 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Prep-Kit: getting your data ready for LLM application development
Sep 26, 2024



Data preparation is the first and a very important step towards any Large Language Model (LLM) development. This paper introduces an easy-to-use, extensible, and scale-flexible open-source data preparation toolkit called Data Prep Kit (DPK). DPK is architected and designed to enable users to scale their data preparation to their needs. With DPK they can prepare data on a local machine or effortlessly scale to run on a cluster with thousands of CPU Cores. DPK comes with a highly scalable, yet extensible set of modules that transform natural language and code data. If the user needs additional transforms, they can be easily developed using extensive DPK support for transform creation. These modules can be used independently or pipelined to perform a series of operations. In this paper, we describe DPK architecture and show its performance from a small scale to a very large number of CPUs. The modules from DPK have been used for the preparation of Granite Models [1] [2]. We believe DPK is a valuable contribution to the AI community to easily prepare data to enhance the performance of their LLM models or to fine-tune models with Retrieval-Augmented Generation (RAG).
Attack Techniques and Threat Identification for Vulnerabilities
Jun 22, 2022
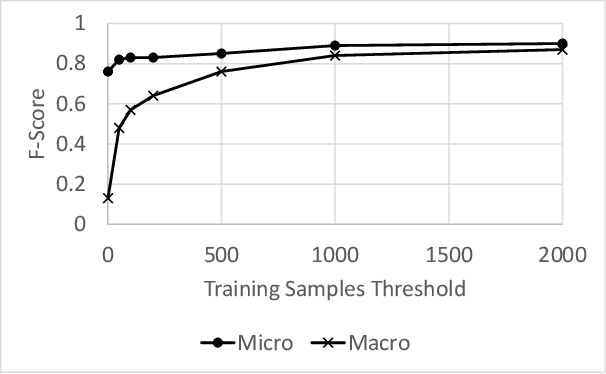
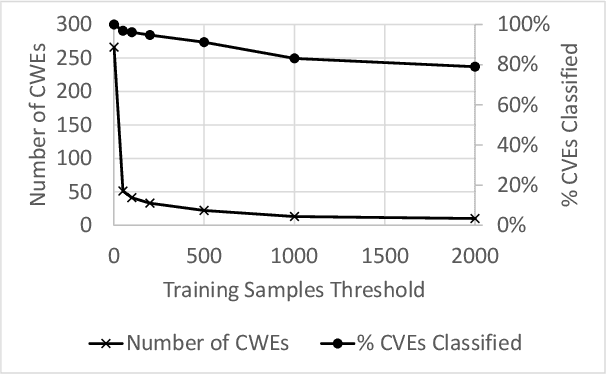
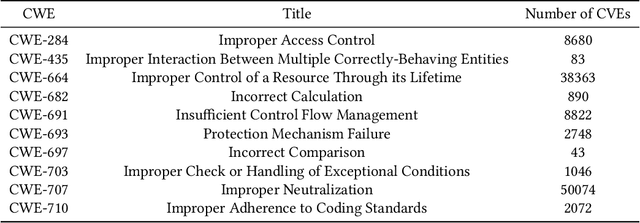
Modern organizations struggle with insurmountable number of vulnerabilities that are discovered and reported by their network and application vulnerability scanners. Therefore, prioritization and focus become critical, to spend their limited time on the highest risk vulnerabilities. In doing this, it is important for these organizations not only to understand the technical descriptions of the vulnerabilities, but also to gain insights into attackers' perspectives. In this work, we use machine learning and natural language processing techniques, as well as several publicly available data sets to provide an explainable mapping of vulnerabilities to attack techniques and threat actors. This work provides new security intelligence, by predicting which attack techniques are most likely to be used to exploit a given vulnerability and which threat actors are most likely to conduct the exploitation. Lack of labeled data and different vocabularies make mapping vulnerabilities to attack techniques at scale a challenging problem that cannot be addressed easily using supervised or unsupervised (similarity search) learning techniques. To solve this problem, we first map the vulnerabilities to a standard set of common weaknesses, and then common weaknesses to the attack techniques. This approach yields a Mean Reciprocal Rank (MRR) of 0.95, an accuracy comparable with those reported for state-of-the-art systems. Our solution has been deployed to IBM Security X-Force Red Vulnerability Management Services, and in production since 2021. The solution helps security practitioners to assist customers to manage and prioritize their vulnerabilities, providing them with an explainable mapping of vulnerabilities to attack techniques and threat actors