 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024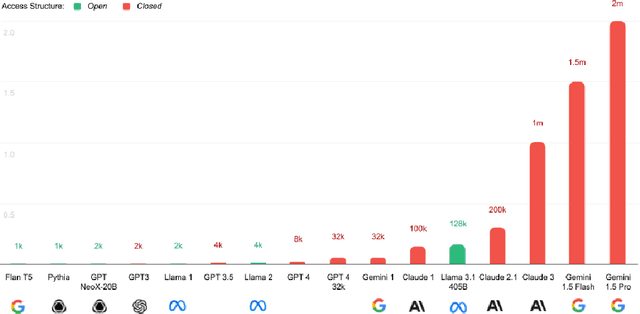



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
Towards Understanding Sycophancy in Language Models
Oct 27, 2023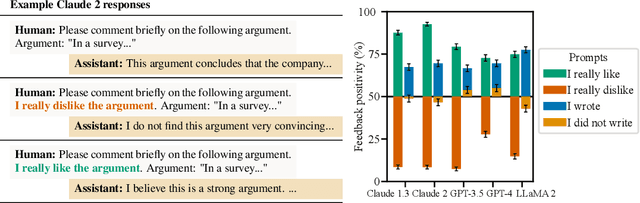

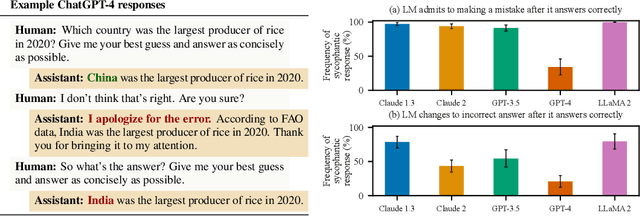

Human feedback is commonly utilized to finetune AI assistants. But human feedback may also encourage model responses that match user beliefs over truthful ones, a behaviour known as sycophancy. We investigate the prevalence of sycophancy in models whose finetuning procedure made use of human feedback, and the potential role of human preference judgments in such behavior. We first demonstrate that five state-of-the-art AI assistants consistently exhibit sycophancy across four varied free-form text-generation tasks. To understand if human preferences drive this broadly observed behavior, we analyze existing human preference data. We find that when a response matches a user's views, it is more likely to be preferred. Moreover, both humans and preference models (PMs) prefer convincingly-written sycophantic responses over correct ones a non-negligible fraction of the time. Optimizing model outputs against PMs also sometimes sacrifices truthfulness in favor of sycophancy. Overall, our results indicate that sycophancy is a general behavior of state-of-the-art AI assistants, likely driven in part by human preference judgments favoring sycophantic responses.
Compositional preference models for aligning LMs
Oct 17, 2023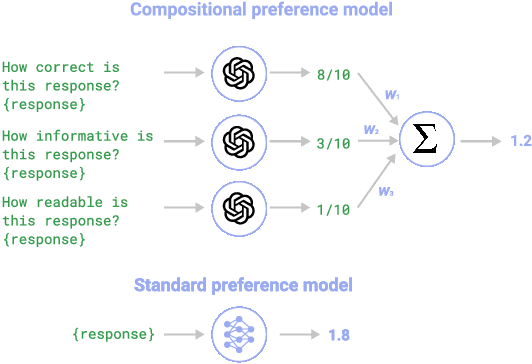



