 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Impact of Batch Refactoring Code Smells on Application Resource Consumption
Jun 27, 2023



Automated batch refactoring has become a de-facto mechanism to restructure software that may have significant design flaws negatively impacting the code quality and maintainability. Although automated batch refactoring techniques are known to significantly improve overall software quality and maintainability, their impact on resource utilization is not well studied. This paper aims to bridge the gap between batch refactoring code smells and consumption of resources. It determines the relationship between software code smell batch refactoring, and resource consumption. Next, it aims to design algorithms to predict the impact of code smell refactoring on resource consumption. This paper investigates 16 code smell types and their joint effect on resource utilization for 31 open source applications. It provides a detailed empirical analysis of the change in application CPU and memory utilization after refactoring specific code smells in isolation and in batches. This analysis is then used to train regression algorithms to predict the impact of batch refactoring on CPU and memory utilization before making any refactoring decisions. Experimental results also show that our ANN-based regression model provides highly accurate predictions for the impact of batch refactoring on resource consumption. It allows the software developers to intelligently decide which code smells they should refactor jointly to achieve high code quality and maintainability without increasing the application resource utilization. This paper responds to the important and urgent need of software engineers across a broad range of software applications, who are looking to refactor code smells and at the same time improve resource consumption. Finally, it brings forward the concept of resource aware code smell refactoring to the most crucial software applications.
Scalable Manifold Learning for Big Data with Apache Spark
Aug 31, 2018



Non-linear spectral dimensionality reduction methods, such as Isomap, remain important technique for learning manifolds. However, due to computational complexity, exact manifold learning using Isomap is currently impossible from large-scale data. In this paper, we propose a distributed memory framework implementing end-to-end exact Isomap under Apache Spark model. We show how each critical step of the Isomap algorithm can be efficiently realized using basic Spark model, without the need to provision data in the secondary storage. We show how the entire method can be implemented using PySpark, offloading compute intensive linear algebra routines to BLAS. Through experimental results, we demonstrate excellent scalability of our method, and we show that it can process datasets orders of magnitude larger than what is currently possible, using a 25-node parallel~cluster.
Entropy-Isomap: Manifold Learning for High-dimensional Dynamic Processes
Aug 06, 2018
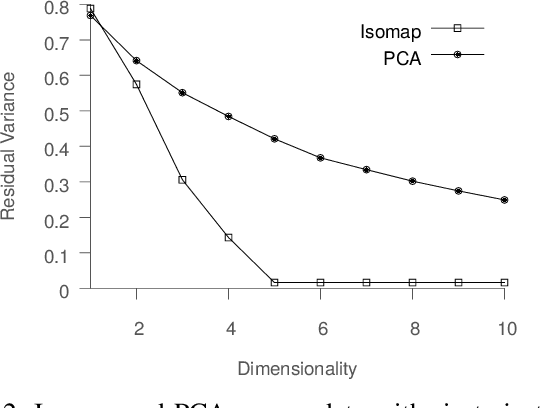

Scientific and engineering processes deliver massive high-dimensional data sets that are generated as non-linear transformations of an initial state and few process parameters. Mapping such data to a low-dimensional manifold facilitates better understanding of the underlying processes, and enables their optimization. In this paper, we first show that off-the-shelf non-linear spectral dimensionality reduction methods, e.g., Isomap, fail for such data, primarily due to the presence of strong temporal correlations. Then, we propose a novel method, Entropy-Isomap, to address the issue. The proposed method is successfully applied to large data describing a fabrication process of organic materials. The resulting low-dimensional representation correctly captures process control variables, allows for low-dimensional visualization of the material morphology evolution, and provides key insights to improve the process.
Fast Counting in Machine Learning Applications
Jun 26, 2018



We propose scalable methods to execute counting queries in machine learning applications. To achieve memory and computational efficiency, we abstract counting queries and their context such that the counts can be aggregated as a stream. We demonstrate performance and scalability of the resulting approach on random queries, and through extensive experimentation using Bayesian networks learning and association rule mining. Our methods significantly outperform commonly used ADtrees and hash tables, and are practical alternatives for processing large-scale data.
Scalable Exact Parent Sets Identification in Bayesian Networks Learning with Apache Spark
Oct 24, 2017



