 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Model Prompting Increases LLM Performance on Planning Tasks
Feb 03, 2026Large Language Models (LLM) can struggle with reasoning ability and planning tasks. Many prompting techniques have been developed to assist with LLM reasoning, notably Chain-of-Thought (CoT); however, these techniques, too, have come under scrutiny as LLMs' ability to reason at all has come into question. Borrowing from the domain of cognitive and educational science, this paper investigates whether the Task-Method-Knowledge (TMK) framework can improve LLM reasoning capabilities beyond its previously demonstrated success in educational applications. The TMK framework's unique ability to capture causal, teleological, and hierarchical reasoning structures, combined with its explicit task decomposition mechanisms, makes it particularly well-suited for addressing language model reasoning deficiencies, and unlike other hierarchical frameworks such as HTN and BDI, TMK provides explicit representations of not just what to do and how to do it, but also why actions are taken. The study evaluates TMK by experimenting on the PlanBench benchmark, focusing on the Blocksworld domain to test for reasoning and planning capabilities, examining whether TMK-structured prompting can help language models better decompose complex planning problems into manageable sub-tasks. Results also highlight significant performance inversion in reasoning models. TMK prompting enables the reasoning model to achieve up to an accuracy of 97.3\% on opaque, symbolic tasks (Random versions of Blocksworld in PlanBench) where it previously failed (31.5\%), suggesting the potential to bridge the gap between semantic approximation and symbolic manipulation. Our findings suggest that TMK functions not merely as context, but also as a mechanism that steers reasoning models away from their default linguistic modes to engage formal, code-execution pathways in the context of the experiments.
HALT: Hallucination Assessment via Log-probs as Time series
Feb 02, 2026Hallucinations remain a major obstacle for large language models (LLMs), especially in safety-critical domains. We present HALT (Hallucination Assessment via Log-probs as Time series), a lightweight hallucination detector that leverages only the top-20 token log-probabilities from LLM generations as a time series. HALT uses a gated recurrent unit model combined with entropy-based features to learn model calibration bias, providing an extremely efficient alternative to large encoders. Unlike white-box approaches, HALT does not require access to hidden states or attention maps, relying only on output log-probabilities. Unlike black-box approaches, it operates on log-probs rather than surface-form text, which enables stronger domain generalization and compatibility with proprietary LLMs without requiring access to internal weights. To benchmark performance, we introduce HUB (Hallucination detection Unified Benchmark), which consolidates prior datasets into ten capabilities covering both reasoning tasks (Algorithmic, Commonsense, Mathematical, Symbolic, Code Generation) and general purpose skills (Chat, Data-to-Text, Question Answering, Summarization, World Knowledge). While being 30x smaller, HALT outperforms Lettuce, a fine-tuned modernBERT-base encoder, achieving a 60x speedup gain on HUB. HALT and HUB together establish an effective framework for hallucination detection across diverse LLM capabilities.
A4L: An Architecture for AI-Augmented Learning
May 08, 2025AI promises personalized learning and scalable education. As AI agents increasingly permeate education in support of teaching and learning, there is a critical and urgent need for data architectures for collecting and analyzing data on learning, and feeding the results back to teachers, learners, and the AI agents for personalization of learning at scale. At the National AI Institute for Adult Learning and Online Education, we are developing an Architecture for AI-Augmented Learning (A4L) for supporting adult learning through online education. We present the motivations, goals, requirements of the A4L architecture. We describe preliminary applications of A4L and discuss how it advances the goals of making learning more personalized and scalable.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Combining Cognitive and Generative AI for Self-explanation in Interactive AI Agents
Jul 25, 2024The Virtual Experimental Research Assistant (VERA) is an inquiry-based learning environment that empowers a learner to build conceptual models of complex ecological systems and experiment with agent-based simulations of the models. This study investigates the convergence of cognitive AI and generative AI for self-explanation in interactive AI agents such as VERA. From a cognitive AI viewpoint, we endow VERA with a functional model of its own design, knowledge, and reasoning represented in the Task--Method--Knowledge (TMK) language. From the perspective of generative AI, we use ChatGPT, LangChain, and Chain-of-Thought to answer user questions based on the VERA TMK model. Thus, we combine cognitive and generative AI to generate explanations about how VERA works and produces its answers. The preliminary evaluation of the generation of explanations in VERA on a bank of 66 questions derived from earlier work appears promising.
