 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALT: Hallucination Assessment via Log-probs as Time series
Feb 02, 2026Hallucinations remain a major obstacle for large language models (LLMs), especially in safety-critical domains. We present HALT (Hallucination Assessment via Log-probs as Time series), a lightweight hallucination detector that leverages only the top-20 token log-probabilities from LLM generations as a time series. HALT uses a gated recurrent unit model combined with entropy-based features to learn model calibration bias, providing an extremely efficient alternative to large encoders. Unlike white-box approaches, HALT does not require access to hidden states or attention maps, relying only on output log-probabilities. Unlike black-box approaches, it operates on log-probs rather than surface-form text, which enables stronger domain generalization and compatibility with proprietary LLMs without requiring access to internal weights. To benchmark performance, we introduce HUB (Hallucination detection Unified Benchmark), which consolidates prior datasets into ten capabilities covering both reasoning tasks (Algorithmic, Commonsense, Mathematical, Symbolic, Code Generation) and general purpose skills (Chat, Data-to-Text, Question Answering, Summarization, World Knowledge). While being 30x smaller, HALT outperforms Lettuce, a fine-tuned modernBERT-base encoder, achieving a 60x speedup gain on HUB. HALT and HUB together establish an effective framework for hallucination detection across diverse LLM capabilities.
Jill Watson: A Virtual Teaching Assistant powered by ChatGPT
May 17, 2024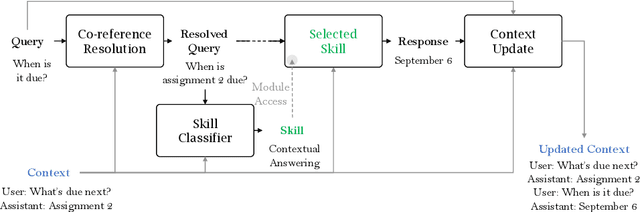

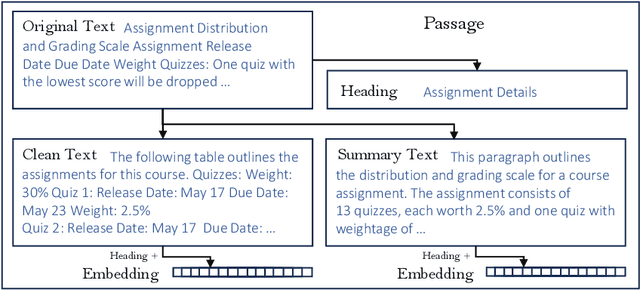

Conversational AI agents often require extensive datasets for training that are not publicly released, are limited to social chit-chat or handling a specific domain, and may not be easily extended to accommodate the latest advances in AI technologies. This paper introduces Jill Watson, a conversational Virtual Teaching Assistant (VTA) leveraging the capabilities of ChatGPT. Jill Watson based on ChatGPT requires no prior training and uses a modular design to allow the integration of new APIs using a skill-based architecture inspired by XiaoIce. Jill Watson is also well-suited for intelligent textbooks as it can process and converse using multiple large documents. We exclusively utilize publicly available resources for reproducibility and extensibility. Comparative analysis shows that our system outperforms the legacy knowledge-based Jill Watson as well as the OpenAI Assistants service. We employ many safety measures that reduce instances of hallucinations and toxicity. The paper also includes real-world examples from a classroom setting that demonstrate different features of Jill Watson and its effectiveness.
