 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Bilingual End-to-End ASR model using Attention over Multiple Softmax
Jan 22, 2024



Even with several advancements in multilingual modeling, it is challenging to recognize multiple languages using a single neural model, without knowing the input language and most multilingual models assume the availability of the input language. In this work, we propose a novel bilingual end-to-end (E2E) modeling approach, where a single neural model can recognize both languages and also support switching between the languages, without any language input from the user. The proposed model has shared encoder and prediction networks, with language-specific joint networks that are combined via a self-attention mechanism. As the language-specific posteriors are combined, it produces a single posterior probability over all the output symbols, enabling a single beam search decoding and also allowing dynamic switching between the languages. The proposed approach outperforms the conventional bilingual baseline with 13.3%, 8.23% and 1.3% word error rate relative reduction on Hindi, English and code-mixed test sets, respectively.
* Published in IEEE's Spoken Language Technology (SLT) 2022, 8 pages (6 + 2 for references), 5 figures
End-to-End ASR for Code-switched Hindi-English Speech
Jun 22, 2019
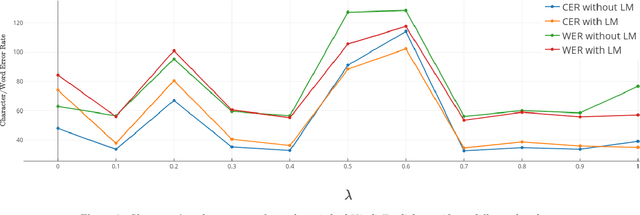
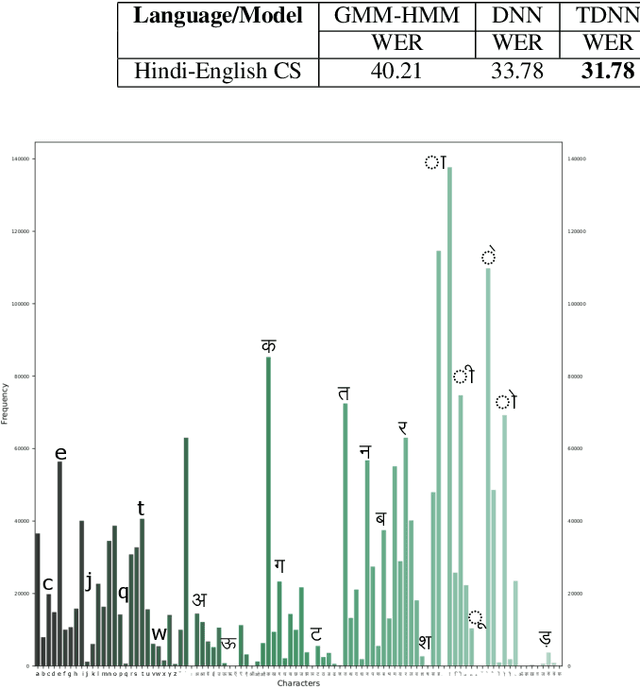
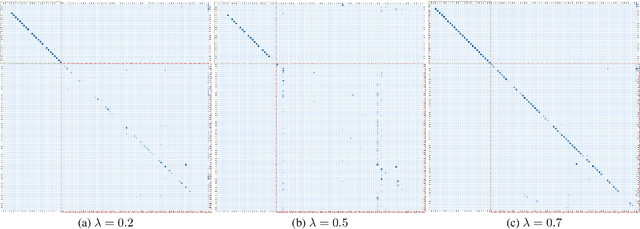
End-to-end (E2E) models have been explored for large speech corpora and have been found to match or outperform traditional pipeline-based systems in some languages. However, most prior work on end-to-end models use speech corpora exceeding hundreds or thousands of hours. In this study, we explore end-to-end models for code-switched Hindi-English language with less than 50 hours of data. We utilize two specific measures to improve network performance in the low-resource setting, namely multi-task learning (MTL) and balancing the corpus to deal with the inherent class imbalance problem i.e. the skewed frequency distribution over graphemes. We compare the results of the proposed approaches with traditional, cascaded ASR systems. While the lack of data adversely affects the performance of end-to-end models, we see promising improvements with MTL and balancing the corpus.