Machine Teaching for Building Modular AI Agents based on Zero-shot Learners
Jan 10, 2024



The recent advances in large language models (LLMs) have led to the creation of many modular AI agents. These agents employ LLMs as zero-shot learners to perform sub-tasks in order to solve complex tasks set forth by human users. We propose an approach to enhance the robustness and performance of modular AI agents that utilize LLMs as zero-shot learners. Our iterative machine teaching method offers an efficient way to teach AI agents over time with limited human feedback, addressing the limit posed by the quality of zero-shot learning. We advocate leveraging the data traces from initial deployments and outputs or annotations from the zero-shot learners to train smaller and task-specific substitute models which can reduce both the monetary costs and environmental impact. Our machine teaching process avails human expertise to correct examples with a high likelihood of misannotations. Results on three tasks, common to conversational AI agents, show that close-to-oracle performance can be achieved with supervision on 20-70% of the dataset depending upon the complexity of the task and performance of zero-shot learners.
Using Analytics on Student Created Data to Content Validate Pedagogical Tools
Dec 11, 2023



Conceptual and simulation models can function as useful pedagogical tools, however it is important to categorize different outcomes when evaluating them in order to more meaningfully interpret results. VERA is a ecology-based conceptual modeling software that enables users to simulate interactions between biotics and abiotics in an ecosystem, allowing users to form and then verify hypothesis through observing a time series of the species populations. In this paper, we classify this time series into common patterns found in the domain of ecological modeling through two methods, hierarchical clustering and curve fitting, illustrating a general methodology for showing content validity when combining different pedagogical tools. When applied to a diverse sample of 263 models containing 971 time series collected from three different VERA user categories: a Georgia Tech (GATECH), North Georgia Technical College (NGTC), and ``Self Directed Learners'', results showed agreement between both classification methods on 89.38\% of the sample curves in the test set. This serves as a good indication that our methodology for determining content validity was successful.
