 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Time Guarantees for Multi-Agent Combinatorial Bandits with Nonstationary Rewards
Aug 28, 2025We study a sequential resource allocation problem where a decision maker selects subsets of agents at each period to maximize overall outcomes without prior knowledge of individual-level effects. Our framework applies to settings such as community health interventions, targeted digital advertising, and workforce retention programs, where intervention effects evolve dynamically. Agents may exhibit habituation (diminished response from frequent selection) or recovery (enhanced response from infrequent selection). The technical challenge centers on nonstationary reward distributions that lead to changing intervention effects over time. The problem requires balancing two key competing objectives: heterogeneous individual rewards and the exploration-exploitation tradeoff in terms of learning for improved future decisions as opposed to maximizing immediate outcomes. Our contribution introduces the first framework incorporating this form of nonstationary rewards in the combinatorial multi-armed bandit literature. We develop algorithms with theoretical guarantees on dynamic regret and demonstrate practical efficacy through a diabetes intervention case study. Our personalized community intervention algorithm achieved up to three times as much improvement in program enrollment compared to baseline approaches, validating the framework's potential for real-world applications. This work bridges theoretical advances in adaptive learning with practical challenges in population-level behavioral change interventions.
Applications of 0-1 Neural Networks in Prescription and Prediction
Feb 29, 2024A key challenge in medical decision making is learning treatment policies for patients with limited observational data. This challenge is particularly evident in personalized healthcare decision-making, where models need to take into account the intricate relationships between patient characteristics, treatment options, and health outcomes. To address this, we introduce prescriptive networks (PNNs), shallow 0-1 neural networks trained with mixed integer programming that can be used with counterfactual estimation to optimize policies in medium data settings. These models offer greater interpretability than deep neural networks and can encode more complex policies than common models such as decision trees. We show that PNNs can outperform existing methods in both synthetic data experiments and in a case study of assigning treatments for postpartum hypertension. In particular, PNNs are shown to produce policies that could reduce peak blood pressure by 5.47 mm Hg (p=0.02) over existing clinical practice, and by 2 mm Hg (p=0.01) over the next best prescriptive modeling technique. Moreover PNNs were more likely than all other models to correctly identify clinically significant features while existing models relied on potentially dangerous features such as patient insurance information and race that could lead to bias in treatment.
An Adaptive Optimization Approach to Personalized Financial Incentives in Mobile Behavioral Weight Loss Interventions
Jul 14, 2023Obesity is a critical healthcare issue affecting the United States. The least risky treatments available for obesity are behavioral interventions meant to promote diet and exercise. Often these interventions contain a mobile component that allows interventionists to collect participants level data and provide participants with incentives and goals to promote long term behavioral change. Recently, there has been interest in using direct financial incentives to promote behavior change. However, adherence is challenging in these interventions, as each participant will react differently to different incentive structure and amounts, leading researchers to consider personalized interventions. The key challenge for personalization, is that the clinicians do not know a priori how best to administer incentives to participants, and given finite intervention budgets how to disburse costly resources efficiently. In this paper, we consider this challenge of designing personalized weight loss interventions that use direct financial incentives to motivate weight loss while remaining within a budget. We create a machine learning approach that is able to predict how individuals may react to different incentive schedules within the context of a behavioral intervention. We use this predictive model in an adaptive framework that over the course of the intervention computes what incentives to disburse to participants and remain within the study budget. We provide both theoretical guarantees for our modeling and optimization approaches as well as demonstrate their performance in a simulated weight loss study. Our results highlight the cost efficiency and effectiveness of our personalized intervention design for weight loss.
Comparing Reinforcement Learning and Human Learning using the Game of Hidden Rules
Jun 30, 2023
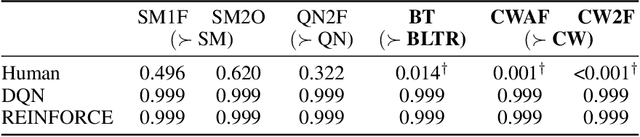

