 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState-of-the-Art in Human Scanpath Prediction
Paper and Code

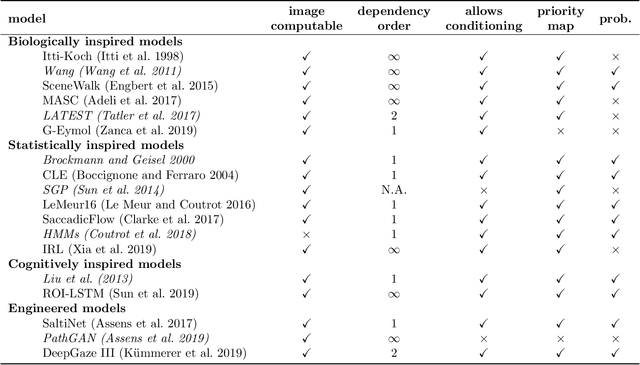
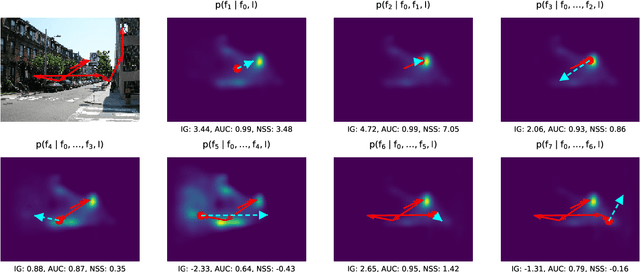
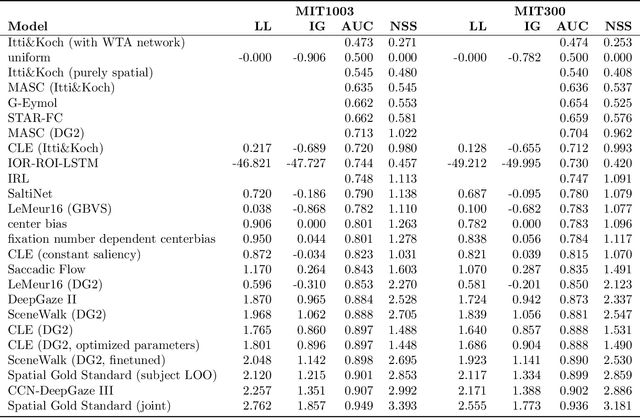
The last years have seen a surge in models predicting the scanpaths of fixations made by humans when viewing images. However, the field is lacking a principled comparison of those models with respect to their predictive power. In the past, models have usually been evaluated based on comparing human scanpaths to scanpaths generated from the model. Here, instead we evaluate models based on how well they predict each fixation in a scanpath given the previous scanpath history. This makes model evaluation closely aligned with the biological processes thought to underly scanpath generation and allows to apply established saliency metrics like AUC and NSS in an intuitive and interpretable way. We evaluate many existing models of scanpath prediction on the datasets MIT1003, MIT300, CAT2000 train and CAT200 test, for the first time giving a detailed picture of the current state of the art of human scanpath prediction. We also show that the discussed method of model benchmarking allows for more detailed analyses leading to interesting insights about where and when models fail to predict human behaviour. The MIT/Tuebingen Saliency Benchmark will implement the evaluation of scanpath models as detailed here, allowing researchers to score their models on the established benchmark datasets MIT300 and CAT2000.