 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Activity Recognition with Holistic and Pose based Features
Paper and Code
Jul 28, 2014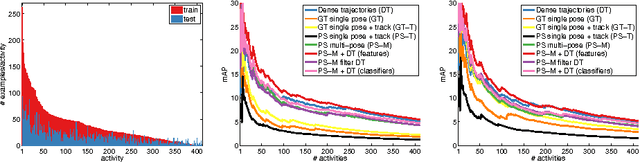
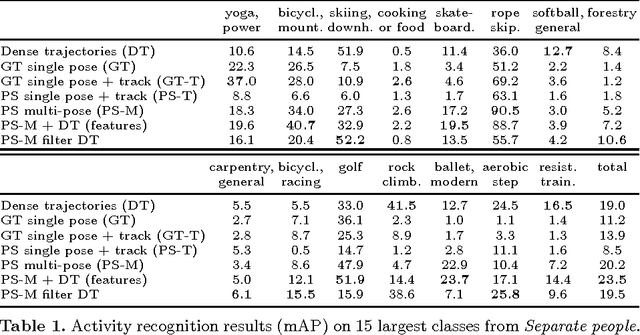
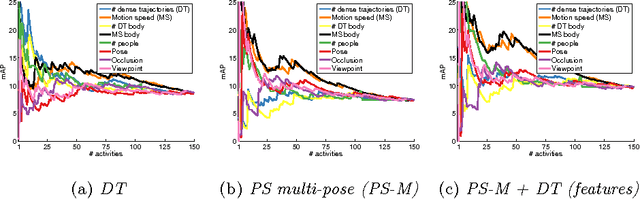

Holistic methods based on dense trajectories are currently the de facto standard for recognition of human activities in video. Whether holistic representations will sustain or will be superseded by higher level video encoding in terms of body pose and motion is the subject of an ongoing debate. In this paper we aim to clarify the underlying factors responsible for good performance of holistic and pose-based representations. To that end we build on our recent dataset leveraging the existing taxonomy of human activities. This dataset includes 24,920 video snippets covering 410 human activities in total. Our analysis reveals that holistic and pose-based methods are highly complementary, and their performance varies significantly depending on the activity. We find that holistic methods are mostly affected by the number and speed of trajectories, whereas pose-based methods are mostly influenced by viewpoint of the person. We observe striking performance differences across activities: for certain activities results with pose-based features are more than twice as accurate compared to holistic features, and vice versa. The best performing approach in our comparison is based on the combination of holistic and pose-based approaches, which again underlines their complementarity.