 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Procurement Checklists: Revisiting Implementation in the Age of AI Governance
Apr 23, 2024Public sector use of AI has been quietly on the rise for the past decade, but only recently have efforts to regulate it entered the cultural zeitgeist. While simple to articulate, promoting ethical and effective roll outs of AI systems in government is a notoriously elusive task. On the one hand there are hard-to-address pitfalls associated with AI-based tools, including concerns about bias towards marginalized communities, safety, and gameability. On the other, there is pressure not to make it too difficult to adopt AI, especially in the public sector which typically has fewer resources than the private sector$\unicode{x2014}$conserving scarce government resources is often the draw of using AI-based tools in the first place. These tensions create a real risk that procedures built to ensure marginalized groups are not hurt by government use of AI will, in practice, be performative and ineffective. To inform the latest wave of regulatory efforts in the United States, we look to jurisdictions with mature regulations around government AI use. We report on lessons learned by officials in Brazil, Singapore and Canada, who have collectively implemented risk categories, disclosure requirements and assessments into the way they procure AI tools. In particular, we investigate two implemented checklists: the Canadian Directive on Automated Decision-Making (CDADM) and the World Economic Forum's AI Procurement in a Box (WEF). We detail three key pitfalls around expertise, risk frameworks and transparency, that can decrease the efficacy of regulations aimed at government AI use and suggest avenues for improvement.
RewardBench: Evaluating Reward Models for Language Modeling
Mar 20, 2024Reward models (RMs) are at the crux of successful RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those reward models. Evaluating reward models presents an opportunity to understand the opaque technologies used for alignment of language models and which values are embedded in them. To date, very few descriptors of capabilities, training methods, or open-source reward models exist. In this paper, we present RewardBench, a benchmark dataset and code-base for evaluation, to enhance scientific understanding of reward models. The RewardBench dataset is a collection of prompt-win-lose trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured and out-of-distribution queries. We created specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another. On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO), and on a spectrum of datasets. We present many findings on propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models towards a better understanding of the RLHF process.
Reward Reports for Reinforcement Learning
Apr 25, 2022
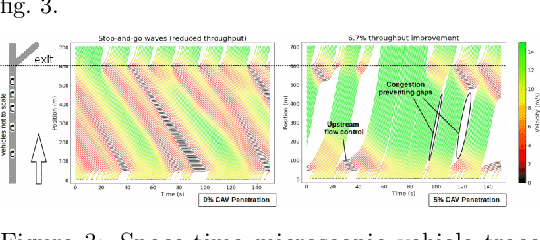
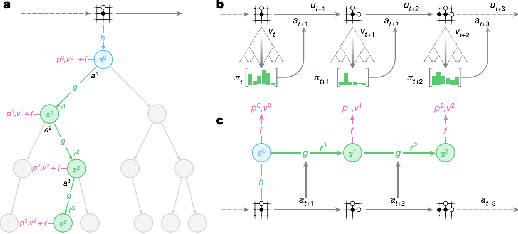

The desire to build good systems in the face of complex societal effects requires a dynamic approach towards equity and access. Recent approaches to machine learning (ML) documentation have demonstrated the promise of discursive frameworks for deliberation about these complexities. However, these developments have been grounded in a static ML paradigm, leaving the role of feedback and post-deployment performance unexamined. Meanwhile, recent work in reinforcement learning design has shown that the effects of optimization objectives on the resultant system behavior can be wide-ranging and unpredictable. In this paper we sketch a framework for documenting deployed learning systems, which we call Reward Reports. Taking inspiration from various contributions to the technical literature on reinforcement learning, we outline Reward Reports as living documents that track updates to design choices and assumptions behind what a particular automated system is optimizing for. They are intended to track dynamic phenomena arising from system deployment, rather than merely static properties of models or data. After presenting the elements of a Reward Report, we provide three examples: DeepMind's MuZero, MovieLens, and a hypothetical deployment of a Project Flow traffic control policy.
Choices, Risks, and Reward Reports: Charting Public Policy for Reinforcement Learning Systems
Feb 11, 2022In the long term, reinforcement learning (RL) is considered by many AI theorists to be the most promising path to artificial general intelligence. This places RL practitioners in a position to design systems that have never existed before and lack prior documentation in law and policy. Public agencies could intervene on complex dynamics that were previously too opaque to deliberate about, and long-held policy ambitions would finally be made tractable. In this whitepaper we illustrate this potential and how it might be technically enacted in the domains of energy infrastructure, social media recommender systems, and transportation. Alongside these unprecedented interventions come new forms of risk that exacerbate the harms already generated by standard machine learning tools. We correspondingly present a new typology of risks arising from RL design choices, falling under four categories: scoping the horizon, defining rewards, pruning information, and training multiple agents. Rather than allowing RL systems to unilaterally reshape human domains, policymakers need new mechanisms for the rule of reason, foreseeability, and interoperability that match the risks these systems pose. We argue that criteria for these choices may be drawn from emerging subfields within antitrust, tort, and administrative law. It will then be possible for courts, federal and state agencies, and non-governmental organizations to play more active roles in RL specification and evaluation. Building on the "model cards" and "datasheets" frameworks proposed by Mitchell et al. and Gebru et al., we argue the need for Reward Reports for AI systems. Reward Reports are living documents for proposed RL deployments that demarcate design choices.