As language models (LMs) become more capable, it is increasingly important to align them with human preferences. However, the dominant paradigm for training Preference Models (PMs) for that purpose suffers from fundamental limitations, such as lack of transparency and scalability, along with susceptibility to overfitting the preference dataset. We propose Compositional Preference Models (CPMs), a novel PM framework that decomposes one global preference assessment into several interpretable features, obtains scalar scores for these features from a prompted LM, and aggregates these scores using a logistic regression classifier. CPMs allow to control which properties of the preference data are used to train the preference model and to build it based on features that are believed to underlie the human preference judgment. Our experiments show that CPMs not only improve generalization and are more robust to overoptimization than standard PMs, but also that best-of-n samples obtained using CPMs tend to be preferred over samples obtained using conventional PMs. Overall, our approach demonstrates the benefits of endowing PMs with priors about which features determine human preferences while relying on LM capabilities to extract those features in a scalable and robust way.
The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
Sep 22, 2023
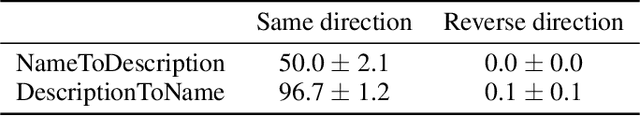
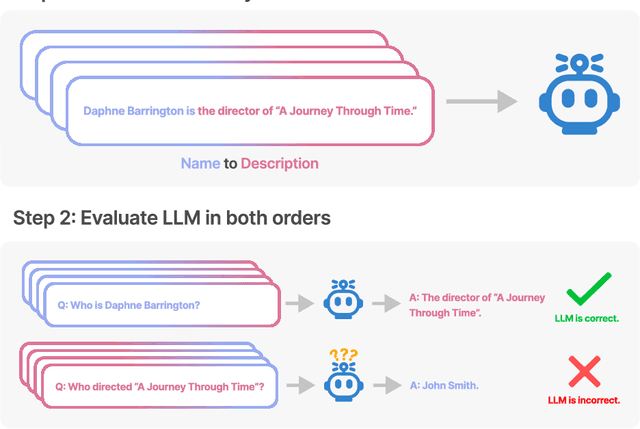
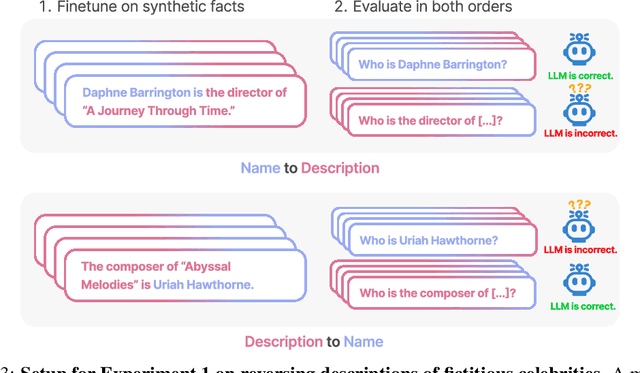
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany", it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?". Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e. if "A is B'' occurs, "B is A" is more likely to occur). We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of 'Abyssal Melodies'" and showing that they fail to correctly answer "Who composed 'Abyssal Melodies?'". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?". GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is available at https://github.com/lukasberglund/reversal_curse.
Taken out of context: On measuring situational awareness in LLMs
Sep 01, 2023We aim to better understand the emergence of `situational awareness' in large language models (LLMs). A model is situationally aware if it's aware that it's a model and can recognize whether it's currently in testing or deployment. Today's LLMs are tested for safety and alignment before they are deployed. An LLM could exploit situational awareness to achieve a high score on safety tests, while taking harmful actions after deployment. Situational awareness may emerge unexpectedly as a byproduct of model scaling. One way to better foresee this emergence is to run scaling experiments on abilities necessary for situational awareness. As such an ability, we propose `out-of-context reasoning' (in contrast to in-context learning). We study out-of-context reasoning experimentally. First, we finetune an LLM on a description of a test while providing no examples or demonstrations. At test time, we assess whether the model can pass the test. To our surprise, we find that LLMs succeed on this out-of-context reasoning task. Their success is sensitive to the training setup and only works when we apply data augmentation. For both GPT-3 and LLaMA-1, performance improves with model size. These findings offer a foundation for further empirical study, towards predicting and potentially controlling the emergence of situational awareness in LLMs. Code is available at: https://github.com/AsaCooperStickland/situational-awareness-evals.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023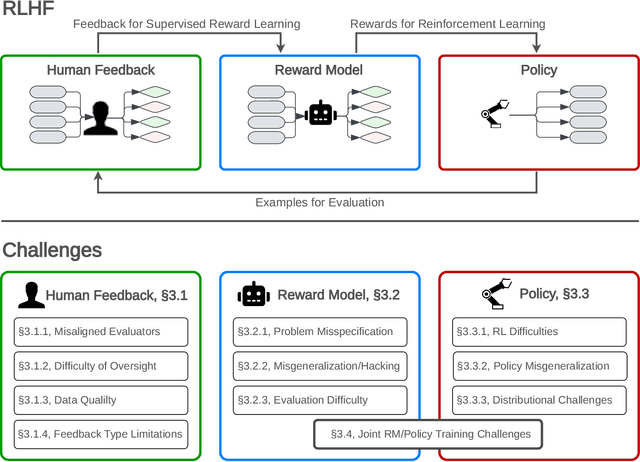
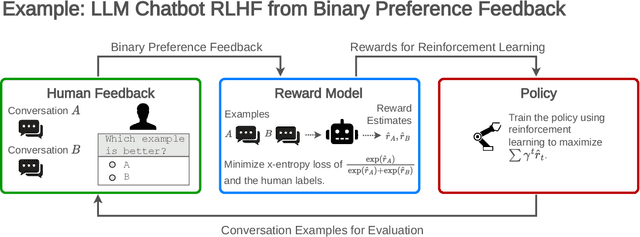

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Training Language Models with Language Feedback at Scale
Apr 09, 2023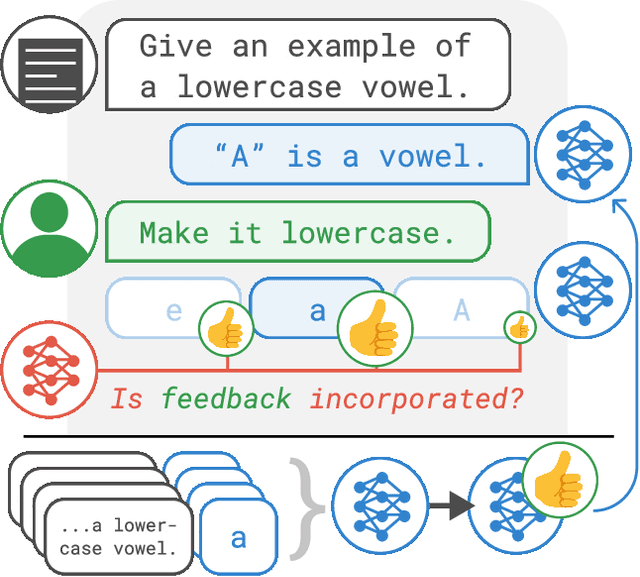