Monte Carlo Tree Search for Recipe Generation using GPT-2
Jan 10, 2024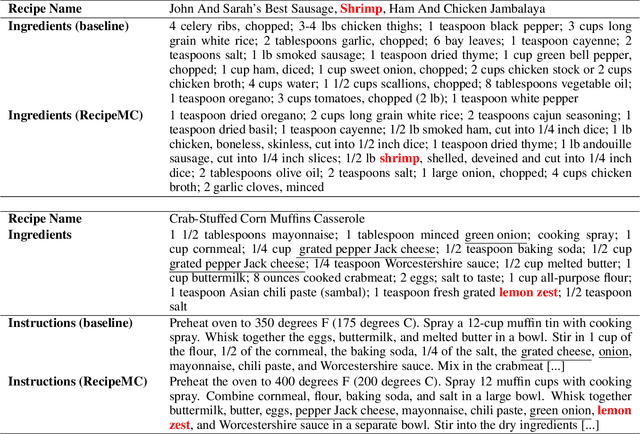



Automatic food recipe generation methods provide a creative tool for chefs to explore and to create new, and interesting culinary delights. Given the recent success of large language models (LLMs), they have the potential to create new recipes that can meet individual preferences, dietary constraints, and adapt to what is in your refrigerator. Existing research on using LLMs to generate recipes has shown that LLMs can be finetuned to generate realistic-sounding recipes. However, on close examination, these generated recipes often fail to meet basic requirements like including chicken as an ingredient in chicken dishes. In this paper, we propose RecipeMC, a text generation method using GPT-2 that relies on Monte Carlo Tree Search (MCTS). RecipeMC allows us to define reward functions to put soft constraints on text generation and thus improve the credibility of the generated recipes. Our results show that human evaluators prefer recipes generated with RecipeMC more often than recipes generated with other baseline methods when compared with real recipes.
Machine Teaching for Building Modular AI Agents based on Zero-shot Learners
Jan 10, 2024



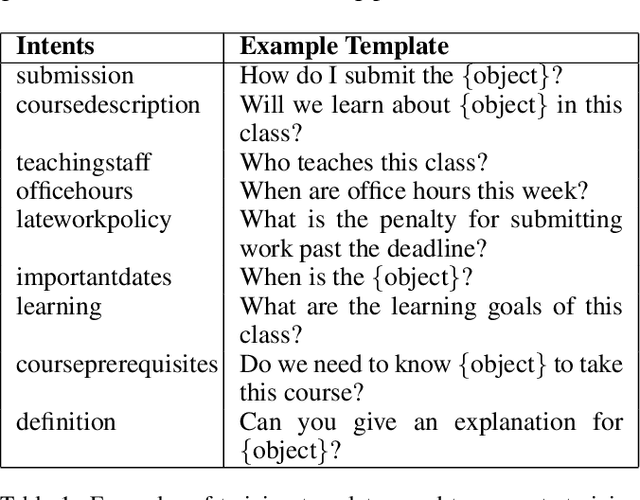
The recent advances in large language models (LLMs) have led to the creation of many modular AI agents. These agents employ LLMs as zero-shot learners to perform sub-tasks in order to solve complex tasks set forth by human users. We propose an approach to enhance the robustness and performance of modular AI agents that utilize LLMs as zero-shot learners. Our iterative machine teaching method offers an efficient way to teach AI agents over time with limited human feedback, addressing the limit posed by the quality of zero-shot learning. We advocate leveraging the data traces from initial deployments and outputs or annotations from the zero-shot learners to train smaller and task-specific substitute models which can reduce both the monetary costs and environmental impact. Our machine teaching process avails human expertise to correct examples with a high likelihood of misannotations. Results on three tasks, common to conversational AI agents, show that close-to-oracle performance can be achieved with supervision on 20-70% of the dataset depending upon the complexity of the task and performance of zero-shot learners.
A Multi-Resolution Physics-Informed Recurrent Neural Network: Formulation and Application to Musculoskeletal Systems
May 26, 2023This work presents a multi-resolution physics-informed recurrent neural network (MR PI-RNN), for simultaneous prediction of musculoskeletal (MSK) motion and parameter identification of the MSK systems. The MSK application was selected as the model problem due to its challenging nature in mapping the high-frequency surface electromyography (sEMG) signals to the low-frequency body joint motion controlled by the MSK and muscle contraction dynamics. The proposed method utilizes the fast wavelet transform to decompose the mixed frequency input sEMG and output joint motion signals into nested multi-resolution signals. The prediction model is subsequently trained on coarser-scale input-output signals using a gated recurrent unit (GRU), and then the trained parameters are transferred to the next level of training with finer-scale signals. These training processes are repeated recursively under a transfer-learning fashion until the full-scale training (i.e., with unfiltered signals) is achieved, while satisfying the underlying dynamic equilibrium. Numerical examples on recorded subject data demonstrate the effectiveness of the proposed framework in generating a physics-informed forward-dynamics surrogate, which yields higher accuracy in motion predictions of elbow flexion-extension of an MSK system compared to the case with single-scale training. The framework is also capable of identifying muscle parameters that are physiologically consistent with the subject's kinematics data.
