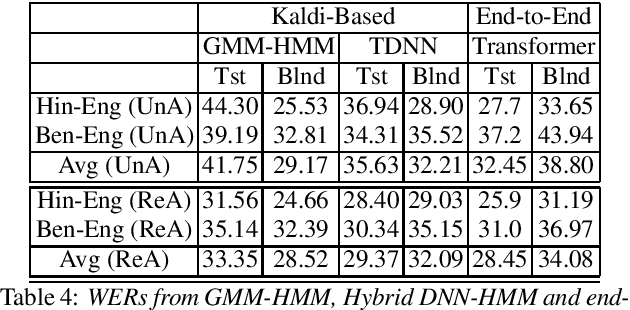
Recently, there is increasing interest in multilingual automatic speech recognition (ASR) where a speech recognition system caters to multiple low resource languages by taking advantage of low amounts of labeled corpora in multiple languages. With multilingualism becoming common in today's world, there has been increasing interest in code-switching ASR as well. In code-switching, multiple languages are freely interchanged within a single sentence or between sentences. The success of low-resource multilingual and code-switching ASR often depends on the variety of languages in terms of their acoustics, linguistic characteristics as well as the amount of data available and how these are carefully considered in building the ASR system. In this challenge, we would like to focus on building multilingual and code-switching ASR systems through two different subtasks related to a total of seven Indian languages, namely Hindi, Marathi, Odia, Tamil, Telugu, Gujarati and Bengali. For this purpose, we provide a total of ~600 hours of transcribed speech data, comprising train and test sets, in these languages including two code-switched language pairs, Hindi-English and Bengali-English. We also provide a baseline recipe for both the tasks with a WER of 30.73% and 32.45% on the test sets of multilingual and code-switching subtasks, respectively.
Improving Low Resource Code-switched ASR using Augmented Code-switched TTS
Oct 12, 2020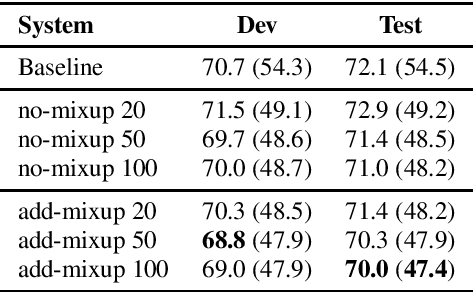
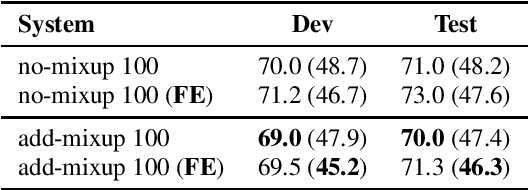
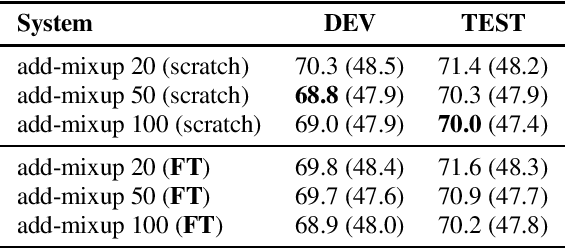
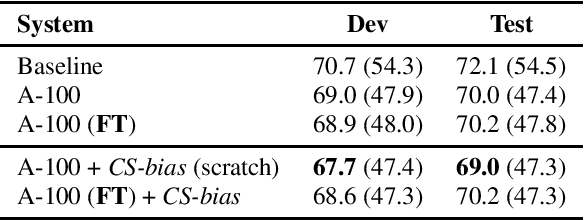
Building Automatic Speech Recognition (ASR) systems for code-switched speech has recently gained renewed attention due to the widespread use of speech technologies in multilingual communities worldwide. End-to-end ASR systems are a natural modeling choice due to their ease of use and superior performance in monolingual settings. However, it is well known that end-to-end systems require large amounts of labeled speech. In this work, we investigate improving code-switched ASR in low resource settings via data augmentation using code-switched text-to-speech (TTS) synthesis. We propose two targeted techniques to effectively leverage TTS speech samples: 1) Mixup, an existing technique to create new training samples via linear interpolation of existing samples, applied to TTS and real speech samples, and 2) a new loss function, used in conjunction with TTS samples, to encourage code-switched predictions. We report significant improvements in ASR performance achieving absolute word error rate (WER) reductions of up to 5%, and measurable improvement in code switching using our proposed techniques on a Hindi-English code-switched ASR task.
