 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Patient Care Trajectories with Transformer Hawkes Processes
Apr 07, 2026Patient healthcare utilization consists of irregularly time-stamped events, such as outpatient visits, inpatient admissions, and emergency encounters, forming individualized care trajectories. Modeling these trajectories is crucial for understanding utilization patterns and predicting future care needs, but is challenging due to temporal irregularity and severe class imbalance. In this work, we build on the Transformer Hawkes Process framework to model patient trajectories in continuous time. By combining Transformer-based history encoding with Hawkes process dynamics, the model captures event dependencies and jointly predicts event type and time-to-event. To address extreme imbalance, we introduce an imbalance-aware training strategy using inverse square-root class weighting. This improves sensitivity to rare but clinically important events without altering the data distribution. Experiments on real-world data demonstrate improved performance and provide clinically meaningful insights for identifying high-risk patient populations.
Large Deviations for Accelerating Neural Networks Training
Mar 02, 2023Artificial neural networks (ANNs) require tremendous amount of data to train on. However, in classification models, most data features are often similar which can lead to increase in training time without significant improvement in the performance. Thus, we hypothesize that there could be a more efficient way to train an ANN using a better representative sample. For this, we propose the LAD Improved Iterative Training (LIIT), a novel training approach for ANN using large deviations principle to generate and iteratively update training samples in a fast and efficient setting. This is exploratory work with extensive opportunities for future work. The thesis presents this ongoing research work with the following contributions from this study: (1) We propose a novel ANN training method, LIIT, based on the large deviations theory where additional dimensionality reduction is not needed to study high dimensional data. (2) The LIIT approach uses a Modified Training Sample (MTS) that is generated and iteratively updated using a LAD anomaly score based sampling strategy. (3) The MTS sample is designed to be well representative of the training data by including most anomalous of the observations in each class. This ensures distinct patterns and features are learnt with smaller samples. (4) We study the classification performance of the LIIT trained ANNs with traditional batch trained counterparts.
Geo-Adaptive Deep Spatio-Temporal predictive modeling for human mobility
Nov 27, 2022Deep learning approaches for spatio-temporal prediction problems such as crowd-flow prediction assumes data to be of fixed and regular shaped tensor and face challenges of handling irregular, sparse data tensor. This poses limitations in use-case scenarios such as predicting visit counts of individuals' for a given spatial area at a particular temporal resolution using raster/image format representation of the geographical region, since the movement patterns of an individual can be largely restricted and localized to a certain part of the raster. Additionally, current deep-learning approaches for solving such problem doesn't account for the geographical awareness of a region while modelling the spatio-temporal movement patterns of an individual. To address these limitations, there is a need to develop a novel strategy and modeling approach that can handle both sparse, irregular data while incorporating geo-awareness in the model. In this paper, we make use of quadtree as the data structure for representing the image and introduce a novel geo-aware enabled deep learning layer, GA-ConvLSTM that performs the convolution