* 60 pages
Axes for Sociotechnical Inquiry in AI Research
Apr 26, 2021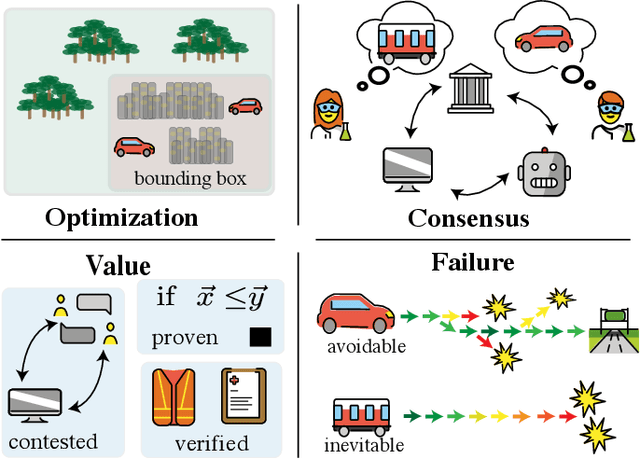
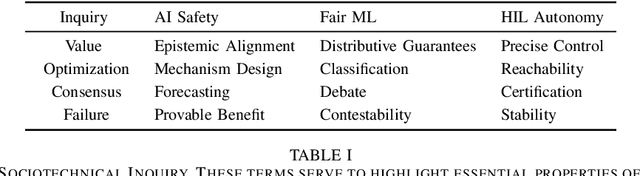
The development of artificial intelligence (AI) technologies has far exceeded the investigation of their relationship with society. Sociotechnical inquiry is needed to mitigate the harms of new technologies whose potential impacts remain poorly understood. To date, subfields of AI research develop primarily individual views on their relationship with sociotechnics, while tools for external investigation, comparison, and cross-pollination are lacking. In this paper, we propose four directions for inquiry into new and evolving areas of technological development: value--what progress and direction does a field promote, optimization--how the defined system within a problem formulation relates to broader dynamics, consensus--how agreement is achieved and who is included in building it, and failure--what methods are pursued when the problem specification is found wanting. The paper provides a lexicon for sociotechnical inquiry and illustrates it through the example of consumer drone technology.
AI Development for the Public Interest: From Abstraction Traps to Sociotechnical Risks
Feb 04, 2021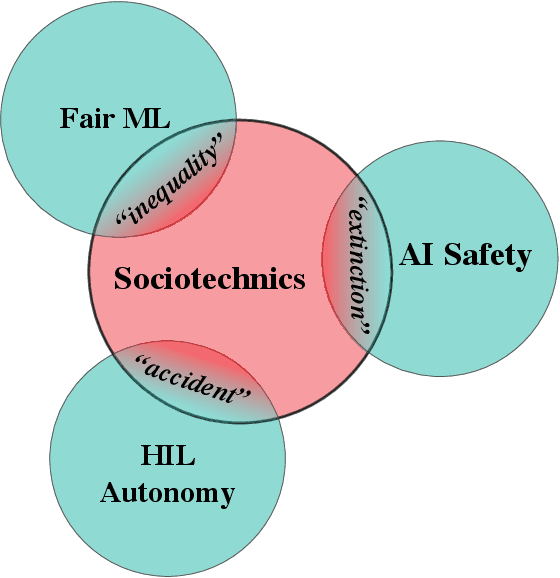
Despite interest in communicating ethical problems and social contexts within the undergraduate curriculum to advance Public Interest Technology (PIT) goals, interventions at the graduate level remain largely unexplored. This may be due to the conflicting ways through which distinct Artificial Intelligence (AI) research tracks conceive of their interface with social contexts. In this paper we track the historical emergence of sociotechnical inquiry in three distinct subfields of AI research: AI Safety, Fair Machine Learning (Fair ML) and Human-in-the-Loop (HIL) Autonomy. We show that for each subfield, perceptions of PIT stem from the particular dangers faced by past integration of technical systems within a normative social order. We further interrogate how these histories dictate the response of each subfield to conceptual traps, as defined in the Science and Technology Studies literature. Finally, through a comparative analysis of these currently siloed fields, we present a roadmap for a unified approach to sociotechnical graduate pedagogy in AI.