Human-AI Interaction Design in Machine Teaching
Jun 10, 2022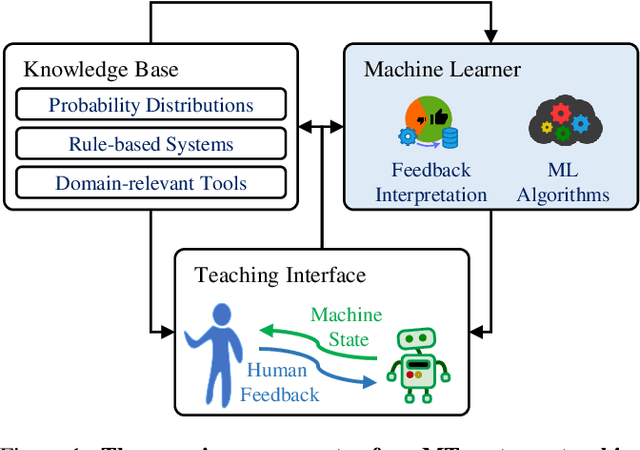

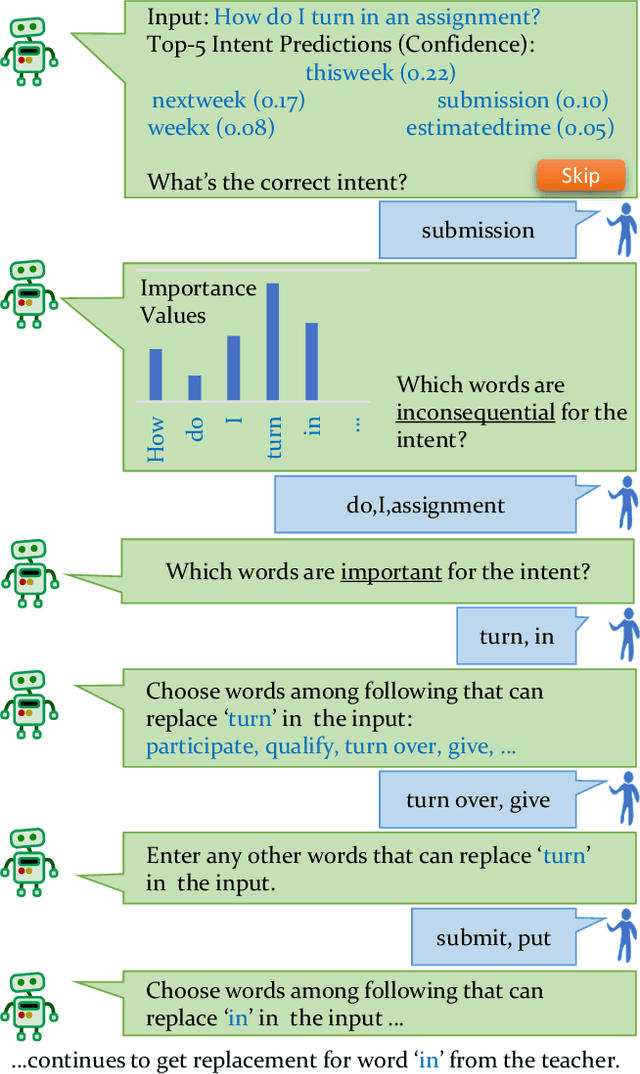
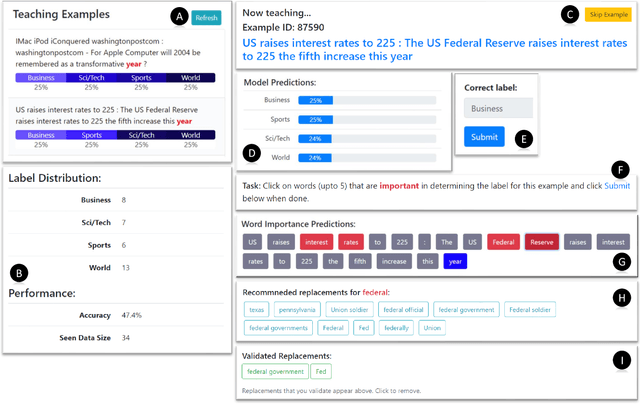
Machine Teaching (MT) is an interactive process where a human and a machine interact with the goal of training a machine learning model (ML) for a specified task. The human teacher communicates their task expertise and the machine student gathers the required data and knowledge to produce an ML model. MT systems are developed to jointly minimize the time spent on teaching and the learner's error rate. The design of human-AI interaction in an MT system not only impacts the teaching efficiency, but also indirectly influences the ML performance by affecting the teaching quality. In this paper, we build upon our previous work where we proposed an MT framework with three components, viz., the teaching interface, the machine learner, and the knowledge base, and focus on the human-AI interaction design involved in realizing the teaching interface. We outline design decisions that need to be addressed in developing an MT system beginning from an ML task. The paper follows the Socratic method entailing a dialogue between a curious student and a wise teacher.
Explanation as Question Answering based on a Task Model of the Agent's Design
Jun 08, 2022

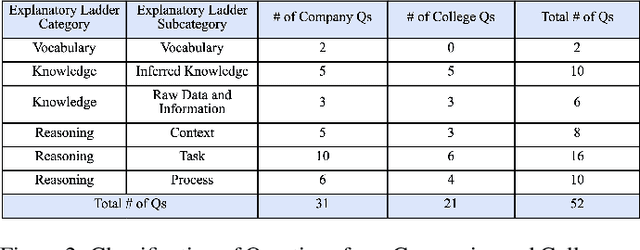

We describe a stance towards the generation of explanations in AI agents that is both human-centered and design-based. We collect questions about the working of an AI agent through participatory design by focus groups. We capture an agent's design through a Task-Method-Knowledge model that explicitly specifies the agent's tasks and goals, as well as the mechanisms, knowledge and vocabulary it uses for accomplishing the tasks. We illustrate our approach through the generation of explanations in Skillsync, an AI agent that links companies and colleges for worker upskilling and reskilling. In particular, we embed a question-answering agent called AskJill in Skillsync, where AskJill contains a TMK model of Skillsync's design. AskJill presently answers human-generated questions about Skillsync's tasks and vocabulary, and thereby helps explain how it produces its recommendations.