operation based on a novel geo-aware module based on quadtree data structure for incorporating spatial dependencies while maintaining the recurrent mechanism for accounting for temporal dependencies. We present this approach in the context of the problem of predicting spatial behaviors of an individual (e.g., frequent visits to specific locations) through deep-learning based predictive model, GADST-Predict. Experimental results on two GPS based trace data shows that the proposed method is effective in handling frequency visits over different use-cases with considerable high accuracy.
An Ensemble-Based Deep Framework for Estimating Thermo-Chemical State Variables from Flamelet Generated Manifolds
Nov 25, 2022
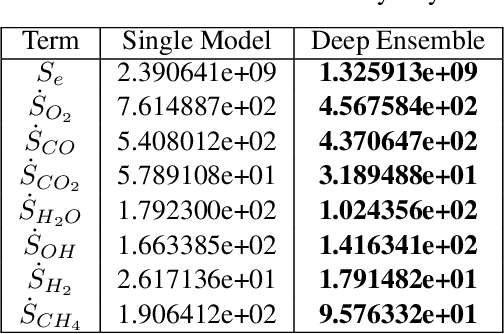
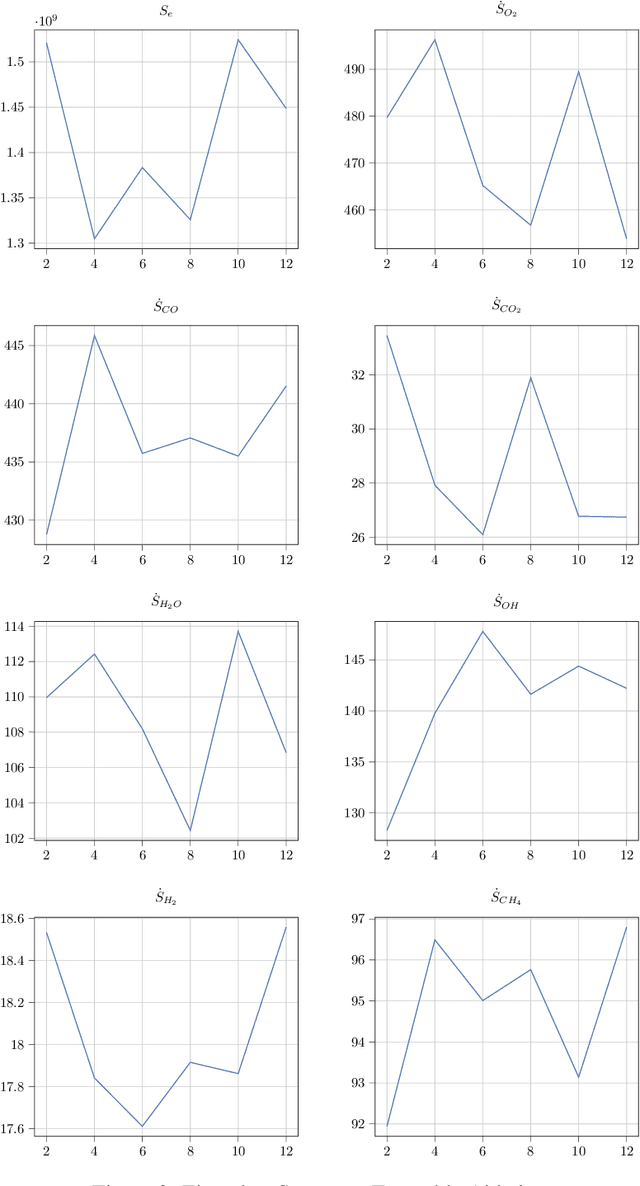
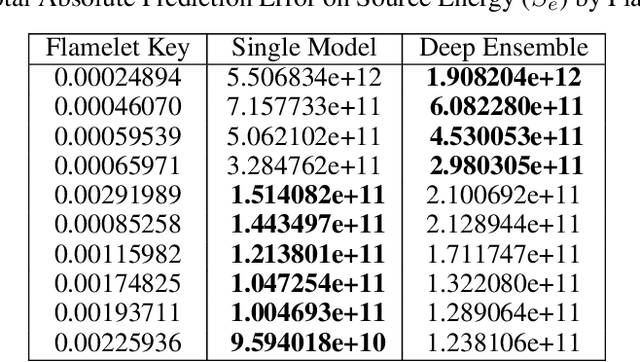
Complete computation of turbulent combustion flow involves two separate steps: mapping reaction kinetics to low-dimensional manifolds and looking-up this approximate manifold during CFD run-time to estimate the thermo-chemical state variables. In our previous work, we showed that using a deep architecture to learn the two steps jointly, instead of separately, is 73% more accurate at estimating the source energy, a key state variable, compared to benchmarks and can be integrated within a DNS turbulent combustion framework. In their natural form, such deep architectures do not allow for uncertainty quantification of the quantities of interest: the source energy and key species source terms. In this paper, we expand on such architectures, specifically ChemTab, by introducing deep ensembles to approximate the posterior distribution of the quantities of interest. We investigate two strategies of creating these ensemble models: one that keeps the flamelet origin information (Flamelets strategy) and one that ignores the origin and considers all the data independently (Points strategy). To train these models we used flamelet data generated by the GRI--Mech 3.0 methane mechanism, which consists of 53 chemical species and 325 reactions. Our results demonstrate that the Flamelets strategy is superior in terms of the absolute prediction error for the quantities of interest, but is reliant on the types of flamelets used to train the ensemble. The Points strategy is best at capturing the variability of the quantities of interest, independent of the flamelet types. We conclude that, overall, ChemTab Deep Ensembles allows for a more accurate representation of the source energy and key species source terms, compared to the model without these modifications.
Physics Informed Machine Learning for Chemistry Tabulation
Nov 06, 2022Modeling of turbulent combustion system requires modeling the underlying chemistry and the turbulent flow. Solving both systems simultaneously is computationally prohibitive. Instead, given the difference in scales at which the two sub-systems evolve, the two sub-systems are typically (re)solved separately. Popular approaches such as the Flamelet Generated Manifolds (FGM) use a two-step strategy where the governing reaction kinetics are pre-computed and mapped to a low-dimensional manifold, characterized by a few reaction progress variables (model reduction) and the manifold is then ``looked-up'' during the runtime to estimate the high-dimensional system state by the flow system. While existing works have focused on these two steps independently, in this work we show that joint learning of the progress variables and the look--up model, can yield more accurate results. We build on the base formulation and implementation ChemTab to include the dynamically generated Themochemical State Variables (Lower Dimensional Dynamic Source Terms). We discuss the challenges in the implementation of this deep neural network architecture and experimentally demonstrate it's superior performance.
