 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-Perturbed: Domain Randomization Reveals Systematic Brittleness in GUI Grounding Models
Apr 15, 2026GUI grounding models report over 85% accuracy on standard benchmarks, yet drop 27-56 percentage points when instructions require spatial reasoning rather than direct element naming. Current benchmarks miss this because they evaluate each screenshot once with a single fixed instruction. We introduce GUI-Perturbed, a controlled perturbation framework that independently varies visual scenes and instructions to measure grounding robustness. Evaluating three 7B models from the same architecture lineage, we find that relational instructions cause systematic accuracy collapse across all models, a 70% browser zoom produces statistically significant degradation, and rank-8 LoRA fine-tuning with augmented data degrades performance rather than improving it. By perturbing along independent axes, GUI-Perturbed isolates which specific capability axes are affected-spatial reasoning, visual robustness, reasoning calibration-providing diagnostic signal that aggregate benchmarks cannot. We release the dataset, augmentation pipeline, and a fine-tuned model.
Benchmarking the Generality of Vision-Language-Action Models
Dec 12, 2025Generalist multimodal agents are expected to unify perception, language, and control - operating robustly across diverse real world domains. However, current evaluation practices remain fragmented across isolated benchmarks, making it difficult to assess whether today's foundation models truly generalize beyond their training distributions. We introduce MultiNet v1.0, a unified benchmark for measuring the cross domain generality of vision language models (VLMs) and vision language action models (VLAs) across six foundational capability regimes. Visual grounding, spatial reasoning, tool use, physical commonsense, multi agent coordination, and continuous robot control. Evaluating GPT 5, Pi0, and Magma, we find that no model demonstrates consistent generality. All exhibit substantial degradation on unseen domains, unfamiliar modalities, or cross domain task shifts despite strong performance within their training distributions.These failures manifest as modality misalignment, output format instability, and catastrophic knowledge degradation under domain transfer.Our findings reveal a persistent gap between the aspiration of generalist intelligence and the actual capabilities of current foundation models.MultiNet v1.0 provides a standardized evaluation substrate for diagnosing these gaps and guiding the development of future generalist agents.Code, data, and leaderboards are publicly available.
MultiNet: An Open-Source Software Toolkit \& Benchmark Suite for the Evaluation and Adaptation of Multimodal Action Models
Jun 10, 2025Recent innovations in multimodal action models represent a promising direction for developing general-purpose agentic systems, combining visual understanding, language comprehension, and action generation. We introduce MultiNet - a novel, fully open-source benchmark and surrounding software ecosystem designed to rigorously evaluate and adapt models across vision, language, and action domains. We establish standardized evaluation protocols for assessing vision-language models (VLMs) and vision-language-action models (VLAs), and provide open source software to download relevant data, models, and evaluations. Additionally, we provide a composite dataset with over 1.3 trillion tokens of image captioning, visual question answering, commonsense reasoning, robotic control, digital game-play, simulated locomotion/manipulation, and many more tasks. The MultiNet benchmark, framework, toolkit, and evaluation harness have been used in downstream research on the limitations of VLA generalization.
Benchmarking Vision, Language, & Action Models in Procedurally Generated, Open Ended Action Environments
May 08, 2025Vision-language-action (VLA) models represent an important step toward general-purpose robotic systems by integrating visual perception, language understanding, and action execution. However, systematic evaluation of these models, particularly their zero-shot generalization capabilities in out-of-distribution (OOD) environments, remains limited. In this paper, we introduce MultiNet v0.2, a comprehensive benchmark designed to evaluate and analyze the generalization performance of state-of-the-art VLM and VLA models-including GPT-4o, GPT-4.1, OpenVLA,Pi0 Base, and Pi0 FAST-on diverse procedural tasks from the Procgen benchmark. Our analysis reveals several critical insights: (1) all evaluated models exhibit significant limitations in zero-shot generalization to OOD tasks, with performance heavily influenced by factors such as action representation and task complexit; (2) VLAs generally outperform other models due to their robust architectural design; and (3) VLM variants demonstrate substantial improvements when constrained appropriately, highlighting the sensitivity of model performance to precise prompt engineering.
KULCQ: An Unsupervised Keyword-based Utterance Level Clustering Quality Metric
Nov 15, 2024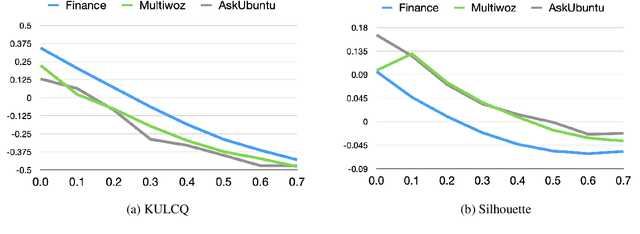