Symmetry as a Representation of Intuitive Geometry?
Jun 04, 2022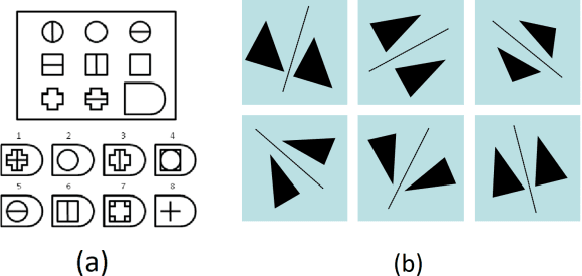
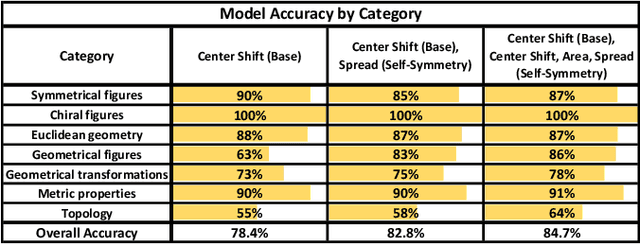
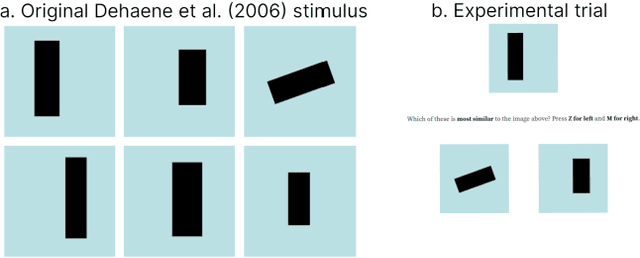
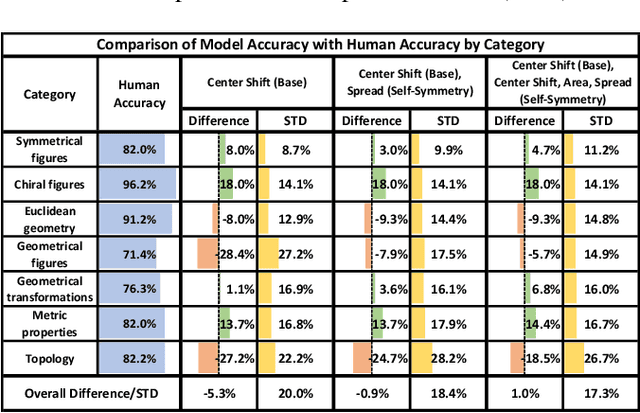
Recognition of geometrical patterns seems to be an important aspect of human intelligence. Geometric pattern recognition is used in many intelligence tests, including Dehaene's odd-one-out test of Core Geometry (CG)) based on intuitive geometrical concepts (Dehaene et al., 2006). Earlier work has developed a symmetry-based cognitive model of Dehaene's test and demonstrated performance comparable to that of humans. In this work, we further investigate the role of symmetry in geometrical intuition and build a cognitive model for the 2-Alternative Forced Choice (2-AFC) variation of the CG test (Marupudi & Varma 2021). In contrast to Dehaene's test, 2-AFC leaves almost no space for cognitive models based on generalization over multiple examples. Our symmetry-based model achieves an accuracy comparable to the human average on the 2-AFC test and appears to capture an essential part of intuitive geometry.