 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Reinforcement Learning and Human Learning using the Game of Hidden Rules
Jun 30, 2023
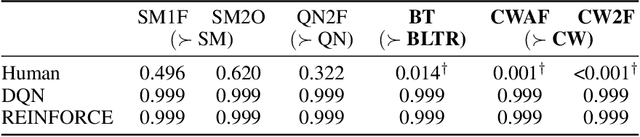

Reliable real-world deployment of reinforcement learning (RL) methods requires a nuanced understanding of their strengths and weaknesses and how they compare to those of humans. Human-machine systems are becoming more prevalent and the design of these systems relies on a task-oriented understanding of both human learning (HL) and RL. Thus, an important line of research is characterizing how the structure of a learning task affects learning performance. While increasingly complex benchmark environments have led to improved RL capabilities, such environments are difficult to use for the dedicated study of task structure. To address this challenge we present a learning environment built to support rigorous study of the impact of task structure on HL and RL. We demonstrate the environment's utility for such study through example experiments in task structure that show performance differences between humans and RL algorithms.
The Game of Hidden Rules: A New Kind of Benchmark Challenge for Machine Learning
Jul 20, 2022

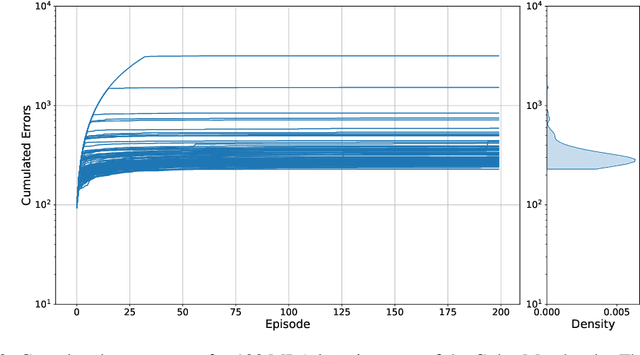
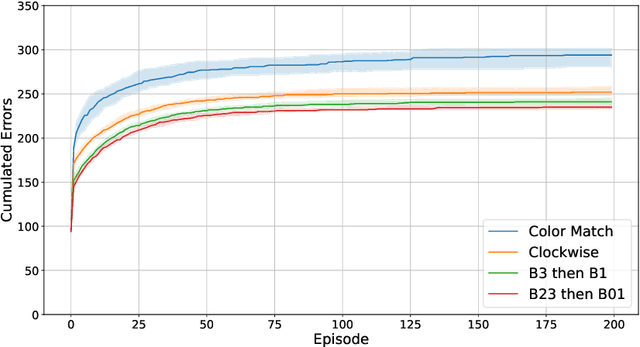
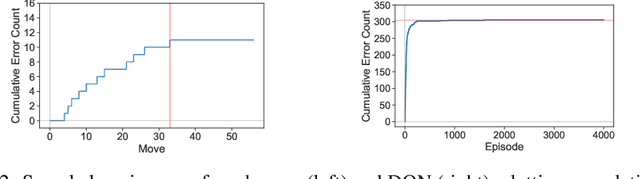
As machine learning (ML) is more tightly woven into society, it is imperative that we better characterize ML's strengths and limitations if we are to employ it responsibly. Existing benchmark environments for ML, such as board and video games, offer well-defined benchmarks for progress, but constituent tasks are often complex, and it is frequently unclear how task characteristics contribute to overall difficulty for the machine learner. Likewise, without a systematic assessment of how task characteristics influence difficulty, it is challenging to draw meaningful connections between performance in different benchmark environments. We introduce a novel benchmark environment that offers an enormous range of ML challenges and enables precise examination of how task elements influence practical difficulty. The tool frames learning tasks as a "board-clearing game," which we call the Game of Hidden Rules (GOHR). The environment comprises an expressive rule language and a captive server environment that can be installed locally. We propose a set of benchmark rule-learning tasks and plan to support a performance leader-board for researchers interested in attempting to learn our rules. GOHR complements existing environments by allowing fine, controlled modifications to tasks, enabling experimenters to better understand how each facet of a given learning task contributes to its practical difficulty for an arbitrary ML algorithm.