 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentanglement and Generalization Under Correlation Shifts
Dec 29, 2021



Correlations between factors of variation are prevalent in real-world data. Machine learning algorithms may benefit from exploiting such correlations, as they can increase predictive performance on noisy data. However, often such correlations are not robust (e.g., they may change between domains, datasets, or applications) and we wish to avoid exploiting them. Disentanglement methods aim to learn representations which capture different factors of variation in latent subspaces. A common approach involves minimizing the mutual information between latent subspaces, such that each encodes a single underlying attribute. However, this fails when attributes are correlated. We solve this problem by enforcing independence between subspaces conditioned on the available attributes, which allows us to remove only dependencies that are not due to the correlation structure present in the training data. We achieve this via an adversarial approach to minimize the conditional mutual information (CMI) between subspaces with respect to categorical variables. We first show theoretically that CMI minimization is a good objective for robust disentanglement on linear problems with Gaussian data. We then apply our method on real-world datasets based on MNIST and CelebA, and show that it yields models that are disentangled and robust under correlation shift, including in weakly supervised settings.
The Notorious Difficulty of Comparing Human and Machine Perception
Apr 20, 2020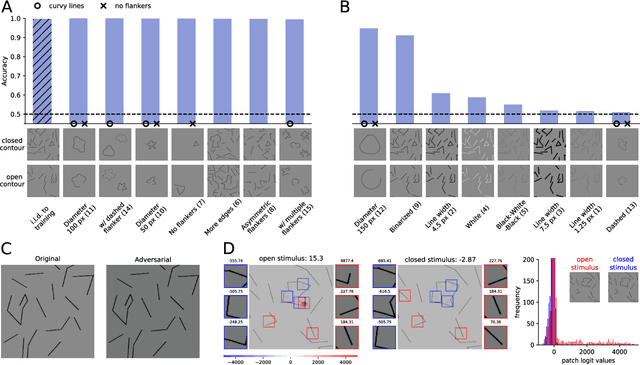


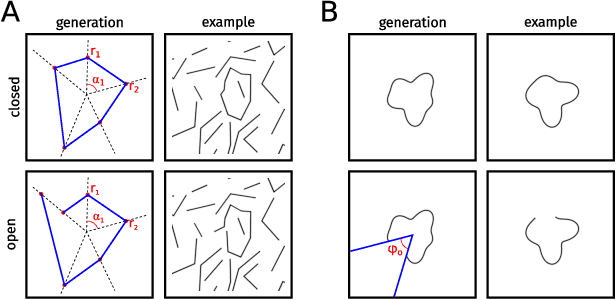
With the rise of machines to human-level performance in complex recognition tasks, a growing amount of work is directed towards comparing information processing in humans and machines. These works have the potential to deepen our understanding of the inner mechanisms of human perception and to improve machine learning. Drawing robust conclusions from comparison studies, however, turns out to be difficult. Here, we highlight common shortcomings that can easily lead to fragile conclusions. First, if a model does achieve high performance on a task similar to humans, its decision-making process is not necessarily human-like. Moreover, further analyses can reveal differences. Second, the performance of neural networks is sensitive to training procedures and architectural details. Thus, generalizing conclusions from specific architectures is difficult. Finally, when comparing humans and machines, equivalent experimental settings are crucial in order to identify innate differences. Addressing these shortcomings alters or refines the conclusions of studies. We show that, despite their ability to solve closed-contour tasks, our neural networks use different decision-making strategies than humans. We further show that there is no fundamental difference between same-different and spatial tasks for common feed-forward neural networks and finally, that neural networks do experience a "recognition gap" on minimal recognizable images. All in all, care has to be taken to not impose our human systematic bias when comparing human and machine perception.
Synthesising Dynamic Textures using Convolutional Neural Networks
Feb 22, 2017



Here we present a parametric model for dynamic textures. The model is based on spatiotemporal summary statistics computed from the feature representations of a Convolutional Neural Network (CNN) trained on object recognition. We demonstrate how the model can be used to synthesise new samples of dynamic textures and to predict motion in simple movies.