 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Deviations for Accelerating Neural Networks Training
Mar 02, 2023Artificial neural networks (ANNs) require tremendous amount of data to train on. However, in classification models, most data features are often similar which can lead to increase in training time without significant improvement in the performance. Thus, we hypothesize that there could be a more efficient way to train an ANN using a better representative sample. For this, we propose the LAD Improved Iterative Training (LIIT), a novel training approach for ANN using large deviations principle to generate and iteratively update training samples in a fast and efficient setting. This is exploratory work with extensive opportunities for future work. The thesis presents this ongoing research work with the following contributions from this study: (1) We propose a novel ANN training method, LIIT, based on the large deviations theory where additional dimensionality reduction is not needed to study high dimensional data. (2) The LIIT approach uses a Modified Training Sample (MTS) that is generated and iteratively updated using a LAD anomaly score based sampling strategy. (3) The MTS sample is designed to be well representative of the training data by including most anomalous of the observations in each class. This ensures distinct patterns and features are learnt with smaller samples. (4) We study the classification performance of the LIIT trained ANNs with traditional batch trained counterparts.
Anomaly Detection for High-Dimensional Data Using Large Deviations Principle
Sep 28, 2021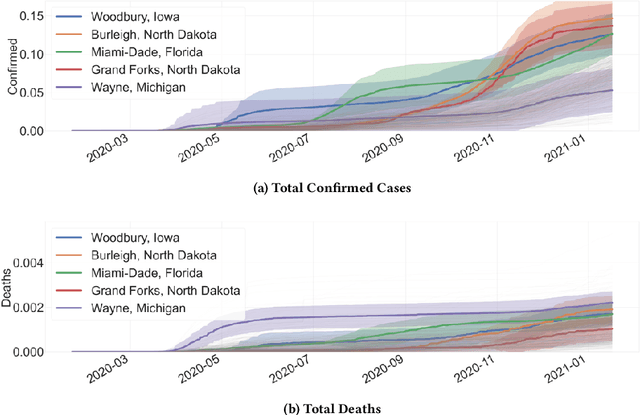
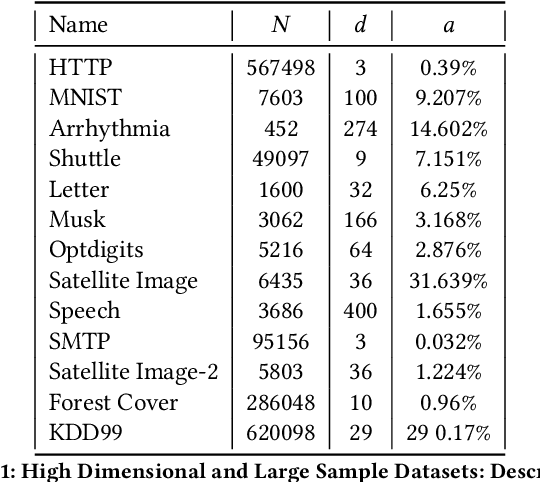

