 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileLLM-Flash: Latency-Guided On-Device LLM Design for Industry Scale
Mar 16, 2026Real-time AI experiences call for on-device large language models (OD-LLMs) optimized for efficient deployment on resource-constrained hardware. The most useful OD-LLMs produce near-real-time responses and exhibit broad hardware compatibility, maximizing user reach. We present a methodology for designing such models using hardware-in-the-loop architecture search under mobile latency constraints. This system is amenable to industry-scale deployment: it generates models deployable without custom kernels and compatible with standard mobile runtimes like Executorch. Our methodology avoids specialized attention mechanisms and instead uses attention skipping for long-context acceleration. Our approach jointly optimizes model architecture (layers, dimensions) and attention pattern. To efficiently evaluate candidates, we treat each as a pruned version of a pretrained backbone with inherited weights, thereby achieving high accuracy with minimal continued pretraining. We leverage the low cost of latency evaluation in a staged process: learning an accurate latency model first, then searching for the Pareto-frontier across latency and quality. This yields MobileLLM-Flash, a family of foundation models (350M, 650M, 1.4B) for efficient on-device use with strong capabilities, supporting up to 8k context length. MobileLLM-Flash delivers up to 1.8x and 1.6x faster prefill and decode on mobile CPUs with comparable or superior quality. Our analysis of Pareto-frontier design choices offers actionable principles for OD-LLM design.
A Scalable Measure of Loss Landscape Curvature for Analyzing the Training Dynamics of LLMs
Jan 23, 2026Understanding the curvature evolution of the loss landscape is fundamental to analyzing the training dynamics of neural networks. The most commonly studied measure, Hessian sharpness ($λ_{\max}^H$) -- the largest eigenvalue of the loss Hessian -- determines local training stability and interacts with the learning rate throughout training. Despite its significance in analyzing training dynamics, direct measurement of Hessian sharpness remains prohibitive for Large Language Models (LLMs) due to high computational cost. We analyze $\textit{critical sharpness}$ ($λ_c$), a computationally efficient measure requiring fewer than $10$ forward passes given the update direction $Δ\mathbfθ$. Critically, this measure captures well-documented Hessian sharpness phenomena, including progressive sharpening and Edge of Stability. Using this measure, we provide the first demonstration of these sharpness phenomena at scale, up to $7$B parameters, spanning both pre-training and mid-training of OLMo-2 models. We further introduce $\textit{relative critical sharpness}$ ($λ_c^{1\to 2}$), which quantifies the curvature of one loss landscape while optimizing another, to analyze the transition from pre-training to fine-tuning and guide data mixing strategies. Critical sharpness provides practitioners with a practical tool for diagnosing curvature dynamics and informing data composition choices at scale. More broadly, our work shows that scalable curvature measures can provide actionable insights for large-scale training.
On the origin of neural scaling laws: from random graphs to natural language
Jan 15, 2026Scaling laws have played a major role in the modern AI revolution, providing practitioners predictive power over how the model performance will improve with increasing data, compute, and number of model parameters. This has spurred an intense interest in the origin of neural scaling laws, with a common suggestion being that they arise from power law structure already present in the data. In this paper we study scaling laws for transformers trained to predict random walks (bigrams) on graphs with tunable complexity. We demonstrate that this simplified setting already gives rise to neural scaling laws even in the absence of power law structure in the data correlations. We further consider dialing down the complexity of natural language systematically, by training on sequences sampled from increasingly simplified generative language models, from 4,2,1-layer transformer language models down to language bigrams, revealing a monotonic evolution of the scaling exponents. Our results also include scaling laws obtained from training on random walks on random graphs drawn from Erdös-Renyi and scale-free Barabási-Albert ensembles. Finally, we revisit conventional scaling laws for language modeling, demonstrating that several essential results can be reproduced using 2 layer transformers with context length of 50, provide a critical analysis of various fits used in prior literature, demonstrate an alternative method for obtaining compute optimal curves as compared with current practice in published literature, and provide preliminary evidence that maximal update parameterization may be more parameter efficient than standard parameterization.