In Machine Learning, the parent set identification problem is to find a set of random variables that best explain selected variable given the data and some predefined scoring function. This problem is a critical component to structure learning of Bayesian networks and Markov blankets discovery, and thus has many practical applications, ranging from fraud detection to clinical decision support. In this paper, we introduce a new distributed memory approach to the exact parent sets assignment problem. To achieve scalability, we derive theoretical bounds to constraint the search space when MDL scoring function is used, and we reorganize the underlying dynamic programming such that the computational density is increased and fine-grain synchronization is eliminated. We then design efficient realization of our approach in the Apache Spark platform. Through experimental results, we demonstrate that the method maintains strong scalability on a 500-core standalone Spark cluster, and it can be used to efficiently process data sets with 70 variables, far beyond the reach of the currently available solutions.
Exact Structure Learning of Bayesian Networks by Optimal Path Extension
Mar 21, 2017



Bayesian networks are probabilistic graphical models often used in big data analytics. The problem of exact structure learning is to find a network structure that is optimal under certain scoring criteria. The problem is known to be NP-hard and the existing methods are both computationally and memory intensive. In this paper, we introduce a new approach for exact structure learning. Our strategy is to leverage relationship between a partial network structure and the remaining variables to constraint the number of ways in which the partial network can be optimally extended. Via experimental results, we show that the method provides up to three times improvement in runtime, and orders of magnitude reduction in memory consumption over the current best algorithms.
Error Metrics for Learning Reliable Manifolds from Streaming Data
Jan 11, 2017
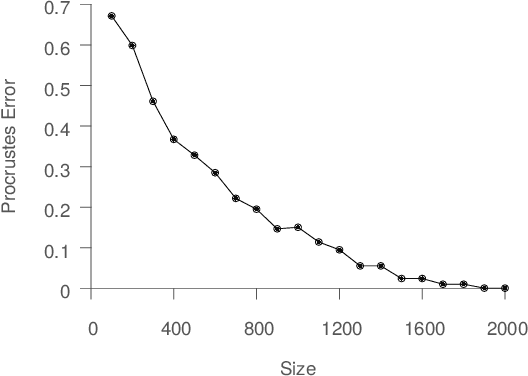
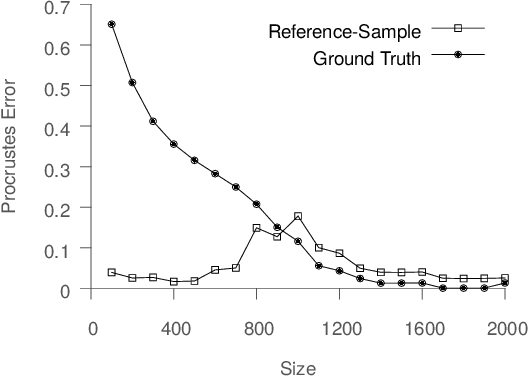

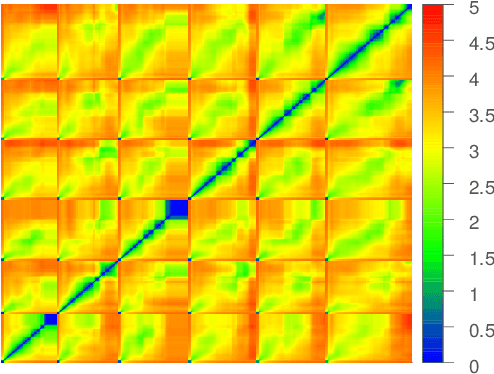
Spectral dimensionality reduction is frequently used to identify low-dimensional structure in high-dimensional data. However, learning manifolds, especially from the streaming data, is computationally and memory expensive. In this paper, we argue that a stable manifold can be learned using only a fraction of the stream, and the remaining stream can be mapped to the manifold in a significantly less costly manner. Identifying the transition point at which the manifold is stable is the key step. We present error metrics that allow us to identify the transition point for a given stream by quantitatively assessing the quality of a manifold learned using Isomap. We further propose an efficient mapping algorithm, called S-Isomap, that can be used to map new samples onto the stable manifold. We describe experiments on a variety of data sets that show that the proposed approach is computationally efficient without sacrificing accuracy.