Vision and Learning for Deliberative Monocular Cluttered Flight
Nov 24, 2014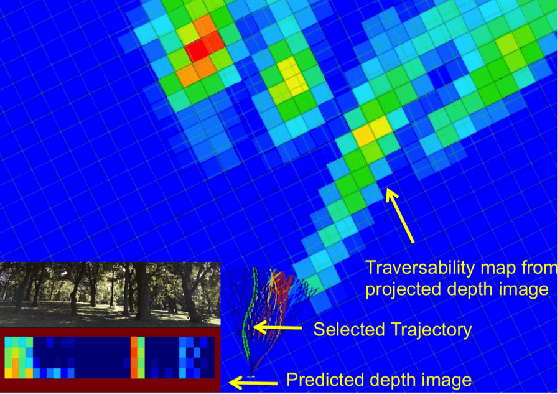
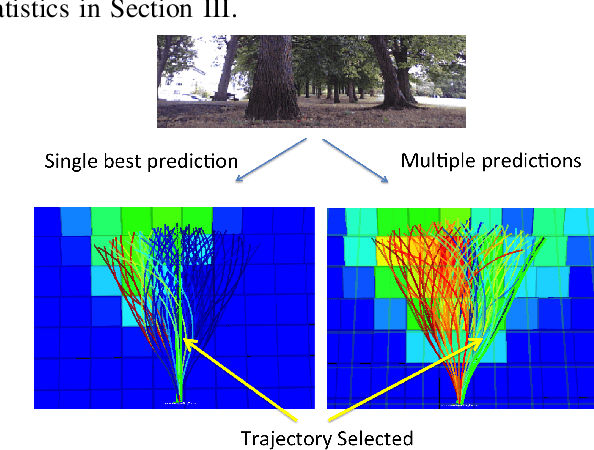
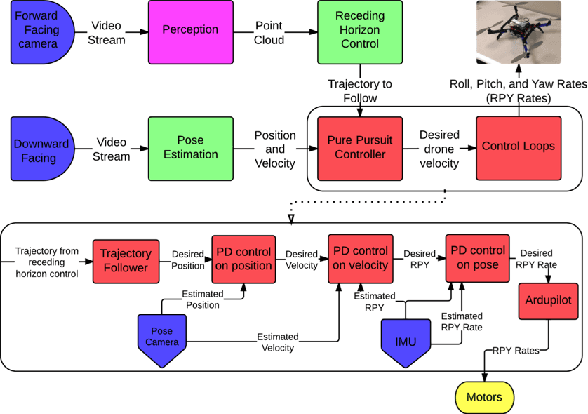
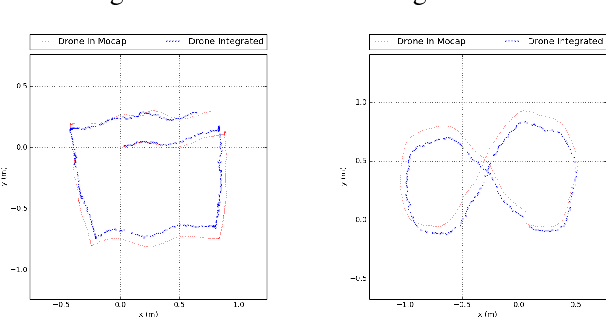
Cameras provide a rich source of information while being passive, cheap and lightweight for small and medium Unmanned Aerial Vehicles (UAVs). In this work we present the first implementation of receding horizon control, which is widely used in ground vehicles, with monocular vision as the only sensing mode for autonomous UAV flight in dense clutter. We make it feasible on UAVs via a number of contributions: novel coupling of perception and control via relevant and diverse, multiple interpretations of the scene around the robot, leveraging recent advances in machine learning to showcase anytime budgeted cost-sensitive feature selection, and fast non-linear regression for monocular depth prediction. We empirically demonstrate the efficacy of our novel pipeline via real world experiments of more than 2 kms through dense trees with a quadrotor built from off-the-shelf parts. Moreover our pipeline is designed to combine information from other modalities like stereo and lidar as well if available.