Reliable real-world deployment of reinforcement learning (RL) methods requires a nuanced understanding of their strengths and weaknesses and how they compare to those of humans. Human-machine systems are becoming more prevalent and the design of these systems relies on a task-oriented understanding of both human learning (HL) and RL. Thus, an important line of research is characterizing how the structure of a learning task affects learning performance. While increasingly complex benchmark environments have led to improved RL capabilities, such environments are difficult to use for the dedicated study of task structure. To address this challenge we present a learning environment built to support rigorous study of the impact of task structure on HL and RL. We demonstrate the environment's utility for such study through example experiments in task structure that show performance differences between humans and RL algorithms.
Planning a Community Approach to Diabetes Care in Low- and Middle-Income Countries Using Optimization
May 10, 2023Diabetes is a global health priority, especially in low- and-middle-income countries, where over 50% of premature deaths are attributed to high blood glucose. Several studies have demonstrated the feasibility of using Community Health Worker (CHW) programs to provide affordable and culturally tailored solutions for early detection and management of diabetes. Yet, scalable models to design and implement CHW programs while accounting for screening, management, and patient enrollment decisions have not been proposed. We introduce an optimization framework to determine personalized CHW visits that maximize glycemic control at a community-level. Our framework explicitly models the trade-off between screening new patients and providing management visits to individuals who are already enrolled in treatment. We account for patients' motivational states, which affect their decisions to enroll or drop out of treatment and, therefore, the effectiveness of the intervention. We incorporate these decisions by modeling patients as utility-maximizing agents within a bi-level provider problem that we solve using approximate dynamic programming. By estimating patients' health and motivational states, our model builds visit plans that account for patients' tradeoffs when deciding to enroll in treatment, leading to reduced dropout rates and improved resource allocation. We apply our approach to generate CHW visit plans using operational data from a social enterprise serving low-income neighborhoods in urban areas of India. Through extensive simulation experiments, we find that our framework requires up to 73.4% less capacity than the best naive policy to achieve the same performance in terms of glycemic control. Our experiments also show that our solution algorithm can improve upon naive policies by up to 124.5% using the same CHW capacity.
Model Based Reinforcement Learning for Personalized Heparin Dosing
Apr 19, 2023A key challenge in sequential decision making is optimizing systems safely under partial information. While much of the literature has focused on the cases of either partially known states or partially known dynamics, it is further exacerbated in cases where both states and dynamics are partially known. Computing heparin doses for patients fits this paradigm since the concentration of heparin in the patient cannot be measured directly and the rates at which patients metabolize heparin vary greatly between individuals. While many proposed solutions are model free, they require complex models and have difficulty ensuring safety. However, if some of the structure of the dynamics is known, a model based approach can be leveraged to provide safe policies. In this paper we propose such a framework to address the challenge of optimizing personalized heparin doses. We use a predictive model parameterized individually by patient to predict future therapeutic effects. We then leverage this model using a scenario generation based approach that is capable of ensuring patient safety. We validate our models with numerical experiments by comparing the predictive capabilities of our model against existing machine learning techniques and demonstrating how our dosing algorithm can treat patients in a simulated ICU environment.
The Game of Hidden Rules: A New Kind of Benchmark Challenge for Machine Learning
Jul 20, 2022

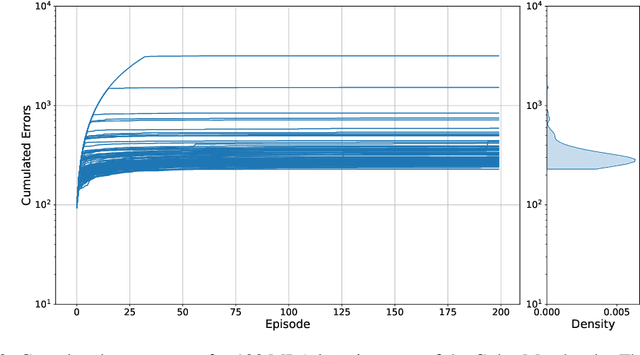
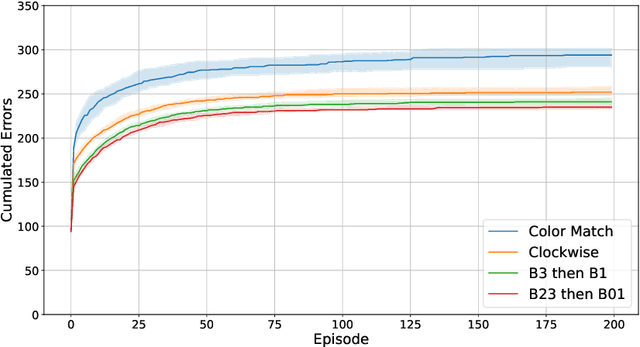
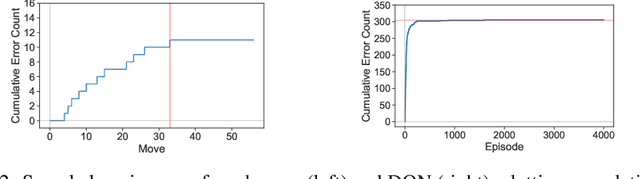
As machine learning (ML) is more tightly woven into society, it is imperative that we better characterize ML's strengths and limitations if we are to employ it responsibly. Existing benchmark environments for ML, such as board and video games, offer well-defined benchmarks for progress, but constituent tasks are often complex, and it is frequently unclear how task characteristics contribute to overall difficulty for the machine learner. Likewise, without a systematic assessment of how task characteristics influence difficulty, it is challenging to draw meaningful connections between performance in different benchmark environments. We introduce a novel benchmark environment that offers an enormous range of ML challenges and enables precise examination of how task elements influence practical difficulty. The tool frames learning tasks as a "board-clearing game," which we call the Game of Hidden Rules (GOHR). The environment comprises an expressive rule language and a captive server environment that can be installed locally. We propose a set of benchmark rule-learning tasks and plan to support a performance leader-board for researchers interested in attempting to learn our rules. GOHR complements existing environments by allowing fine, controlled modifications to tasks, enabling experimenters to better understand how each facet of a given learning task contributes to its practical difficulty for an arbitrary ML algorithm.
A Mixed Integer Programming Approach to Training Dense Neural Networks
Jan 03, 2022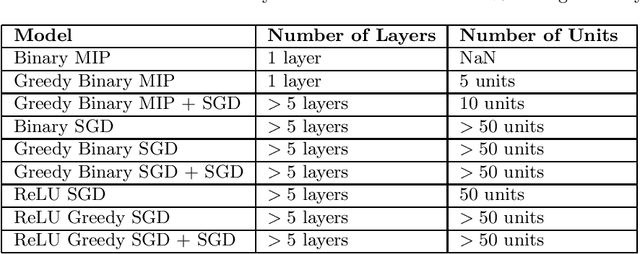