PARQ: Piecewise-Affine Regularized Quantization
Mar 19, 2025



We develop a principled method for quantization-aware training (QAT) of large-scale machine learning models. Specifically, we show that convex, piecewise-affine regularization (PAR) can effectively induce the model parameters to cluster towards discrete values. We minimize PAR-regularized loss functions using an aggregate proximal stochastic gradient method (AProx) and prove that it has last-iterate convergence. Our approach provides an interpretation of the straight-through estimator (STE), a widely used heuristic for QAT, as the asymptotic form of PARQ. We conduct experiments to demonstrate that PARQ obtains competitive performance on convolution- and transformer-based vision tasks.
Spectral Journey: How Transformers Predict the Shortest Path
Feb 12, 2025Decoder-only transformers lead to a step-change in capability of large language models. However, opinions are mixed as to whether they are really planning or reasoning. A path to making progress in this direction is to study the model's behavior in a setting with carefully controlled data. Then interpret the learned representations and reverse-engineer the computation performed internally. We study decoder-only transformer language models trained from scratch to predict shortest paths on simple, connected and undirected graphs. In this setting, the representations and the dynamics learned by the model are interpretable. We present three major results: (1) Two-layer decoder-only language models can learn to predict shortest paths on simple, connected graphs containing up to 10 nodes. (2) Models learn a graph embedding that is correlated with the spectral decomposition of the line graph. (3) Following the insights, we discover a novel approximate path-finding algorithm Spectral Line Navigator (SLN) that finds shortest path by greedily selecting nodes in the space of spectral embedding of the line graph.
Towards an Improved Understanding and Utilization of Maximum Manifold Capacity Representations
Jun 13, 2024Maximum Manifold Capacity Representations (MMCR) is a recent multi-view self-supervised learning (MVSSL) method that matches or surpasses other leading MVSSL methods. MMCR is intriguing because it does not fit neatly into any of the commonplace MVSSL lineages, instead originating from a statistical mechanical perspective on the linear separability of data manifolds. In this paper, we seek to improve our understanding and our utilization of MMCR. To better understand MMCR, we leverage tools from high dimensional probability to demonstrate that MMCR incentivizes alignment and uniformity of learned embeddings. We then leverage tools from information theory to show that such embeddings maximize a well-known lower bound on mutual information between views, thereby connecting the geometric perspective of MMCR to the information-theoretic perspective commonly discussed in MVSSL. To better utilize MMCR, we mathematically predict and experimentally confirm non-monotonic changes in the pretraining loss akin to double descent but with respect to atypical hyperparameters. We also discover compute scaling laws that enable predicting the pretraining loss as a function of gradients steps, batch size, embedding dimension and number of views. We then show that MMCR, originally applied to image data, is performant on multimodal image-text data. By more deeply understanding the theoretical and empirical behavior of MMCR, our work reveals insights on improving MVSSL methods.
Grokking Modular Polynomials
Jun 05, 2024
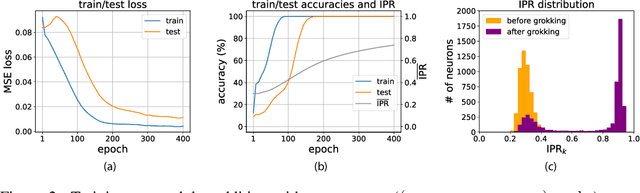

Neural networks readily learn a subset of the modular arithmetic tasks, while failing to generalize on the rest. This limitation remains unmoved by the choice of architecture and training strategies. On the other hand, an analytical solution for the weights of Multi-layer Perceptron (MLP) networks that generalize on the modular addition task is known in the literature. In this work, we (i) extend the class of analytical solutions to include modular multiplication as well as modular addition with many terms. Additionally, we show that real networks trained on these datasets learn similar solutions upon generalization (grokking). (ii) We combine these "expert" solutions to construct networks that generalize on arbitrary modular polynomials. (iii) We hypothesize a classification of modular polynomials into learnable and non-learnable via neural networks training; and provide experimental evidence supporting our claims.
