 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNC-Bench: An LLM Benchmark for Evaluating Conversational Competence
Jan 10, 2026The Natural Conversation Benchmark (NC-Bench) introduce a new approach to evaluating the general conversational competence of large language models (LLMs). Unlike prior benchmarks that focus on the content of model behavior, NC-Bench focuses on the form and structure of natural conversation. Grounded in the IBM Natural Conversation Framework (NCF), NC-Bench comprises three distinct sets. The Basic Conversation Competence set evaluates fundamental sequence management practices, such as answering inquiries, repairing responses, and closing conversational pairs. The RAG set applies the same sequence management patterns as the first set but incorporates retrieval-augmented generation (RAG). The Complex Request set extends the evaluation to complex requests involving more intricate sequence management patterns. Each benchmark tests a model's ability to produce contextually appropriate conversational actions in response to characteristic interaction patterns. Initial evaluations across 6 open-source models and 14 interaction patterns show that models perform well on basic answering tasks, struggle more with repair tasks (especially repeat), have mixed performance on closing sequences, and find complex multi-turn requests most challenging, with Qwen models excelling on the Basic set and Granite models on the RAG set and the Complex Request set. By operationalizing fundamental principles of human conversation, NC-Bench provides a lightweight, extensible, and theory-grounded framework for assessing and improving the conversational abilities of LLMs beyond topical or task-specific benchmarks.
Data-Prep-Kit: getting your data ready for LLM application development
Sep 26, 2024



Data preparation is the first and a very important step towards any Large Language Model (LLM) development. This paper introduces an easy-to-use, extensible, and scale-flexible open-source data preparation toolkit called Data Prep Kit (DPK). DPK is architected and designed to enable users to scale their data preparation to their needs. With DPK they can prepare data on a local machine or effortlessly scale to run on a cluster with thousands of CPU Cores. DPK comes with a highly scalable, yet extensible set of modules that transform natural language and code data. If the user needs additional transforms, they can be easily developed using extensive DPK support for transform creation. These modules can be used independently or pipelined to perform a series of operations. In this paper, we describe DPK architecture and show its performance from a small scale to a very large number of CPUs. The modules from DPK have been used for the preparation of Granite Models [1] [2]. We believe DPK is a valuable contribution to the AI community to easily prepare data to enhance the performance of their LLM models or to fine-tune models with Retrieval-Augmented Generation (RAG).
Using Analytics on Student Created Data to Content Validate Pedagogical Tools
Dec 11, 2023



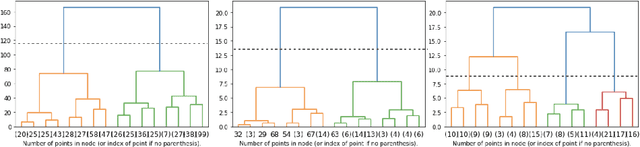
Conceptual and simulation models can function as useful pedagogical tools, however it is important to categorize different outcomes when evaluating them in order to more meaningfully interpret results. VERA is a ecology-based conceptual modeling software that enables users to simulate interactions between biotics and abiotics in an ecosystem, allowing users to form and then verify hypothesis through observing a time series of the species populations. In this paper, we classify this time series into common patterns found in the domain of ecological modeling through two methods, hierarchical clustering and curve fitting, illustrating a general methodology for showing content validity when combining different pedagogical tools. When applied to a diverse sample of 263 models containing 971 time series collected from three different VERA user categories: a Georgia Tech (GATECH), North Georgia Technical College (NGTC), and ``Self Directed Learners'', results showed agreement between both classification methods on 89.38\% of the sample curves in the test set. This serves as a good indication that our methodology for determining content validity was successful.
Understanding Self-Directed Learning in an Online Laboratory
Jun 06, 2022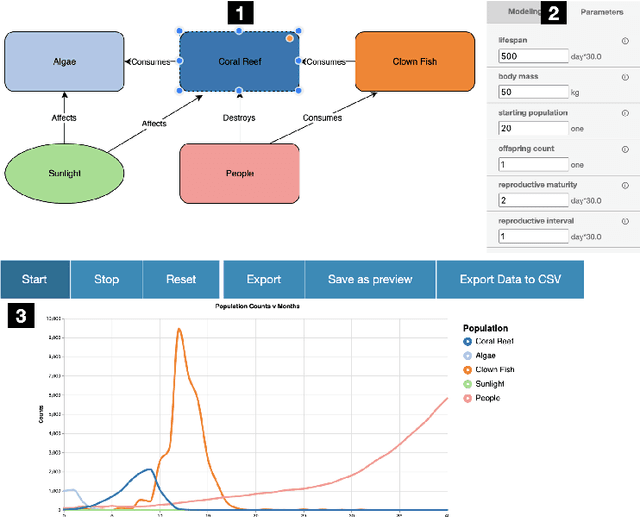