Human-AI Interaction Design in Machine Teaching
Jun 10, 2022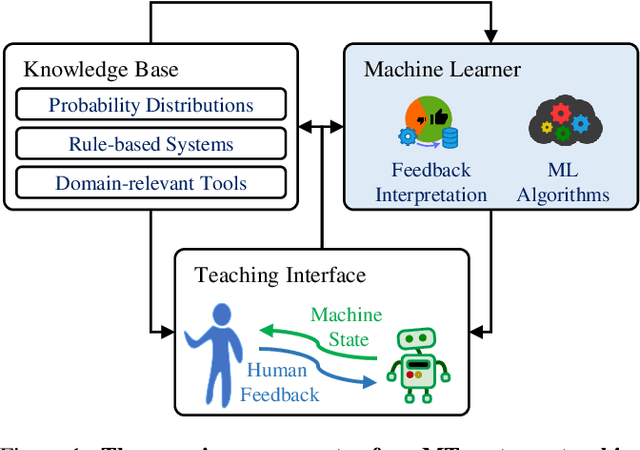

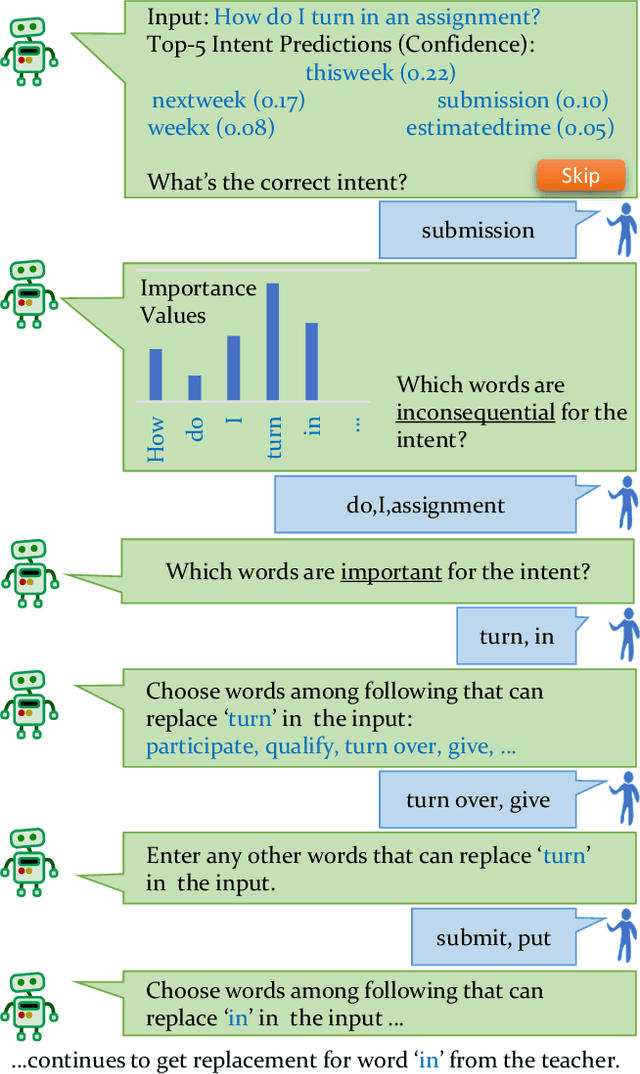
Machine Teaching (MT) is an interactive process where a human and a machine interact with the goal of training a machine learning model (ML) for a specified task. The human teacher communicates their task expertise and the machine student gathers the required data and knowledge to produce an ML model. MT systems are developed to jointly minimize the time spent on teaching and the learner's error rate. The design of human-AI interaction in an MT system not only impacts the teaching efficiency, but also indirectly influences the ML performance by affecting the teaching quality. In this paper, we build upon our previous work where we proposed an MT framework with three components, viz., the teaching interface, the machine learner, and the knowledge base, and focus on the human-AI interaction design involved in realizing the teaching interface. We outline design decisions that need to be addressed in developing an MT system beginning from an ML task. The paper follows the Socratic method entailing a dialogue between a curious student and a wise teacher.
