 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Consumption of Dataframe Libraries for End-to-End Deep Learning Pipelines:A Comparative Analysis
Nov 17, 2025



This paper presents a detailed comparative analysis of the performance of three major Python data manipulation libraries - Pandas, Polars, and Dask - specifically when embedded within complete deep learning (DL) training and inference pipelines. The research bridges a gap in existing literature by studying how these libraries interact with substantial GPU workloads during critical phases like data loading, preprocessing, and batch feeding. The authors measured key performance indicators including runtime, memory usage, disk usage, and energy consumption (both CPU and GPU) across various machine learning models and datasets.
RapidGNN: Energy and Communication-Efficient Distributed Training on Large-Scale Graph Neural Networks
Sep 05, 2025

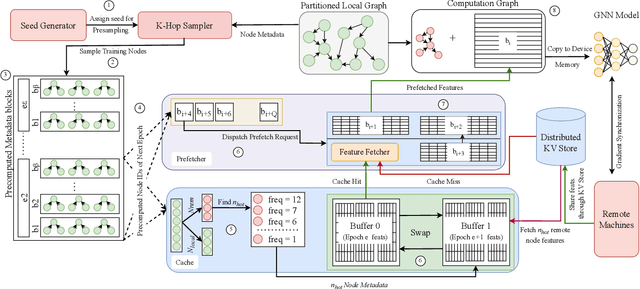

Graph Neural Networks (GNNs) have become popular across a diverse set of tasks in exploring structural relationships between entities. However, due to the highly connected structure of the datasets, distributed training of GNNs on large-scale graphs poses significant challenges. Traditional sampling-based approaches mitigate the computational loads, yet the communication overhead remains a challenge. This paper presents RapidGNN, a distributed GNN training framework with deterministic sampling-based scheduling to enable efficient cache construction and prefetching of remote features. Evaluation on benchmark graph datasets demonstrates RapidGNN's effectiveness across different scales and topologies. RapidGNN improves end-to-end training throughput by 2.46x to 3.00x on average over baseline methods across the benchmark datasets, while cutting remote feature fetches by over 9.70x to 15.39x. RapidGNN further demonstrates near-linear scalability with an increasing number of computing units efficiently. Furthermore, it achieves increased energy efficiency over the baseline methods for both CPU and GPU by 44% and 32%, respectively.
LL-GABR: Energy Efficient Live Video Streaming Using Reinforcement Learning
Feb 14, 2024Over the recent years, research and development in adaptive bitrate (ABR) algorithms for live video streaming have been successful in improving users' quality of experience (QoE) by reducing latency to near real-time levels while delivering higher bitrate videos with minimal rebuffering time. However, the QoE models used by these ABR algorithms do not take into account that a large portion of live video streaming clients use mobile devices where a higher bitrate does not necessarily translate into higher perceived quality. Ignoring perceived quality results in playing videos at higher bitrates without a significant increase in perceptual video quality and becomes a burden for battery-constrained mobile devices due to higher energy consumption. In this paper, we propose LL-GABR, a deep reinforcement learning approach that models the QoE using perceived video quality instead of bitrate and uses energy consumption along with other metrics like latency, rebuffering events, and smoothness. LL-GABR makes no assumptions about the underlying video, environment, or network settings and can operate flexibly on different video titles, each having a different bitrate encoding ladder without additional re-training, unlike existing learning-based ABRs. Trace-driven experimental results show that LL-GABR outperforms the state-of-the-art approaches by up to 44% in terms of perceptual QoE and a 73% increase in energy efficiency as a result of reducing net energy consumption by 11%.
URegM: a unified prediction model of resource consumption for refactoring software smells in open source cloud
Oct 22, 2023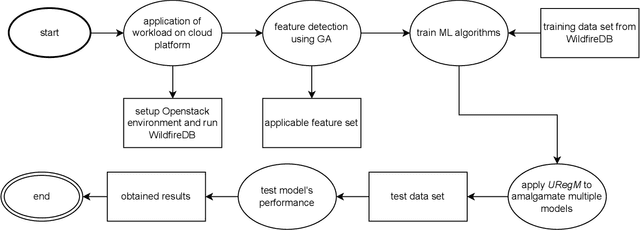



