 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPS: Threat Actor Informed Prioritization of Applications using SecEncoder
Nov 12, 2024This paper introduces TIPS: Threat Actor Informed Prioritization using SecEncoder, a specialized language model for security. TIPS combines the strengths of both encoder and decoder language models to detect and prioritize compromised applications. By integrating threat actor intelligence, TIPS enhances the accuracy and relevance of its detections. Extensive experiments with a real-world benchmark dataset of applications demonstrate TIPS's high efficacy, achieving an F-1 score of 0.90 in identifying malicious applications. Additionally, in real-world scenarios, TIPS significantly reduces the backlog of investigations for security analysts by 87%, thereby streamlining the threat response process and improving overall security posture.
SecEncoder: Logs are All You Need in Security
Nov 12, 2024

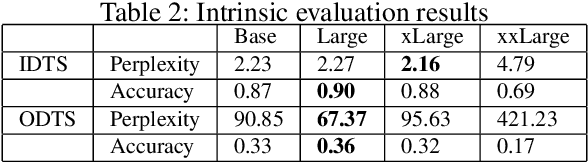

Large and Small Language Models (LMs) are typically pretrained using extensive volumes of text, which are sourced from publicly accessible platforms such as Wikipedia, Book Corpus, or through web scraping. These models, due to their exposure to a wide range of language data, exhibit impressive generalization capabilities and can perform a multitude of tasks simultaneously. However, they often fall short when it comes to domain-specific tasks due to their broad training data. This paper introduces SecEncoder, a specialized small language model that is pretrained using security logs. SecEncoder is designed to address the domain-specific limitations of general LMs by focusing on the unique language and patterns found in security logs. Experimental results indicate that SecEncoder outperforms other LMs, such as BERTlarge, DeBERTa-v3-large and OpenAI's Embedding (textembedding-ada-002) models, which are pretrained mainly on natural language, across various tasks. Furthermore, although SecEncoder is primarily pretrained on log data, it outperforms models pretrained on natural language for a range of tasks beyond log analysis, such as incident prioritization and threat intelligence document retrieval. This suggests that domain specific pretraining with logs can significantly enhance the performance of LMs in security. These findings pave the way for future research into security-specific LMs and their potential applications.
Predicting the Impact of Batch Refactoring Code Smells on Application Resource Consumption
Jun 27, 2023



Automated batch refactoring has become a de-facto mechanism to restructure software that may have significant design flaws negatively impacting the code quality and maintainability. Although automated batch refactoring techniques are known to significantly improve overall software quality and maintainability, their impact on resource utilization is not well studied. This paper aims to bridge the gap between batch refactoring code smells and consumption of resources. It determines the relationship between software code smell batch refactoring, and resource consumption. Next, it aims to design algorithms to predict the impact of code smell refactoring on resource consumption. This paper investigates 16 code smell types and their joint effect on resource utilization for 31 open source applications. It provides a detailed empirical analysis of the change in application CPU and memory utilization after refactoring specific code smells in isolation and in batches. This analysis is then used to train regression algorithms to predict the impact of batch refactoring on CPU and memory utilization before making any refactoring decisions. Experimental results also show that our ANN-based regression model provides highly accurate predictions for the impact of batch refactoring on resource consumption. It allows the software developers to intelligently decide which code smells they should refactor jointly to achieve high code quality and maintainability without increasing the application resource utilization. This paper responds to the important and urgent need of software engineers across a broad range of software applications, who are looking to refactor code smells and at the same time improve resource consumption. Finally, it brings forward the concept of resource aware code smell refactoring to the most crucial software applications.