A Framework for Interactive Knowledge-Aided Machine Teaching
Apr 21, 2022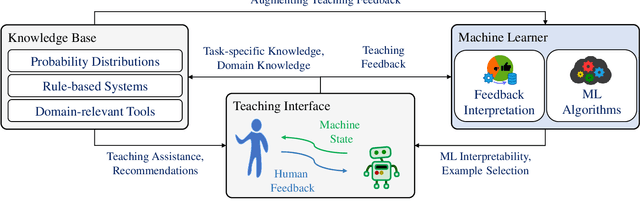
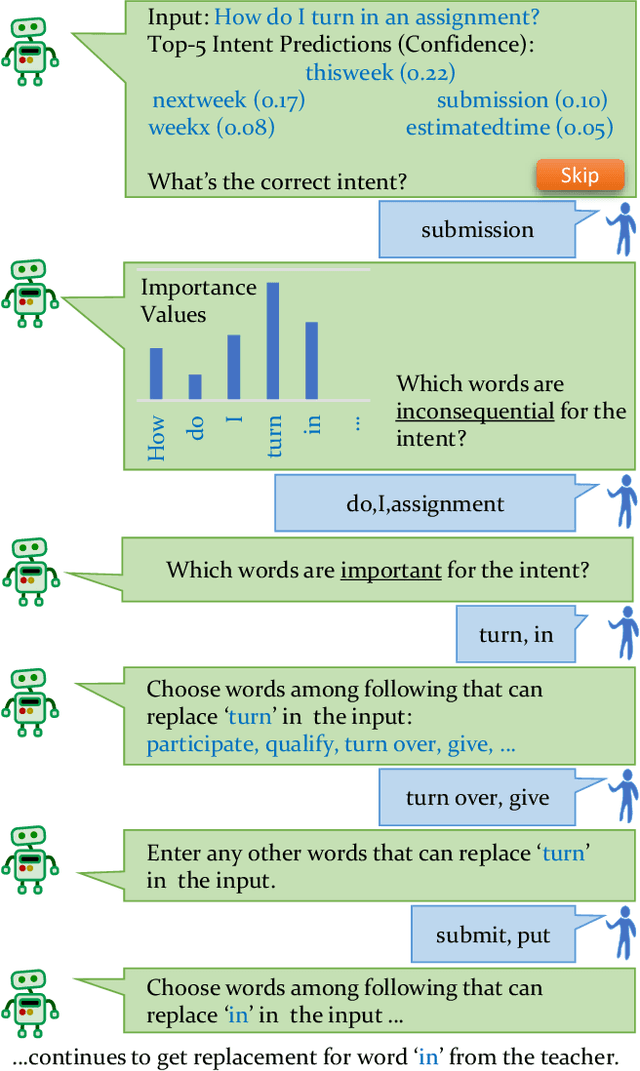
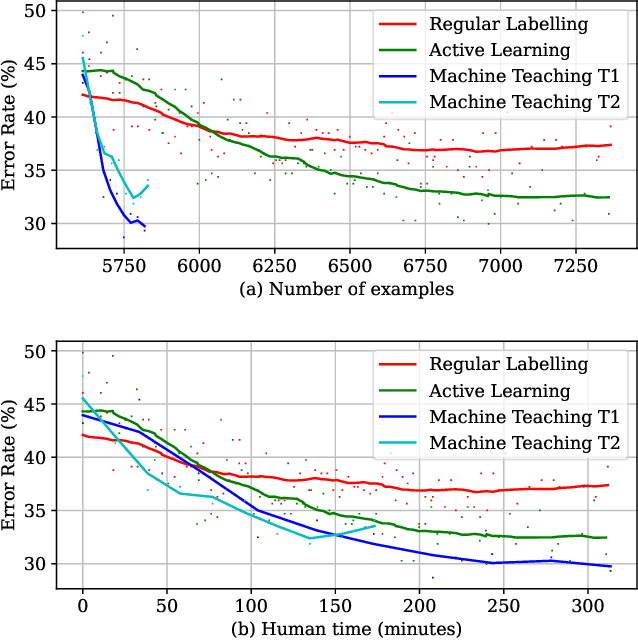
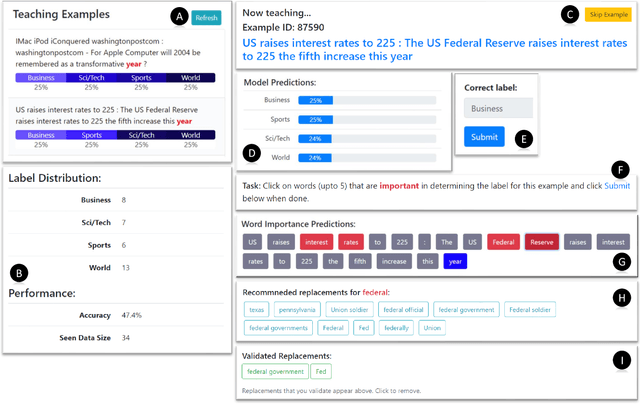
Machine Teaching (MT) is an interactive process where humans train a machine learning model by playing the role of a teacher. The process of designing an MT system involves decisions that can impact both efficiency of human teachers and performance of machine learners. Previous research has proposed and evaluated specific MT systems but there is limited discussion on a general framework for designing them. We propose a framework for designing MT systems and also detail a system for the text classification problem as a specific instance. Our framework focuses on three components i.e. teaching interface, machine learner, and knowledge base; and their relations describe how each component can benefit the others. Our preliminary experiments show how MT systems can reduce both human teaching time and machine learner error rate.
Improving Low Resource Code-switched ASR using Augmented Code-switched TTS
Oct 12, 2020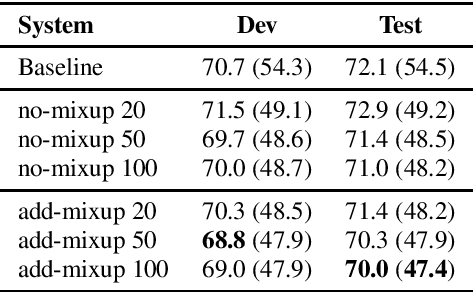
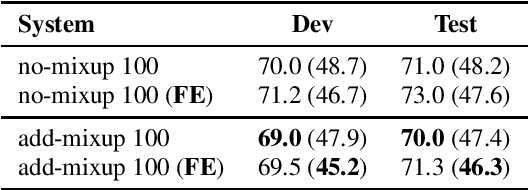