The low cost and rapid provisioning capabilities have made the cloud a desirable platform to launch complex scientific applications. However, resource utilization optimization is a significant challenge for cloud service providers, since the earlier focus is provided on optimizing resources for the applications that run on the cloud, with a low emphasis being provided on optimizing resource utilization of the cloud computing internal processes. Code refactoring has been associated with improving the maintenance and understanding of software code. However, analyzing the impact of the refactoring source code of the cloud and studying its impact on cloud resource usage require further analysis. In this paper, we propose a framework called Unified Regression Modelling (URegM) which predicts the impact of code smell refactoring on cloud resource usage. We test our experiments in a real-life cloud environment using a complex scientific application as a workload. Results show that URegM is capable of accurately predicting resource consumption due to code smell refactoring. This will permit cloud service providers with advanced knowledge about the impact of refactoring code smells on resource consumption, thus allowing them to plan their resource provisioning and code refactoring more effectively.
Predicting the Impact of Batch Refactoring Code Smells on Application Resource Consumption
Jun 27, 2023



Automated batch refactoring has become a de-facto mechanism to restructure software that may have significant design flaws negatively impacting the code quality and maintainability. Although automated batch refactoring techniques are known to significantly improve overall software quality and maintainability, their impact on resource utilization is not well studied. This paper aims to bridge the gap between batch refactoring code smells and consumption of resources. It determines the relationship between software code smell batch refactoring, and resource consumption. Next, it aims to design algorithms to predict the impact of code smell refactoring on resource consumption. This paper investigates 16 code smell types and their joint effect on resource utilization for 31 open source applications. It provides a detailed empirical analysis of the change in application CPU and memory utilization after refactoring specific code smells in isolation and in batches. This analysis is then used to train regression algorithms to predict the impact of batch refactoring on CPU and memory utilization before making any refactoring decisions. Experimental results also show that our ANN-based regression model provides highly accurate predictions for the impact of batch refactoring on resource consumption. It allows the software developers to intelligently decide which code smells they should refactor jointly to achieve high code quality and maintainability without increasing the application resource utilization. This paper responds to the important and urgent need of software engineers across a broad range of software applications, who are looking to refactor code smells and at the same time improve resource consumption. Finally, it brings forward the concept of resource aware code smell refactoring to the most crucial software applications.
A Reinforcement Learning Approach to Optimize Available Network Bandwidth Utilization
Dec 01, 2022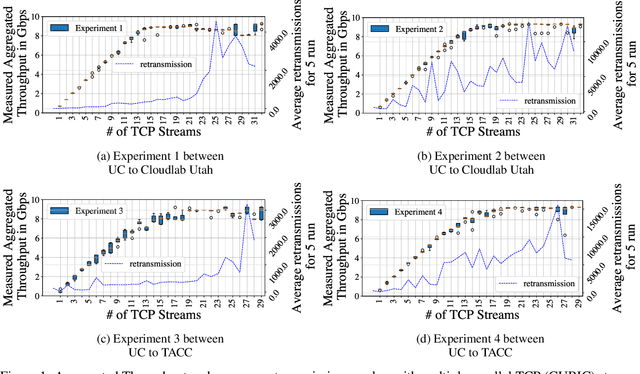