Automated Compliance Blueprint Optimization with Artificial Intelligence
Jun 22, 2022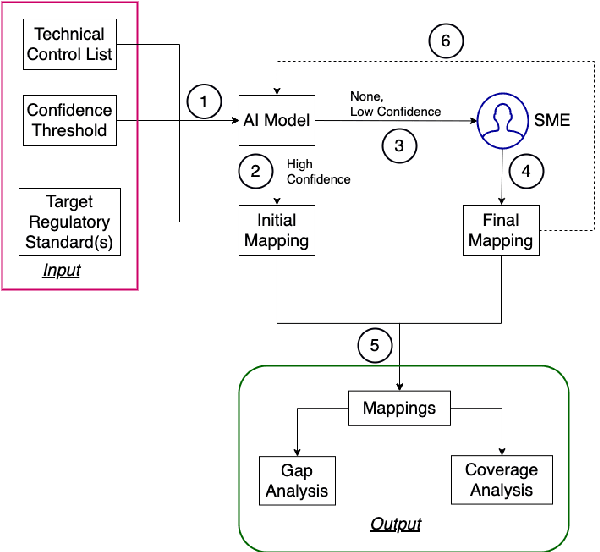
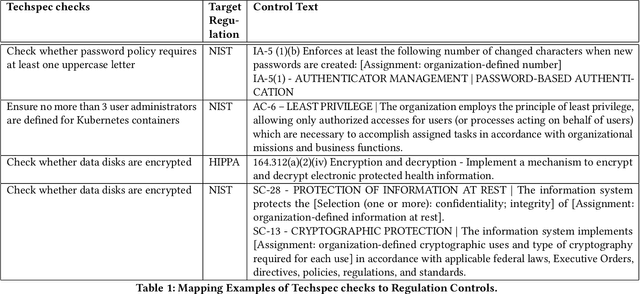
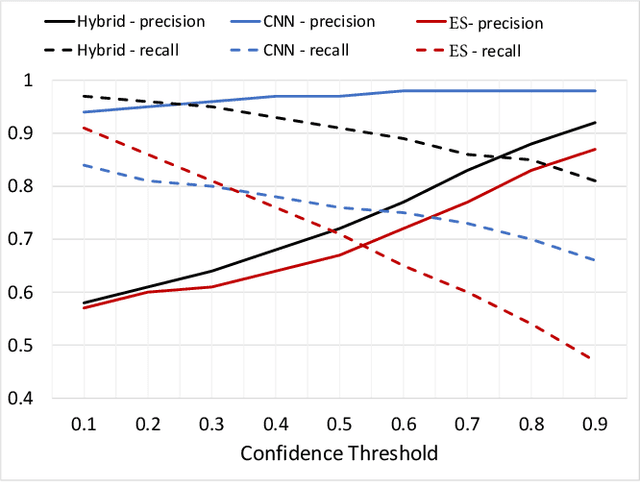
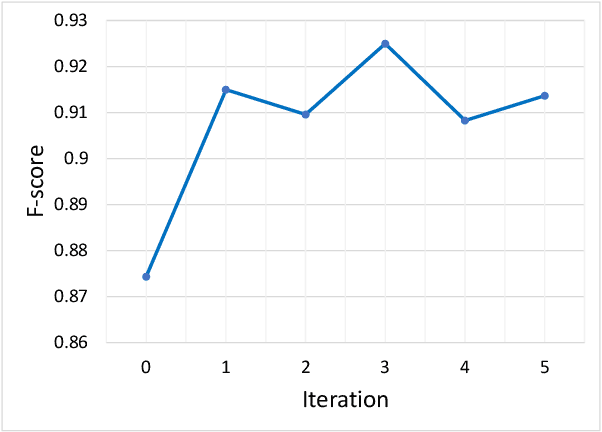
For highly regulated industries such as banking and healthcare, one of the major hindrances to the adoption of cloud computing is compliance with regulatory standards. This is a complex problem due to many regulatory and technical specification (techspec) documents that the companies need to comply with. The critical problem is to establish the mapping between techspecs and regulation controls so that from day one, companies can comply with regulations with minimal effort. We demonstrate the practicality of an approach to automatically analyze regulatory standards using Artificial Intelligence (AI) techniques. We present early results to identify the mapping between techspecs and regulation controls, and discuss challenges that must be overcome for this solution to be fully practical.
Vulnerability Prioritization: An Offensive Security Approach
Jun 22, 2022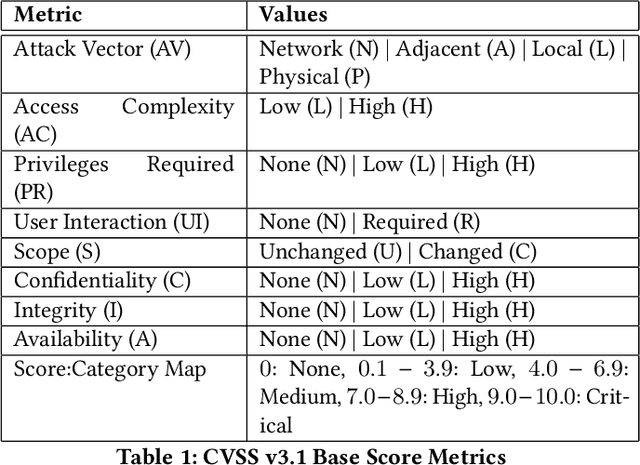
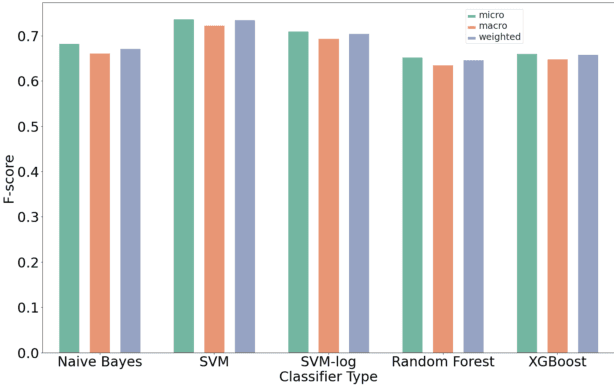

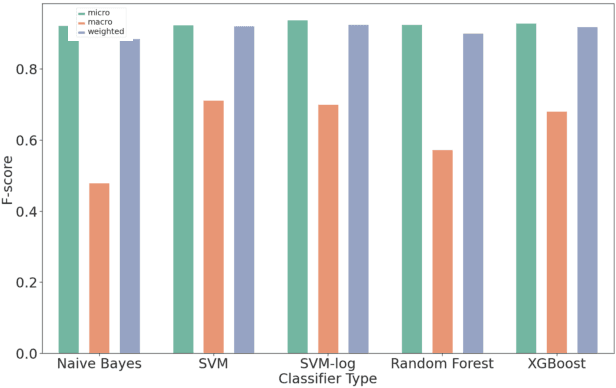
Organizations struggle to handle sheer number of vulnerabilities in their cloud environments. The de facto methodology used for prioritizing vulnerabilities is to use Common Vulnerability Scoring System (CVSS). However, CVSS has inherent limitations that makes it not ideal for prioritization. In this work, we propose a new way of prioritizing vulnerabilities. Our approach is inspired by how offensive security practitioners perform penetration testing. We evaluate our approach with a real world case study for a large client, and the accuracy of machine learning to automate the process end to end.