ChemTab: A Physics Guided Chemistry Modeling Framework
Feb 20, 2022Modeling of turbulent combustion system requires modeling the underlying chemistry and the turbulent flow. Solving both systems simultaneously is computationally prohibitive. Instead, given the difference in scales at which the two sub-systems evolve, the two sub-systems are typically (re)solved separately. Popular approaches such as the Flamelet Generated Manifolds (FGM) use a two-step strategy where the governing reaction kinetics are pre-computed and mapped to a low-dimensional manifold, characterized by a few reaction progress variables (model reduction) and the manifold is then "looked-up" during the run-time to estimate the high-dimensional system state by the flow system. While existing works have focused on these two steps independently, we show that joint learning of the progress variables and the look-up model, can yield more accurate results. We propose a deep neural network architecture, called ChemTab, customized for the joint learning task and experimentally demonstrate its superiority over existing state-of-the-art methods.
Anomaly Detection for High-Dimensional Data Using Large Deviations Principle
Sep 28, 2021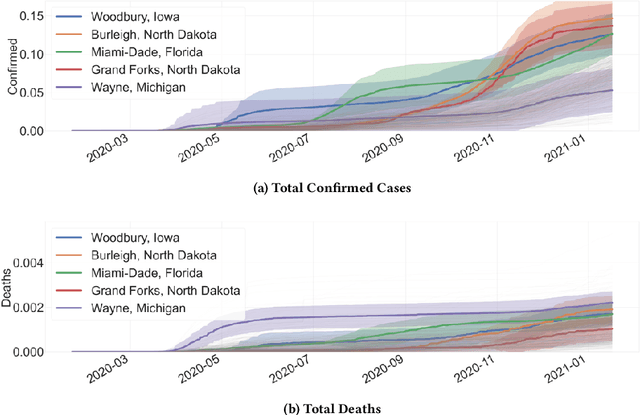
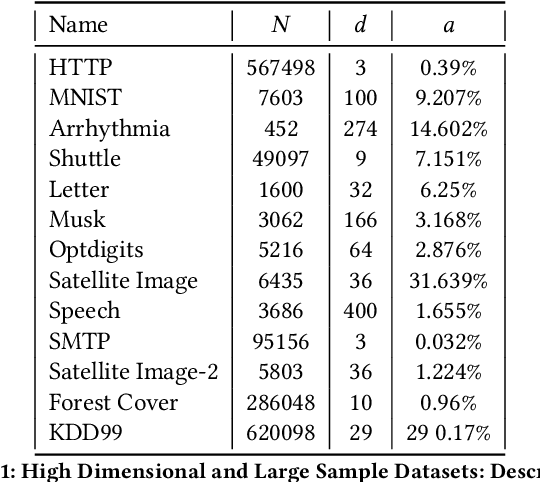

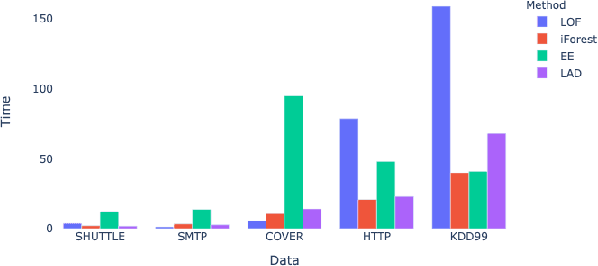
Most current anomaly detection methods suffer from the curse of dimensionality when dealing with high-dimensional data. We propose an anomaly detection algorithm that can scale to high-dimensional data using concepts from the theory of large deviations. The proposed Large Deviations Anomaly Detection (LAD) algorithm is shown to outperform state of art anomaly detection methods on a variety of large and high-dimensional benchmark data sets. Exploiting the ability of the algorithm to scale to high-dimensional data, we propose an online anomaly detection method to identify anomalies in a collection of multivariate time series. We demonstrate the applicability of the online algorithm in identifying counties in the United States with anomalous trends in terms of COVID-19 related cases and deaths. Several of the identified anomalous counties correlate with counties with documented poor response to the COVID pandemic.
From images in the wild to video-informed image classification
Sep 24, 2021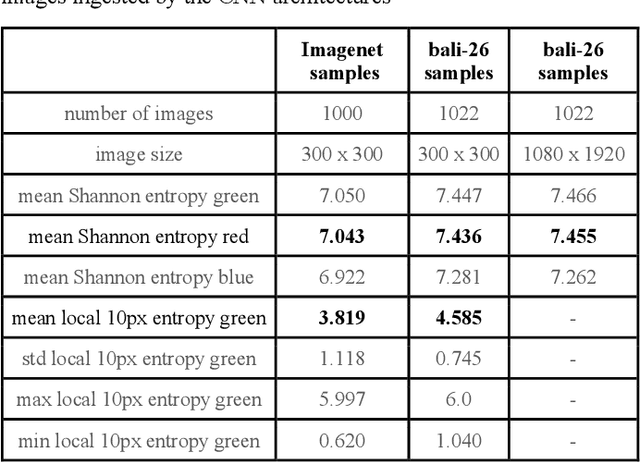



Image classifiers work effectively when applied on structured images, yet they often fail when applied on images with very high visual complexity. This paper describes experiments applying state-of-the-art object classifiers toward a unique set of images in the wild with high visual complexity collected on the island of Bali. The text describes differences between actual images in the wild and images from Imagenet, and then discusses a novel approach combining informational cues particular to video with an ensemble of imperfect classifiers in order to improve classification results on video sourced images of plants in the wild.