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
Jun 04, 2024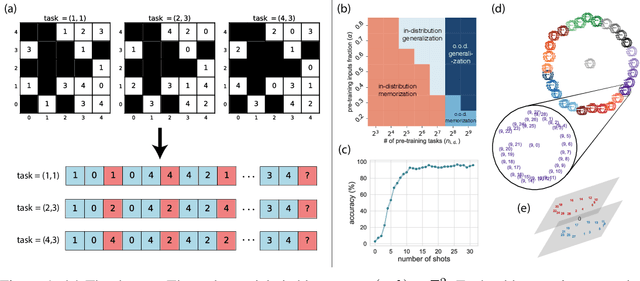
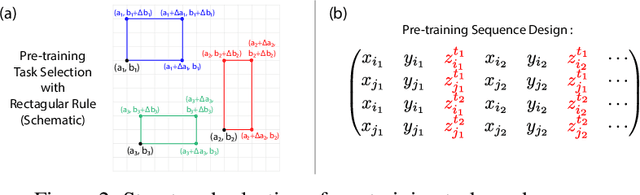
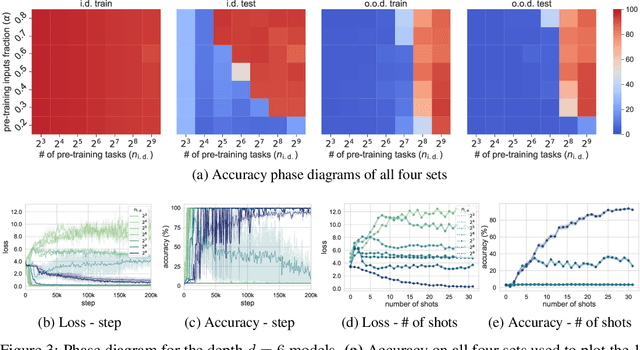
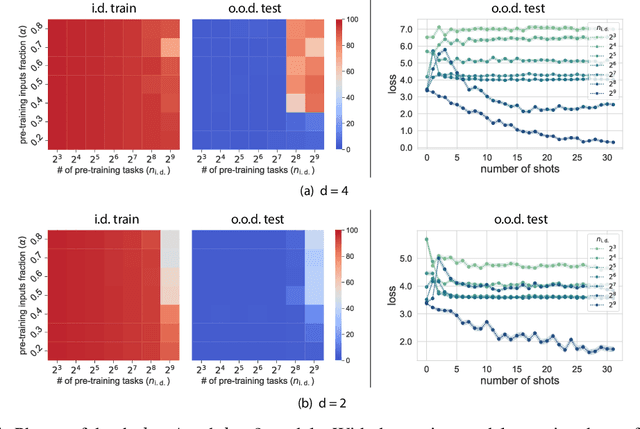
Large language models can solve tasks that were not present in the training set. This capability is believed to be due to in-context learning and skill composition. In this work, we study the emergence of in-context learning and skill composition in a collection of modular arithmetic tasks. Specifically, we consider a finite collection of linear modular functions $z = a \, x + b \, y \;\mathrm{mod}\; p$ labeled by the vector $(a, b) \in \mathbb{Z}_p^2$. We use some of these tasks for pre-training and the rest for out-of-distribution testing. We empirically show that a GPT-style transformer exhibits a transition from in-distribution to out-of-distribution generalization as the number of pre-training tasks increases. We find that the smallest model capable of out-of-distribution generalization requires two transformer blocks, while for deeper models, the out-of-distribution generalization phase is \emph{transient}, necessitating early stopping. Finally, we perform an interpretability study of the pre-trained models, revealing the highly structured representations in both phases; and discuss the learnt algorithm.