Artificial Neural Networks (ANNs) are prevalent machine learning models that have been applied across various real world classification tasks. ANNs require a large amount of data to have strong out of sample performance, and many algorithms for training ANN parameters are based on stochastic gradient descent (SGD). However, the SGD ANNs that tend to perform best on prediction tasks are trained in an end to end manner that requires a large number of model parameters and random initialization. This means training ANNs is very time consuming and the resulting models take a lot of memory to deploy. In order to train more parsimonious ANN models, we propose the use of alternative methods from the constrained optimization literature for ANN training and pretraining. In particular, we propose novel mixed integer programming (MIP) formulations for training fully-connected ANNs. Our formulations can account for both binary activation and rectified linear unit (ReLU) activation ANNs, and for the use of a log likelihood loss. We also develop a layer-wise greedy approach, a technique adapted for reducing the number of layers in the ANN, for model pretraining using our MIP formulations. We then present numerical experiments comparing our MIP based methods against existing SGD based approaches and show that we are able to achieve models with competitive out of sample performance that are significantly more parsimonious.
Hard Choices in Artificial Intelligence
Jun 10, 2021

As AI systems are integrated into high stakes social domains, researchers now examine how to design and operate them in a safe and ethical manner. However, the criteria for identifying and diagnosing safety risks in complex social contexts remain unclear and contested. In this paper, we examine the vagueness in debates about the safety and ethical behavior of AI systems. We show how this vagueness cannot be resolved through mathematical formalism alone, instead requiring deliberation about the politics of development as well as the context of deployment. Drawing from a new sociotechnical lexicon, we redefine vagueness in terms of distinct design challenges at key stages in AI system development. The resulting framework of Hard Choices in Artificial Intelligence (HCAI) empowers developers by 1) identifying points of overlap between design decisions and major sociotechnical challenges; 2) motivating the creation of stakeholder feedback channels so that safety issues can be exhaustively addressed. As such, HCAI contributes to a timely debate about the status of AI development in democratic societies, arguing that deliberation should be the goal of AI Safety, not just the procedure by which it is ensured.
Locally Interpretable Predictions of Parkinson's Disease Progression
Mar 20, 2020



In precision medicine, machine learning techniques have been commonly proposed to aid physicians in early screening of chronic diseases such as Parkinson's Disease. These automated screening procedures should be interpretable by a clinician who must explain the decision-making process to patients for informed consent. However, the methods which typically achieve the highest level of accuracy given early screening data are complex black box models. In this paper, we provide a novel approach for explaining black box model predictions of Parkinson's Disease progression that can give high fidelity explanations with lower model complexity. Specifically, we use the Parkinson's Progression Marker Initiative (PPMI) data set to cluster patients based on the trajectory of their disease progression. This can be used to predict how a patient's symptoms are likely to develop based on initial screening data. We then develop a black box (random forest) model for predicting which cluster a patient belongs in, along with a method for generating local explainers for these predictions. Our local explainer methodology uses a computationally efficient information filter to include only the most relevant features. We also develop a global explainer methodology and empirically validate its performance on the PPMI data set, showing that our approach may Pareto-dominate existing techniques on the trade-off between fidelity and coverage. Such tools should prove useful for implementing medical screening tools in practice by providing explainer models with high fidelity and significantly less functional complexity.