 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble-Based Deep Framework for Estimating Thermo-Chemical State Variables from Flamelet Generated Manifolds
Paper and Code
Nov 25, 2022
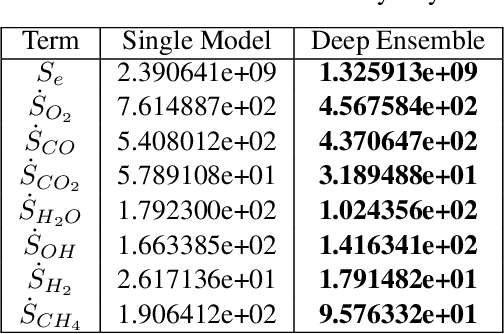
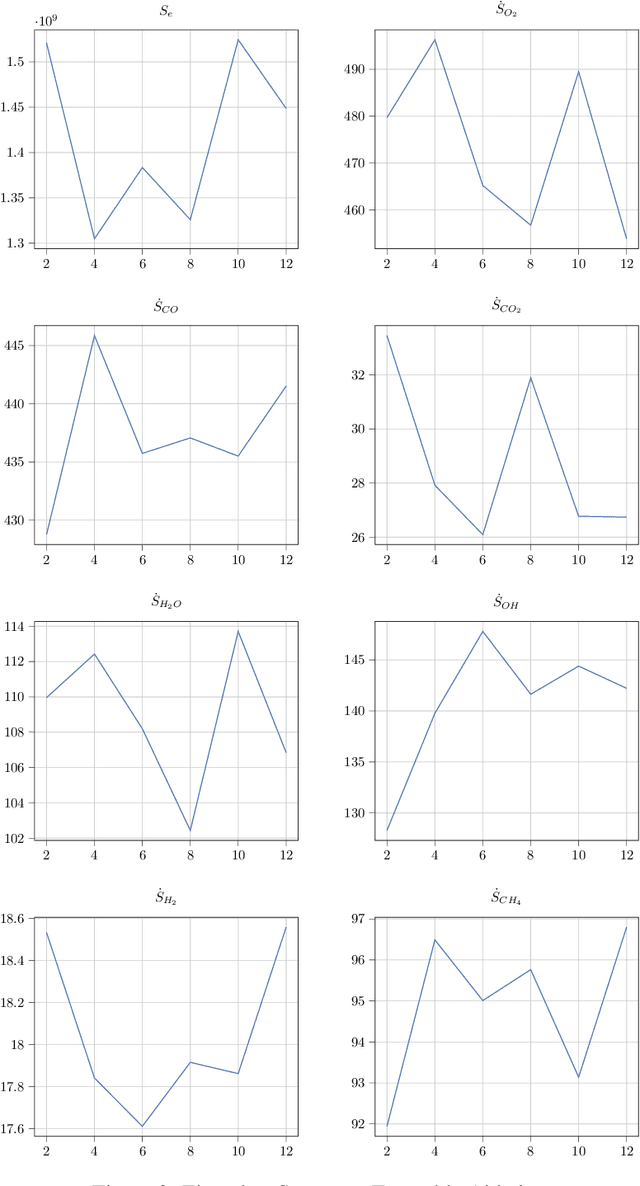
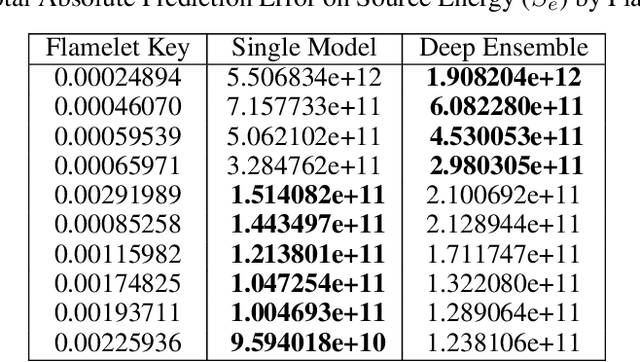
Complete computation of turbulent combustion flow involves two separate steps: mapping reaction kinetics to low-dimensional manifolds and looking-up this approximate manifold during CFD run-time to estimate the thermo-chemical state variables. In our previous work, we showed that using a deep architecture to learn the two steps jointly, instead of separately, is 73% more accurate at estimating the source energy, a key state variable, compared to benchmarks and can be integrated within a DNS turbulent combustion framework. In their natural form, such deep architectures do not allow for uncertainty quantification of the quantities of interest: the source energy and key species source terms. In this paper, we expand on such architectures, specifically ChemTab, by introducing deep ensembles to approximate the posterior distribution of the quantities of interest. We investigate two strategies of creating these ensemble models: one that keeps the flamelet origin information (Flamelets strategy) and one that ignores the origin and considers all the data independently (Points strategy). To train these models we used flamelet data generated by the GRI--Mech 3.0 methane mechanism, which consists of 53 chemical species and 325 reactions. Our results demonstrate that the Flamelets strategy is superior in terms of the absolute prediction error for the quantities of interest, but is reliant on the types of flamelets used to train the ensemble. The Points strategy is best at capturing the variability of the quantities of interest, independent of the flamelet types. We conclude that, overall, ChemTab Deep Ensembles allows for a more accurate representation of the source energy and key species source terms, compared to the model without these modifications.