 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Time-Aware LSTM Autoencoder on Chronic Kidney Disease
Paper and Code
Oct 01, 2018

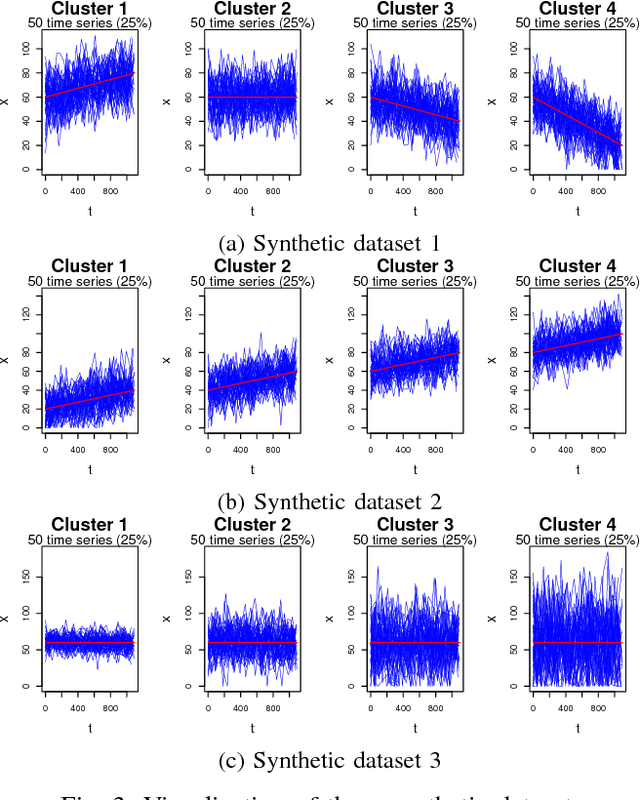
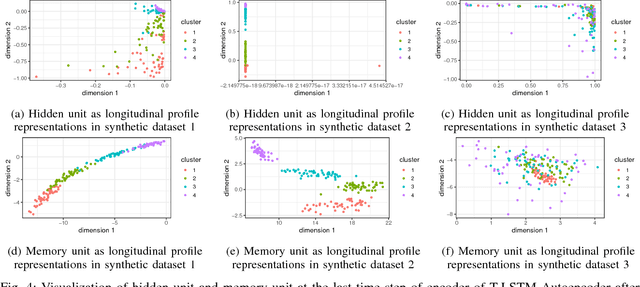
In this paper, we perform an empirical analysis on T-LSTM Auto-encoder - a model that can analyze a large dataset of irregularly sampled time series and project them into an embedded space. In particular, with three different synthetic datasets, we show that both memory unit and hidden unit of the last step in the encoder should be used as representation for a longitudinal profile. In addition, we perform a cross-validation to determine the dimension of the embedded representation - an important hyper-parameter of the model - when apply T-LSTM Auto-encoder into the real-world clinical datasets of patients having Chronic Kidney Disease (CKD). The analysis of the decoder outputs from the model shows that they not only capture well the long-term trends in the original data but also reduce the noise or fluctuation in the input data. Finally, we demonstrate that we can use the embedded representations of CKD patients learnt from T-LSTM Auto-encoder to identify interesting and unusual longitudinal profiles in CKD datasets.