We described a study on the use of an online laboratory for self-directed learning by constructing and simulating conceptual models of ecological systems. In this study, we could observe only the modeling behaviors and outcomes; the learning goals and outcomes were unknown. We used machine learning techniques to analyze the modeling behaviors of 315 learners and 822 conceptual models they generated. We derive three main conclusions from the results. First, learners manifest three types of modeling behaviors: observation (simulation focused), construction (construction focused), and full exploration (model construction, evaluation and revision). Second, while observation was the most common behavior among all learners, construction without evaluation was more common for less engaged learners and full exploration occurred mostly for more engaged learners. Third, learners who explored the full cycle of model construction, evaluation and revision generated models of higher quality. These modeling behaviors provide insights into self-directed learning at large.
Explanation as Question Answering based on Design Knowledge
Dec 16, 2021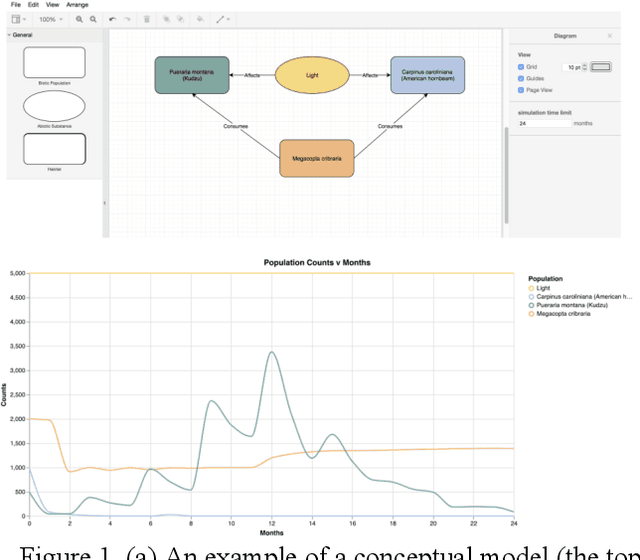
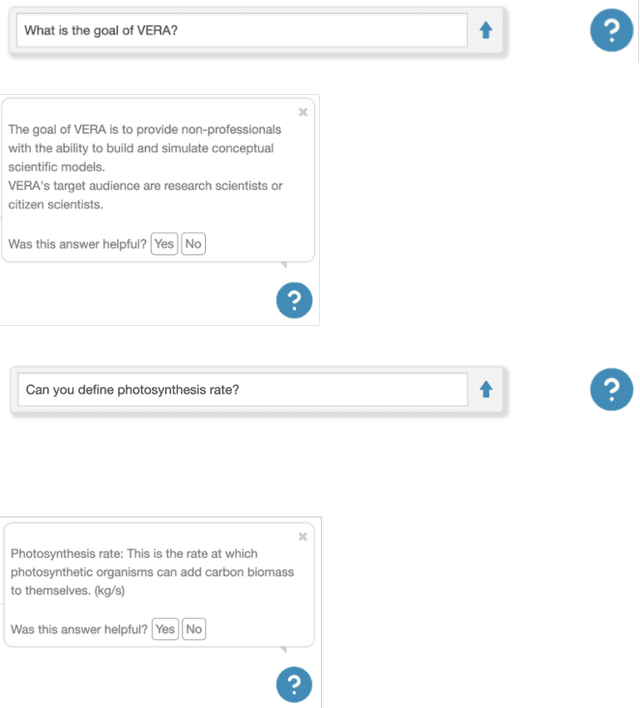

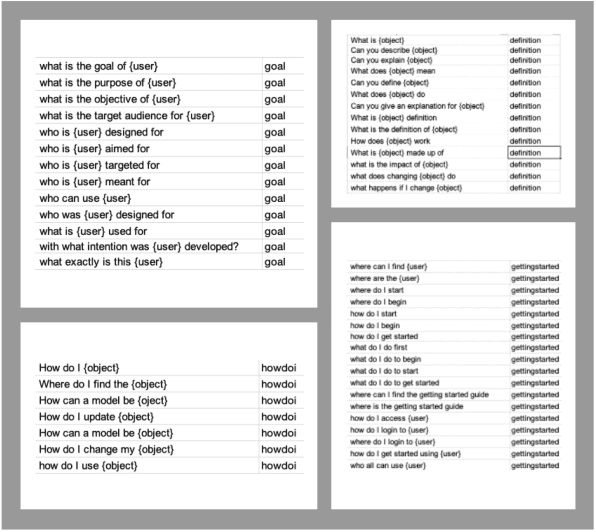
Explanation of an AI agent requires knowledge of its design and operation. An open question is how to identify, access and use this design knowledge for generating explanations. Many AI agents used in practice, such as intelligent tutoring systems fielded in educational contexts, typically come with a User Guide that explains what the agent does, how it works and how to use the agent. However, few humans actually read the User Guide in detail. Instead, most users seek answers to their questions on demand. In this paper, we describe a question answering agent (AskJill) that uses the User Guide for an interactive learning environment (VERA) to automatically answer questions and thereby explains the domain, functioning, and operation of VERA. We present a preliminary assessment of AskJill in VERA.