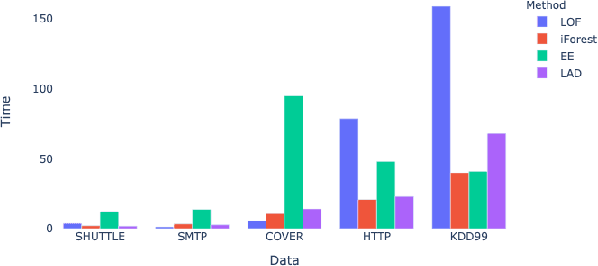
Most current anomaly detection methods suffer from the curse of dimensionality when dealing with high-dimensional data. We propose an anomaly detection algorithm that can scale to high-dimensional data using concepts from the theory of large deviations. The proposed Large Deviations Anomaly Detection (LAD) algorithm is shown to outperform state of art anomaly detection methods on a variety of large and high-dimensional benchmark data sets. Exploiting the ability of the algorithm to scale to high-dimensional data, we propose an online anomaly detection method to identify anomalies in a collection of multivariate time series. We demonstrate the applicability of the online algorithm in identifying counties in the United States with anomalous trends in terms of COVID-19 related cases and deaths. Several of the identified anomalous counties correlate with counties with documented poor response to the COVID pandemic.
Integrated Clustering and Anomaly Detection (INCAD) for Streaming Data (Revised)
Nov 01, 2019
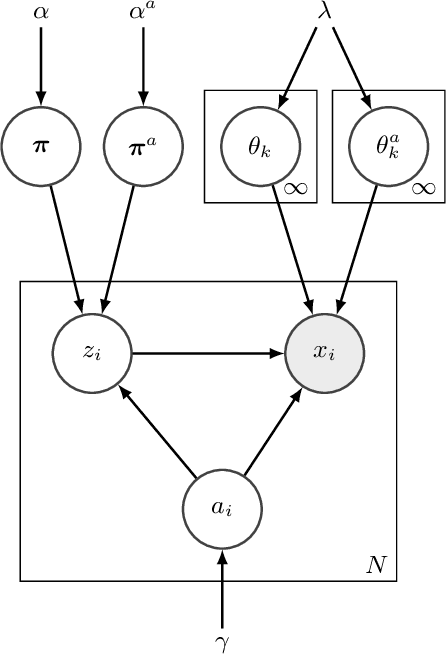

Most current clustering based anomaly detection methods use scoring schema and thresholds to classify anomalies. These methods are often tailored to target specific data sets with "known" number of clusters. The paper provides a streaming clustering and anomaly detection algorithm that does not require strict arbitrary thresholds on the anomaly scores or knowledge of the number of clusters while performing probabilistic anomaly detection and clustering simultaneously. This ensures that the cluster formation is not impacted by the presence of anomalous data, thereby leading to more reliable definition of "normal vs abnormal" behavior. The motivations behind developing the INCAD model and the path that leads to the streaming model is discussed.
* 13 pages; fixes typos in equations 5,6,9,10 on inference using Gibbs sampling
Bayesian Anomaly Detection Using Extreme Value Theory
May 29, 2019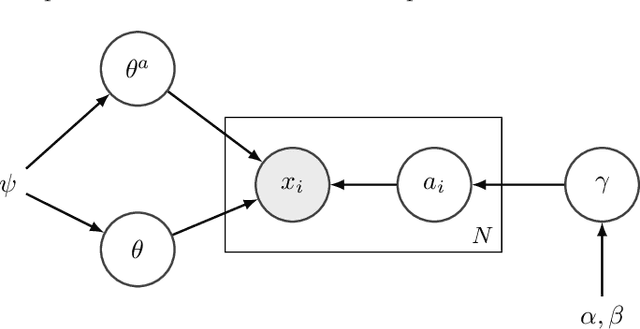


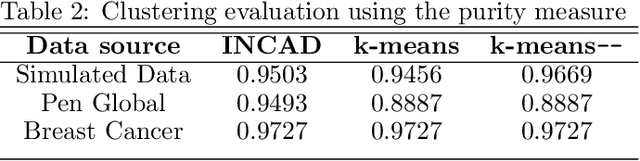
Data-driven anomaly detection methods typically build a model for the normal behavior of the target system, and score each data instance with respect to this model. A threshold is invariably needed to identify data instances with high (or low) scores as anomalies. This presents a practical limitation on the applicability of such methods, since most methods are sensitive to the choice of the threshold, and it is challenging to set optimal thresholds. We present a probabilistic framework to explicitly model the normal and anomalous behaviors and probabilistically reason about the data. An extreme value theory based formulation is proposed to model the anomalous behavior as the extremes of the normal behavior. As a specific instantiation, a joint non-parametric clustering and anomaly detection algorithm (INCAD) is proposed that models the normal behavior as a Dirichlet Process Mixture Model. A pseudo-Gibbs sampling based strategy is used for inference. Results on a variety of data sets show that the proposed method provides effective clustering and anomaly detection without requiring strong initialization and thresholding parameters.