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Apr 01, 2024The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops discovered that such loops can lead to model collapse, a phenomenon where performance progressively degrades with each model-fitting iteration until the latest model becomes useless. However, several recent papers studying model collapse assumed that new data replace old data over time rather than assuming data accumulate over time. In this paper, we compare these two settings and show that accumulating data prevents model collapse. We begin by studying an analytically tractable setup in which a sequence of linear models are fit to the previous models' predictions. Previous work showed if data are replaced, the test error increases linearly with the number of model-fitting iterations; we extend this result by proving that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations. We next empirically test whether accumulating data similarly prevents model collapse by pretraining sequences of language models on text corpora. We confirm that replacing data does indeed cause model collapse, then demonstrate that accumulating data prevents model collapse; these results hold across a range of model sizes, architectures and hyperparameters. We further show that similar results hold for other deep generative models on real data: diffusion models for molecule generation and variational autoencoders for image generation. Our work provides consistent theoretical and empirical evidence that data accumulation mitigates model collapse.
The Unreasonable Ineffectiveness of the Deeper Layers
Mar 26, 2024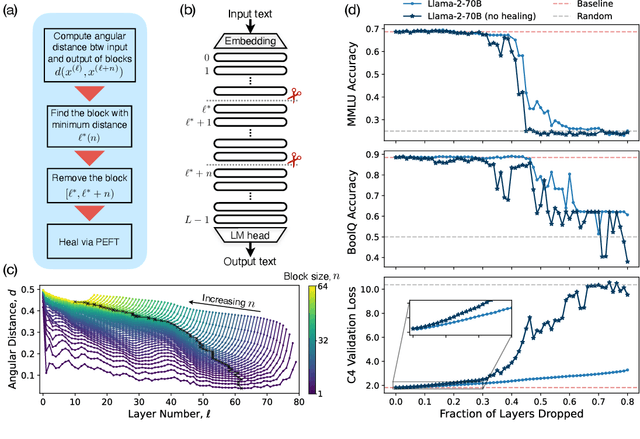
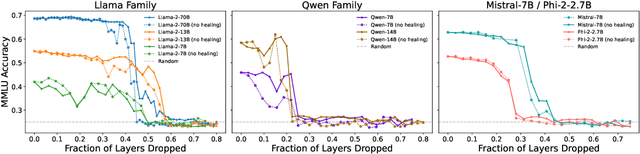
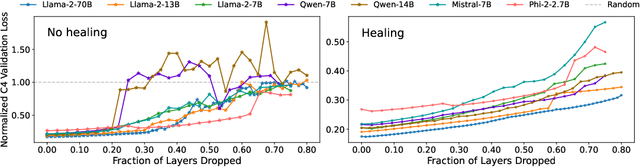
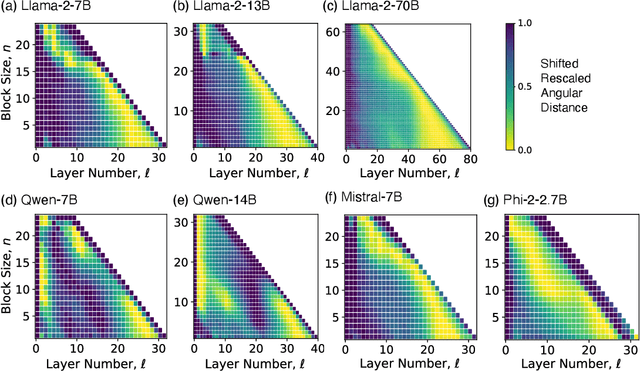
We empirically study a simple layer-pruning strategy for popular families of open-weight pretrained LLMs, finding minimal degradation of performance on different question-answering benchmarks until after a large fraction (up to half) of the layers are removed. To prune these models, we identify the optimal block of layers to prune by considering similarity across layers; then, to "heal" the damage, we perform a small amount of finetuning. In particular, we use parameter-efficient finetuning (PEFT) methods, specifically quantization and Low Rank Adapters (QLoRA), such that each of our experiments can be performed on a single A100 GPU. From a practical perspective, these results suggest that layer pruning methods can complement other PEFT strategies to further reduce computational resources of finetuning on the one hand, and can improve the memory and latency of inference on the other hand. From a scientific perspective, the robustness of these LLMs to the deletion of layers implies either that current pretraining methods are not properly leveraging the parameters in the deeper layers of the network or that the shallow layers play a critical role in storing knowledge.