Learning not to Discriminate: Task Agnostic Learning for Improving Monolingual and Code-switched Speech Recognition
Jun 09, 2020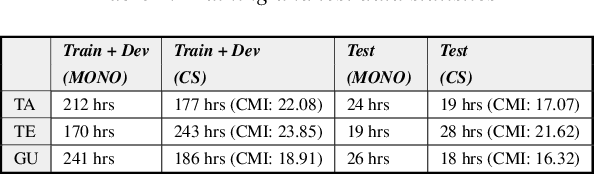
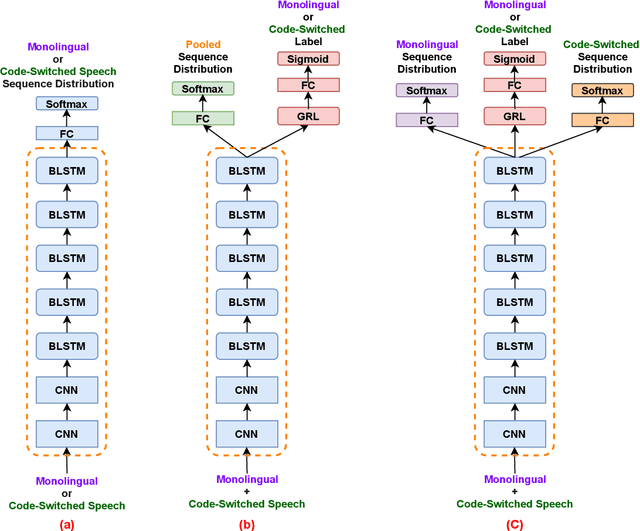
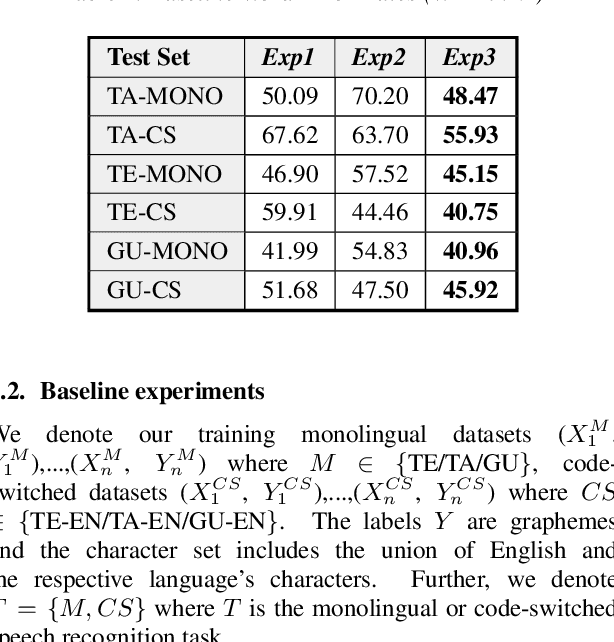
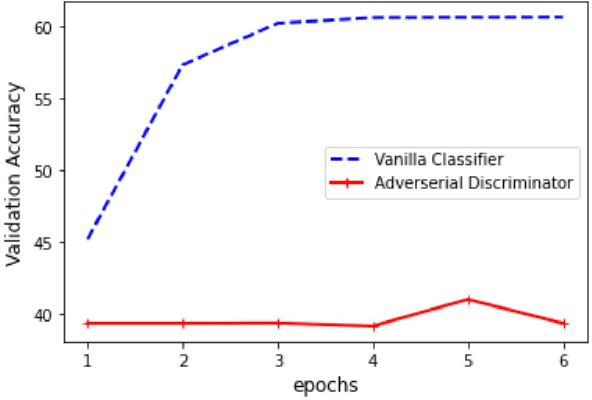
Recognizing code-switched speech is challenging for Automatic Speech Recognition (ASR) for a variety of reasons, including the lack of code-switched training data. Recently, we showed that monolingual ASR systems fine-tuned on code-switched data deteriorate in performance on monolingual speech recognition, which is not desirable as ASR systems deployed in multilingual scenarios should recognize both monolingual and code-switched speech with high accuracy. Our experiments indicated that this loss in performance could be mitigated by using certain strategies for fine-tuning and regularization, leading to improvements in both monolingual and code-switched ASR. In this work, we present further improvements over our previous work by using domain adversarial learning to train task agnostic models. We evaluate the classification accuracy of an adversarial discriminator and show that it can learn shared layer parameters that are task agnostic. We train end-to-end ASR systems starting with a pooled model that uses monolingual and code-switched data along with the adversarial discriminator. Our proposed technique leads to reductions in Word Error Rates (WER) in monolingual and code-switched test sets across three language pairs.