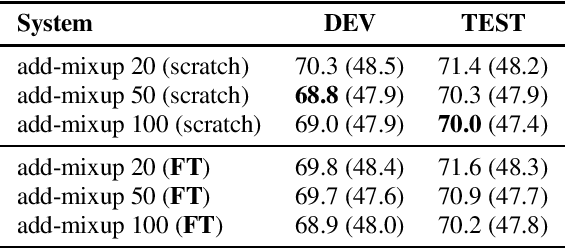
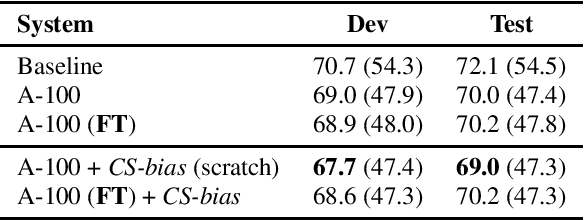
Building Automatic Speech Recognition (ASR) systems for code-switched speech has recently gained renewed attention due to the widespread use of speech technologies in multilingual communities worldwide. End-to-end ASR systems are a natural modeling choice due to their ease of use and superior performance in monolingual settings. However, it is well known that end-to-end systems require large amounts of labeled speech. In this work, we investigate improving code-switched ASR in low resource settings via data augmentation using code-switched text-to-speech (TTS) synthesis. We propose two targeted techniques to effectively leverage TTS speech samples: 1) Mixup, an existing technique to create new training samples via linear interpolation of existing samples, applied to TTS and real speech samples, and 2) a new loss function, used in conjunction with TTS samples, to encourage code-switched predictions. We report significant improvements in ASR performance achieving absolute word error rate (WER) reductions of up to 5%, and measurable improvement in code switching using our proposed techniques on a Hindi-English code-switched ASR task.