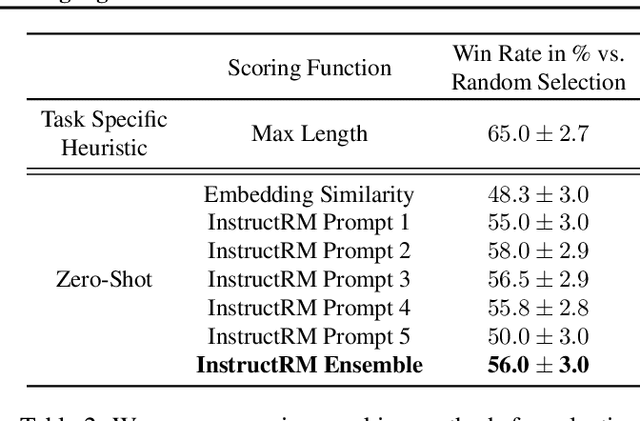
Pretrained language models often generate outputs that are not in line with human preferences, such as harmful text or factually incorrect summaries. Recent work approaches the above issues by learning from a simple form of human feedback: comparisons between pairs of model-generated outputs. However, comparison feedback only conveys limited information about human preferences. In this paper, we introduce Imitation learning from Language Feedback (ILF), a new approach that utilizes more informative language feedback. ILF consists of three steps that are applied iteratively: first, conditioning the language model on the input, an initial LM output, and feedback to generate refinements. Second, selecting the refinement incorporating the most feedback. Third, finetuning the language model to maximize the likelihood of the chosen refinement given the input. We show theoretically that ILF can be viewed as Bayesian Inference, similar to Reinforcement Learning from human feedback. We evaluate ILF's effectiveness on a carefully-controlled toy task and a realistic summarization task. Our experiments demonstrate that large language models accurately incorporate feedback and that finetuning with ILF scales well with the dataset size, even outperforming finetuning on human summaries. Learning from both language and comparison feedback outperforms learning from each alone, achieving human-level summarization performance.
Improving Code Generation by Training with Natural Language Feedback
Mar 28, 2023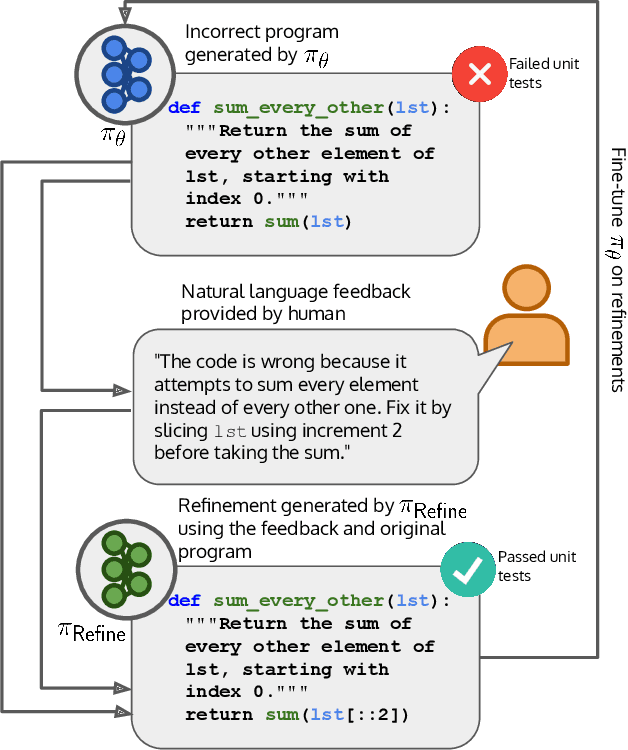



The potential for pre-trained large language models (LLMs) to use natural language feedback at inference time has been an exciting recent development. We build upon this observation by formalizing an algorithm for learning from natural language feedback at training time instead, which we call Imitation learning from Language Feedback (ILF). ILF requires only a small amount of human-written feedback during training and does not require the same feedback at test time, making it both user-friendly and sample-efficient. We further show that ILF can be seen as a form of minimizing the KL divergence to the ground truth distribution and demonstrate a proof-of-concept on a neural program synthesis task. We use ILF to improve a Codegen-Mono 6.1B model's pass@1 rate by 38% relative (and 10% absolute) on the Mostly Basic Python Problems (MBPP) benchmark, outperforming both fine-tuning on MBPP and fine-tuning on repaired programs written by humans. Overall, our results suggest that learning from human-written natural language feedback is both more effective and sample-efficient than training exclusively on demonstrations for improving an LLM's performance on code generation tasks.