Efficient data transfers over high-speed, long-distance shared networks require proper utilization of available network bandwidth. Using parallel TCP streams enables an application to utilize network parallelism and can improve transfer throughput; however, finding the optimum number of parallel TCP streams is challenging due to nondeterministic background traffic sharing the same network. Additionally, the non-stationary, multi-objectiveness, and partially-observable nature of network signals in the host systems add extra complexity in finding the current network condition. In this work, we present a novel approach to finding the optimum number of parallel TCP streams using deep reinforcement learning (RL). We devise a learning-based algorithm capable of generalizing different network conditions and utilizing the available network bandwidth intelligently. Contrary to rule-based heuristics that do not generalize well in unknown network scenarios, our RL-based solution can dynamically discover and adapt the parallel TCP stream numbers to maximize the network bandwidth utilization without congesting the network and ensure fairness among contending transfers. We extensively evaluated our RL-based algorithm's performance, comparing it with several state-of-the-art online optimization algorithms. The results show that our RL-based algorithm can find near-optimal solutions 40% faster while achieving up to 15% higher throughput. We also show that, unlike a greedy algorithm, our devised RL-based algorithm can avoid network congestion and fairly share the available network resources among contending transfers.
Software Sustainability: A Systematic Literature Review and Comprehensive Analysis
Oct 11, 2019
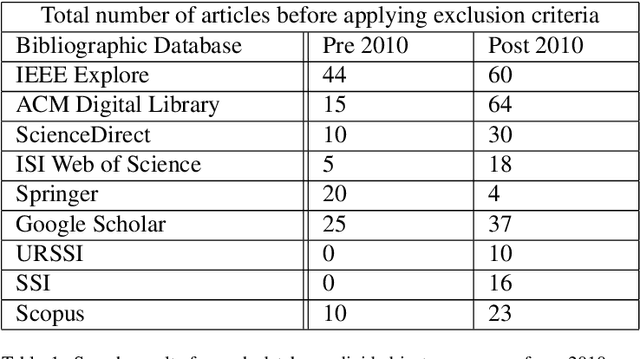

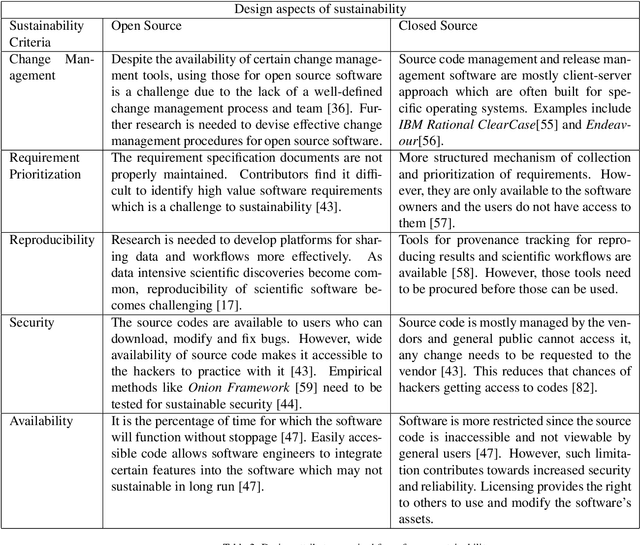
Software Engineering is a constantly evolving subject area that faces new challenges every day as it tries to automate newer business processes. One of the key challenges to the success of a software solution is attaining sustainability. The inability of numerous software to sustain for the desired time-length is caused by limited consideration given towards sustainability during the stages of software development. This review aims to present a detailed and inclusive study covering both the technical and non-technical challenges and approaches of software sustainability. A systematic and comprehensive literature review was conducted based on 107 relevant studies that were selected using the Evidence-Based Software Engineering (EBSE) technique. The study showed that sustainability can be achieved by conducting specific activities at the technical and non-technical levels. The technical level consists of software design, coding, and user experience attributes. The non-technical level consists of documentation, sustainability manifestos, training of software engineers, funding software projects, and leadership skills of project managers to achieve sustainability. This paper groups the existing research efforts based on the above aspects. Next, how those aspects affect open and closed source software is tabulated. Based on the findings of this review, it is seen that both technical and non-technical sustainability aspects are equally important, taking one into contention and ignoring the other will threaten the sustenance of software products.