 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Clustering and Anomaly Detection (INCAD) for Streaming Data (Revised)
Nov 01, 2019
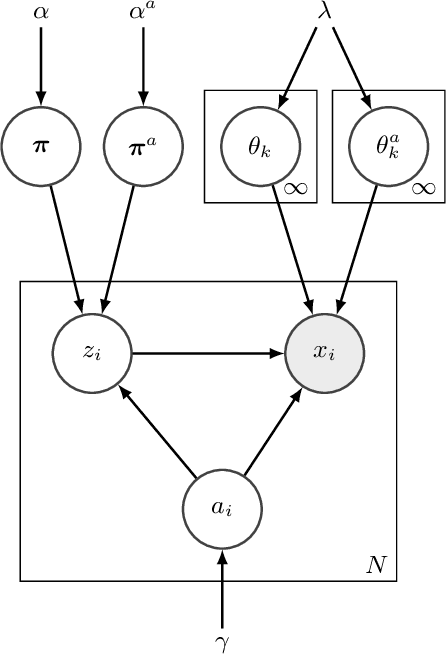
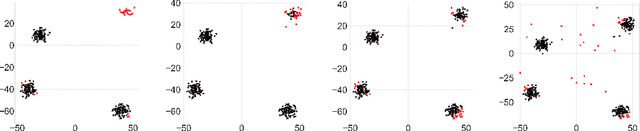

Most current clustering based anomaly detection methods use scoring schema and thresholds to classify anomalies. These methods are often tailored to target specific data sets with "known" number of clusters. The paper provides a streaming clustering and anomaly detection algorithm that does not require strict arbitrary thresholds on the anomaly scores or knowledge of the number of clusters while performing probabilistic anomaly detection and clustering simultaneously. This ensures that the cluster formation is not impacted by the presence of anomalous data, thereby leading to more reliable definition of "normal vs abnormal" behavior. The motivations behind developing the INCAD model and the path that leads to the streaming model is discussed.
* 13 pages; fixes typos in equations 5,6,9,10 on inference using Gibbs sampling