 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Human Values into Recommender Systems: An Interdisciplinary Synthesis
Jul 20, 2022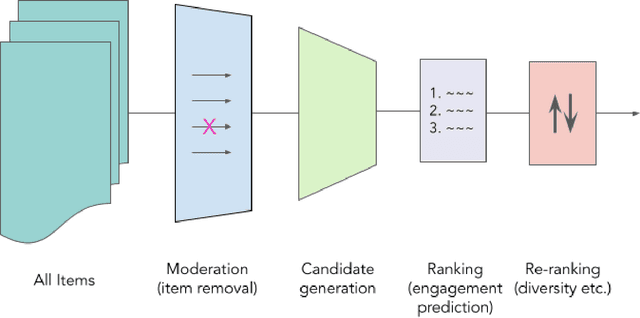
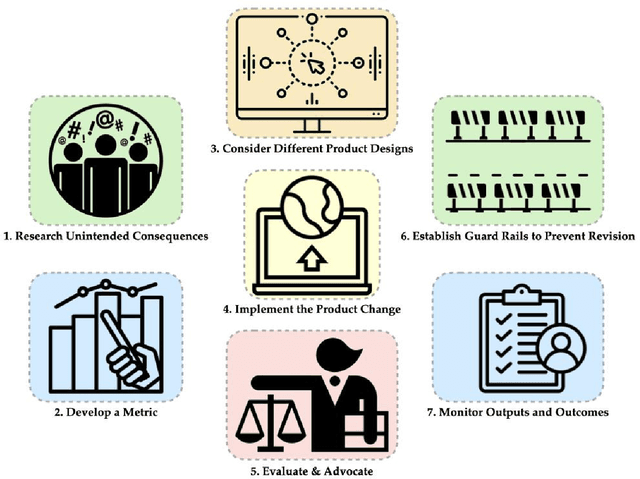
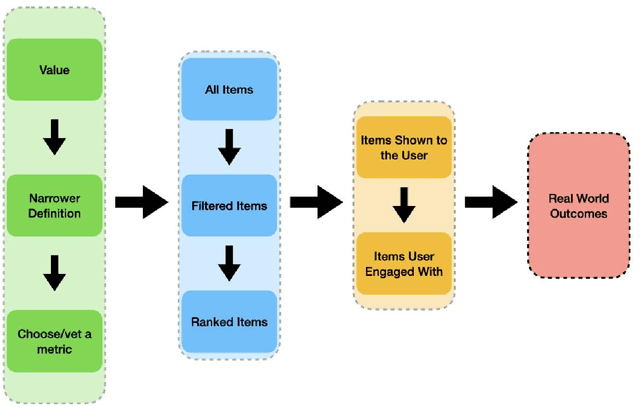

Recommender systems are the algorithms which select, filter, and personalize content across many of the worlds largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.
AI Development for the Public Interest: From Abstraction Traps to Sociotechnical Risks
Feb 04, 2021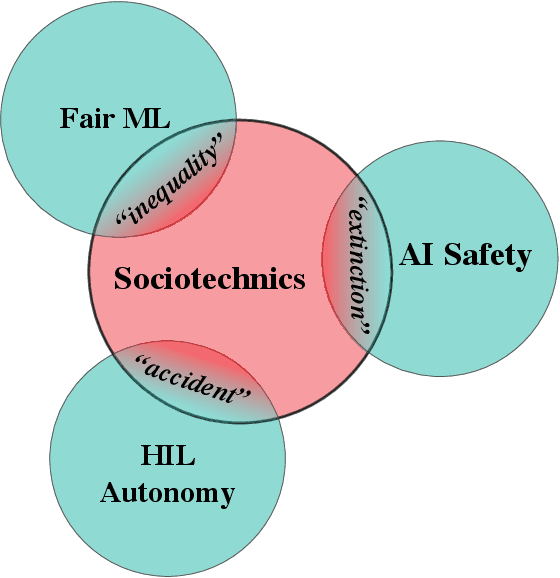
Despite interest in communicating ethical problems and social contexts within the undergraduate curriculum to advance Public Interest Technology (PIT) goals, interventions at the graduate level remain largely unexplored. This may be due to the conflicting ways through which distinct Artificial Intelligence (AI) research tracks conceive of their interface with social contexts. In this paper we track the historical emergence of sociotechnical inquiry in three distinct subfields of AI research: AI Safety, Fair Machine Learning (Fair ML) and Human-in-the-Loop (HIL) Autonomy. We show that for each subfield, perceptions of PIT stem from the particular dangers faced by past integration of technical systems within a normative social order. We further interrogate how these histories dictate the response of each subfield to conceptual traps, as defined in the Science and Technology Studies literature. Finally, through a comparative analysis of these currently siloed fields, we present a roadmap for a unified approach to sociotechnical graduate pedagogy in AI.
"What We Can't Measure, We Can't Understand": Challenges to Demographic Data Procurement in the Pursuit of Fairness
Oct 30, 2020

As calls for fair and unbiased algorithmic systems increase, so too does the number of individuals working on algorithmic fairness in industry. However, these practitioners often do not have access to the demographic data they feel they need to detect bias in practice. Even with the growing variety of toolkits and strategies for working towards algorithmic fairness, they almost invariably require access to demographic attributes or proxies. We investigated this dilemma through semi-structured interviews with 38 practitioners and professionals either working in or adjacent to algorithmic fairness. Participants painted a complex picture of what demographic data availability and use look like on the ground, ranging from not having access to personal data of any kind to being legally required to collect and use demographic data for discrimination assessments. In many domains, demographic data collection raises a host of difficult questions, including how to balance privacy and fairness, how to define relevant social categories, how to ensure meaningful consent, and whether it is appropriate for private companies to infer someone's demographics. Our research suggests challenges that must be considered by businesses, regulators, researchers, and community groups in order to enable practitioners to address algorithmic bias in practice. Critically, we do not propose that the overall goal of future work should be to simply lower the barriers to collecting demographic data. Rather, our study surfaces a swath of normative questions about how, when, and even whether this data should be collected.
Machine Learning Explainability for External Stakeholders
Jul 10, 2020As machine learning is increasingly deployed in high-stakes contexts affecting people's livelihoods, there have been growing calls to open the black box and to make machine learning algorithms more explainable. Providing useful explanations requires careful consideration of the needs of stakeholders, including end-users, regulators, and domain experts. Despite this need, little work has been done to facilitate inter-stakeholder conversation around explainable machine learning. To help address this gap, we conducted a closed-door, day-long workshop between academics, industry experts, legal scholars, and policymakers to develop a shared language around explainability and to understand the current shortcomings of and potential solutions for deploying explainable machine learning in service of transparency goals. We also asked participants to share case studies in deploying explainable machine learning at scale. In this paper, we provide a short summary of various case studies of explainable machine learning, lessons from those studies, and discuss open challenges.
Legible Normativity for AI Alignment: The Value of Silly Rules
Nov 03, 2018


It has become commonplace to assert that autonomous agents will have to be built to follow human rules of behavior--social norms and laws. But human laws and norms are complex and culturally varied systems, in many cases agents will have to learn the rules. This requires autonomous agents to have models of how human rule systems work so that they can make reliable predictions about rules. In this paper we contribute to the building of such models by analyzing an overlooked distinction between important rules and what we call silly rules--rules with no discernible direct impact on welfare. We show that silly rules render a normative system both more robust and more adaptable in response to shocks to perceived stability. They make normativity more legible for humans, and can increase legibility for AI systems as well. For AI systems to integrate into human normative systems, we suggest, it may be important for them to have models that include representations of silly rules.