Attack Techniques and Threat Identification for Vulnerabilities
Jun 22, 2022
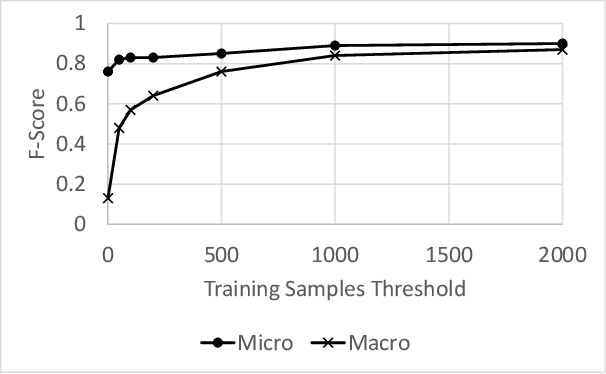
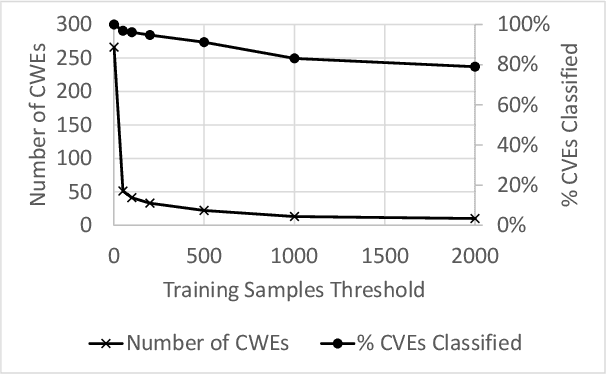
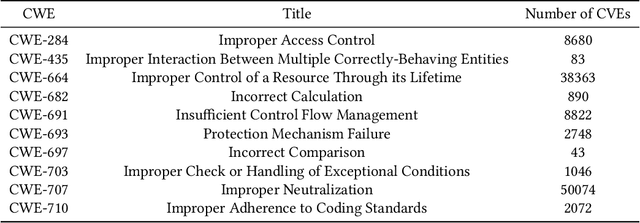
Modern organizations struggle with insurmountable number of vulnerabilities that are discovered and reported by their network and application vulnerability scanners. Therefore, prioritization and focus become critical, to spend their limited time on the highest risk vulnerabilities. In doing this, it is important for these organizations not only to understand the technical descriptions of the vulnerabilities, but also to gain insights into attackers' perspectives. In this work, we use machine learning and natural language processing techniques, as well as several publicly available data sets to provide an explainable mapping of vulnerabilities to attack techniques and threat actors. This work provides new security intelligence, by predicting which attack techniques are most likely to be used to exploit a given vulnerability and which threat actors are most likely to conduct the exploitation. Lack of labeled data and different vocabularies make mapping vulnerabilities to attack techniques at scale a challenging problem that cannot be addressed easily using supervised or unsupervised (similarity search) learning techniques. To solve this problem, we first map the vulnerabilities to a standard set of common weaknesses, and then common weaknesses to the attack techniques. This approach yields a Mean Reciprocal Rank (MRR) of 0.95, an accuracy comparable with those reported for state-of-the-art systems. Our solution has been deployed to IBM Security X-Force Red Vulnerability Management Services, and in production since 2021. The solution helps security practitioners to assist customers to manage and prioritize their vulnerabilities, providing them with an explainable mapping of vulnerabilities to attack techniques and threat actors