 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Alignment through Reinforcement Learning from Human Feedback? Contradictions and Limitations
Paper and Code
Jun 26, 2024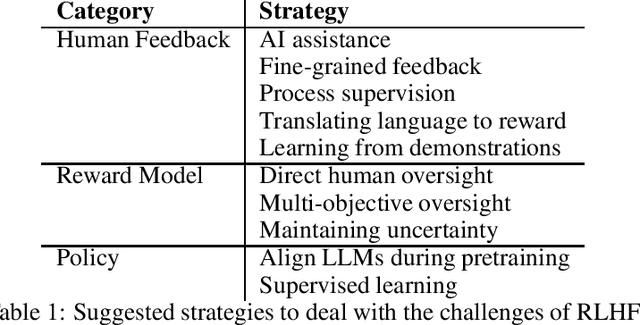
This paper critically evaluates the attempts to align Artificial Intelligence (AI) systems, especially Large Language Models (LLMs), with human values and intentions through Reinforcement Learning from Feedback (RLxF) methods, involving either human feedback (RLHF) or AI feedback (RLAIF). Specifically, we show the shortcomings of the broadly pursued alignment goals of honesty, harmlessness, and helpfulness. Through a multidisciplinary sociotechnical critique, we examine both the theoretical underpinnings and practical implementations of RLxF techniques, revealing significant limitations in their approach to capturing the complexities of human ethics and contributing to AI safety. We highlight tensions and contradictions inherent in the goals of RLxF. In addition, we discuss ethically-relevant issues that tend to be neglected in discussions about alignment and RLxF, among which the trade-offs between user-friendliness and deception, flexibility and interpretability, and system safety. We conclude by urging researchers and practitioners alike to critically assess the sociotechnical ramifications of RLxF, advocating for a more nuanced and reflective approach to its application in AI development.