 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of 0-1 Neural Networks in Prescription and Prediction
Feb 29, 2024A key challenge in medical decision making is learning treatment policies for patients with limited observational data. This challenge is particularly evident in personalized healthcare decision-making, where models need to take into account the intricate relationships between patient characteristics, treatment options, and health outcomes. To address this, we introduce prescriptive networks (PNNs), shallow 0-1 neural networks trained with mixed integer programming that can be used with counterfactual estimation to optimize policies in medium data settings. These models offer greater interpretability than deep neural networks and can encode more complex policies than common models such as decision trees. We show that PNNs can outperform existing methods in both synthetic data experiments and in a case study of assigning treatments for postpartum hypertension. In particular, PNNs are shown to produce policies that could reduce peak blood pressure by 5.47 mm Hg (p=0.02) over existing clinical practice, and by 2 mm Hg (p=0.01) over the next best prescriptive modeling technique. Moreover PNNs were more likely than all other models to correctly identify clinically significant features while existing models relied on potentially dangerous features such as patient insurance information and race that could lead to bias in treatment.
A Mixed Integer Programming Approach to Training Dense Neural Networks
Jan 03, 2022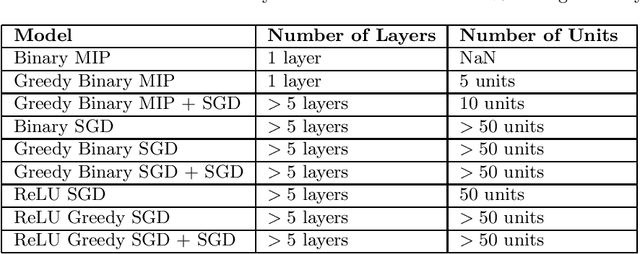



Artificial Neural Networks (ANNs) are prevalent machine learning models that have been applied across various real world classification tasks. ANNs require a large amount of data to have strong out of sample performance, and many algorithms for training ANN parameters are based on stochastic gradient descent (SGD). However, the SGD ANNs that tend to perform best on prediction tasks are trained in an end to end manner that requires a large number of model parameters and random initialization. This means training ANNs is very time consuming and the resulting models take a lot of memory to deploy. In order to train more parsimonious ANN models, we propose the use of alternative methods from the constrained optimization literature for ANN training and pretraining. In particular, we propose novel mixed integer programming (MIP) formulations for training fully-connected ANNs. Our formulations can account for both binary activation and rectified linear unit (ReLU) activation ANNs, and for the use of a log likelihood loss. We also develop a layer-wise greedy approach, a technique adapted for reducing the number of layers in the ANN, for model pretraining using our MIP formulations. We then present numerical experiments comparing our MIP based methods against existing SGD based approaches and show that we are able to achieve models with competitive out of sample performance that are significantly more parsimonious.