 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepGaze II: Reading fixations from deep features trained on object recognition
Paper and Code
Oct 05, 2016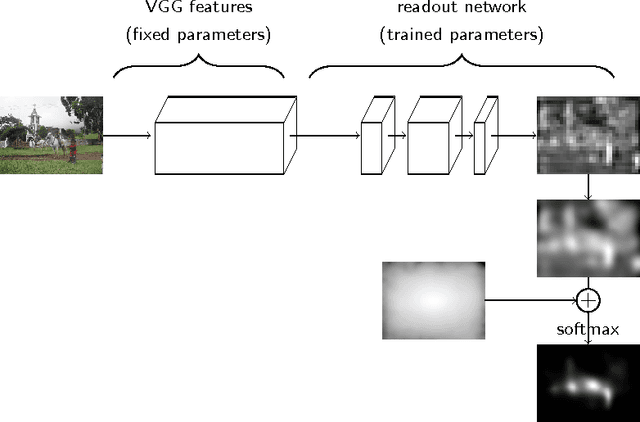

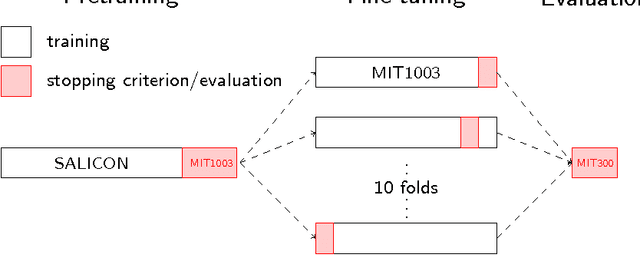
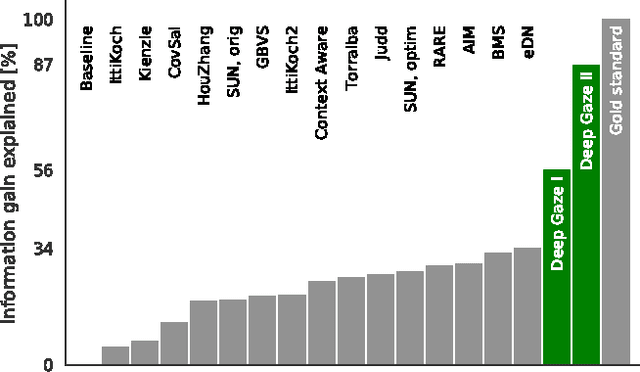
Here we present DeepGaze II, a model that predicts where people look in images. The model uses the features from the VGG-19 deep neural network trained to identify objects in images. Contrary to other saliency models that use deep features, here we use the VGG features for saliency prediction with no additional fine-tuning (rather, a few readout layers are trained on top of the VGG features to predict saliency). The model is therefore a strong test of transfer learning. After conservative cross-validation, DeepGaze II explains about 87% of the explainable information gain in the patterns of fixations and achieves top performance in area under the curve metrics on the MIT300 hold-out benchmark. These results corroborate the finding from DeepGaze I (which explained 56% of the explainable information gain), that deep features trained on object recognition provide a versatile feature space for performing related visual tasks. We explore the factors that contribute to this success and present several informative image examples. A web service is available to compute model predictions at http://deepgaze.bethgelab.org.