Intent discovery is crucial for both building new conversational agents and improving existing ones. While several approaches have been proposed for intent discovery, most rely on clustering to group similar utterances together. Traditional evaluation of these utterance clusters requires intent labels for each utterance, limiting scalability. Although some clustering quality metrics exist that do not require labeled data, they focus solely on cluster geometry while ignoring the linguistic nuances present in conversational transcripts. In this paper, we introduce Keyword-based Utterance Level Clustering Quality (KULCQ), an unsupervised metric that leverages keyword analysis to evaluate clustering quality. We demonstrate KULCQ's effectiveness by comparing it with existing unsupervised clustering metrics and validate its performance through comprehensive ablation studies. Our results show that KULCQ better captures semantic relationships in conversational data while maintaining consistency with geometric clustering principles.
Jill Watson: A Virtual Teaching Assistant powered by ChatGPT
May 17, 2024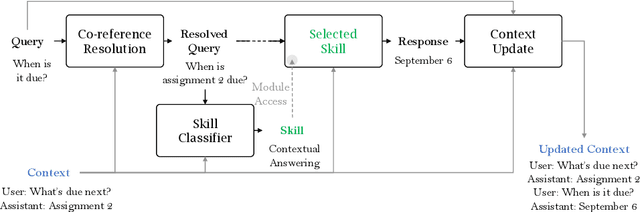

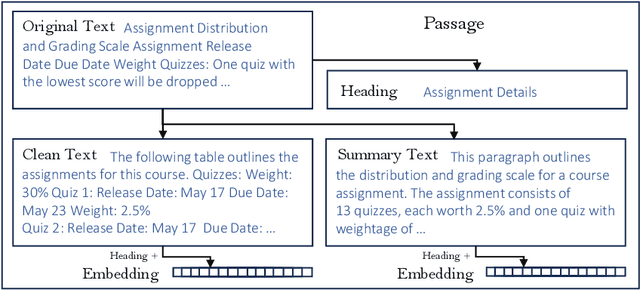

Conversational AI agents often require extensive datasets for training that are not publicly released, are limited to social chit-chat or handling a specific domain, and may not be easily extended to accommodate the latest advances in AI technologies. This paper introduces Jill Watson, a conversational Virtual Teaching Assistant (VTA) leveraging the capabilities of ChatGPT. Jill Watson based on ChatGPT requires no prior training and uses a modular design to allow the integration of new APIs using a skill-based architecture inspired by XiaoIce. Jill Watson is also well-suited for intelligent textbooks as it can process and converse using multiple large documents. We exclusively utilize publicly available resources for reproducibility and extensibility. Comparative analysis shows that our system outperforms the legacy knowledge-based Jill Watson as well as the OpenAI Assistants service. We employ many safety measures that reduce instances of hallucinations and toxicity. The paper also includes real-world examples from a classroom setting that demonstrate different features of Jill Watson and its effectiveness.
An end-to-end, interactive Deep Learning based Annotation system for cursive and print English handwritten text
Apr 18, 2023With the surging inclination towards carrying out tasks on computational devices and digital mediums, any method that converts a task that was previously carried out manually, to a digitized version, is always welcome. Irrespective of the various documentation tasks that can be done online today, there are still many applications and domains where handwritten text is inevitable, which makes the digitization of handwritten documents a very essential task. Over the past decades, there has been extensive research on offline handwritten text recognition. In the recent past, most of these attempts have shifted to Machine learning and Deep learning based approaches. In order to design more complex and deeper networks, and ensure stellar performances, it is essential to have larger quantities of annotated data. Most of the databases present for offline handwritten text recognition today, have either been manually annotated or semi automatically annotated with a lot of manual involvement. These processes are very time consuming and prone to human errors. To tackle this problem, we present an innovative, complete end-to-end pipeline, that annotates offline handwritten manuscripts written in both print and cursive English, using Deep Learning and User Interaction techniques. This novel method, which involves an architectural combination of a detection system built upon a state-of-the-art text detection model, and a custom made Deep Learning model for the recognition system, is combined with an easy-to-use interactive interface, aiming to improve the accuracy of the detection, segmentation, serialization and recognition phases, in order to ensure high quality annotated data with minimal human interaction.