* 6 pages, 7 figures, supplemental materials
Integrated Clustering and Anomaly Detection (INCAD) for Streaming Data (Revised)
Nov 01, 2019
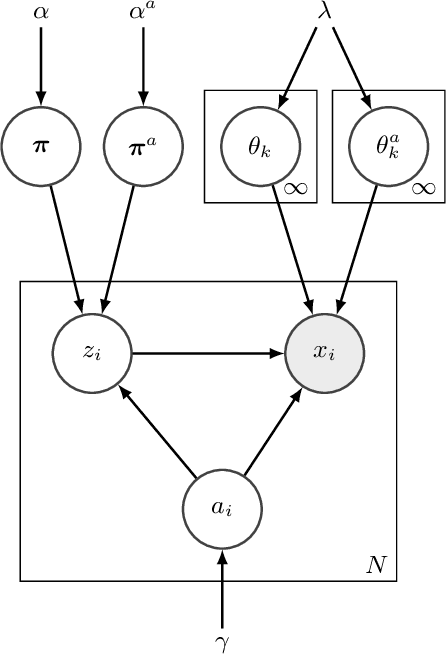
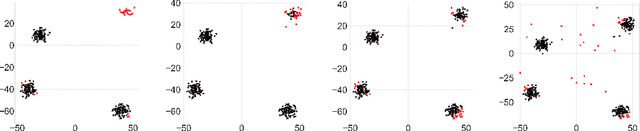

Most current clustering based anomaly detection methods use scoring schema and thresholds to classify anomalies. These methods are often tailored to target specific data sets with "known" number of clusters. The paper provides a streaming clustering and anomaly detection algorithm that does not require strict arbitrary thresholds on the anomaly scores or knowledge of the number of clusters while performing probabilistic anomaly detection and clustering simultaneously. This ensures that the cluster formation is not impacted by the presence of anomalous data, thereby leading to more reliable definition of "normal vs abnormal" behavior. The motivations behind developing the INCAD model and the path that leads to the streaming model is discussed.
* 13 pages; fixes typos in equations 5,6,9,10 on inference using Gibbs sampling
Bayesian Anomaly Detection Using Extreme Value Theory
May 29, 2019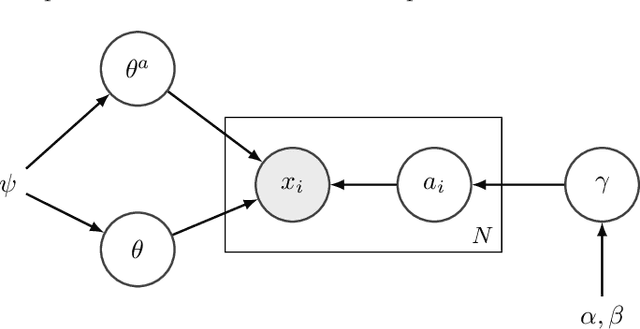


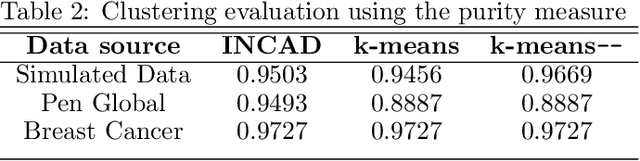
Data-driven anomaly detection methods typically build a model for the normal behavior of the target system, and score each data instance with respect to this model. A threshold is invariably needed to identify data instances with high (or low) scores as anomalies. This presents a practical limitation on the applicability of such methods, since most methods are sensitive to the choice of the threshold, and it is challenging to set optimal thresholds. We present a probabilistic framework to explicitly model the normal and anomalous behaviors and probabilistically reason about the data. An extreme value theory based formulation is proposed to model the anomalous behavior as the extremes of the normal behavior. As a specific instantiation, a joint non-parametric clustering and anomaly detection algorithm (INCAD) is proposed that models the normal behavior as a Dirichlet Process Mixture Model. A pseudo-Gibbs sampling based strategy is used for inference. Results on a variety of data sets show that the proposed method provides effective clustering and anomaly detection without requiring strong initialization and thresholding parameters.