Learning to Recognize Code-switched Speech Without Forgetting Monolingual Speech Recognition
Jun 01, 2020
Recently, there has been significant progress made in Automatic Speech Recognition (ASR) of code-switched speech, leading to gains in accuracy on code-switched datasets in many language pairs. Code-switched speech co-occurs with monolingual speech in one or both languages being mixed. In this work, we show that fine-tuning ASR models on code-switched speech harms performance on monolingual speech. We point out the need to optimize models for code-switching while also ensuring that monolingual performance is not sacrificed. Monolingual models may be trained on thousands of hours of speech which may not be available for re-training a new model. We propose using the Learning Without Forgetting (LWF) framework for code-switched ASR when we only have access to a monolingual model and do not have the data it was trained on. We show that it is possible to train models using this framework that perform well on both code-switched and monolingual test sets. In cases where we have access to monolingual training data as well, we propose regularization strategies for fine-tuning models for code-switching without sacrificing monolingual accuracy. We report improvements in Word Error Rate (WER) in monolingual and code-switched test sets compared to baselines that use pooled data and simple fine-tuning.
End-to-End ASR for Code-switched Hindi-English Speech
Jun 22, 2019
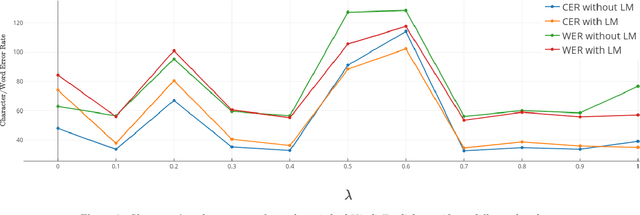
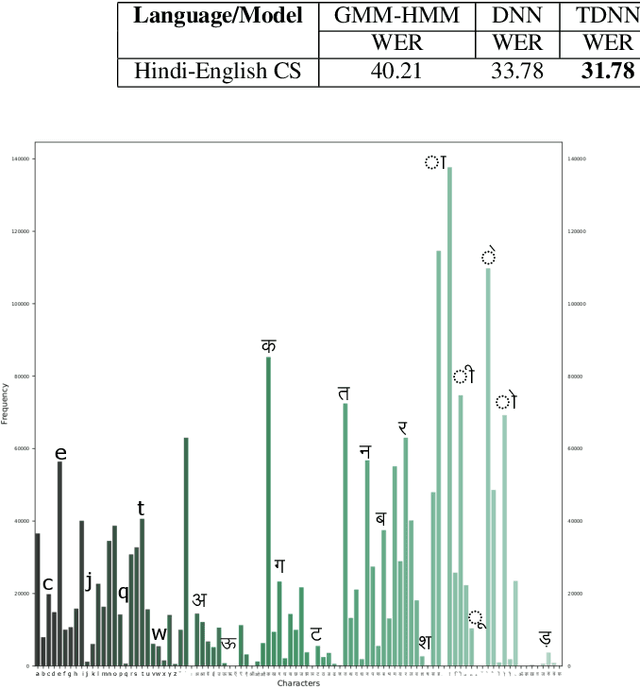
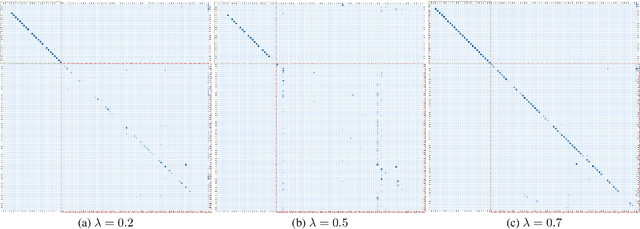
End-to-end (E2E) models have been explored for large speech corpora and have been found to match or outperform traditional pipeline-based systems in some languages. However, most prior work on end-to-end models use speech corpora exceeding hundreds or thousands of hours. In this study, we explore end-to-end models for code-switched Hindi-English language with less than 50 hours of data. We utilize two specific measures to improve network performance in the low-resource setting, namely multi-task learning (MTL) and balancing the corpus to deal with the inherent class imbalance problem i.e. the skewed frequency distribution over graphemes. We compare the results of the proposed approaches with traditional, cascaded ASR systems. While the lack of data adversely affects the performance of end-to-end models, we see promising improvements with MTL and balancing the corpus.