 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking Modular Polynomials
Jun 05, 2024
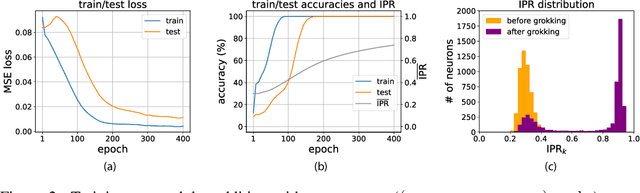

Neural networks readily learn a subset of the modular arithmetic tasks, while failing to generalize on the rest. This limitation remains unmoved by the choice of architecture and training strategies. On the other hand, an analytical solution for the weights of Multi-layer Perceptron (MLP) networks that generalize on the modular addition task is known in the literature. In this work, we (i) extend the class of analytical solutions to include modular multiplication as well as modular addition with many terms. Additionally, we show that real networks trained on these datasets learn similar solutions upon generalization (grokking). (ii) We combine these "expert" solutions to construct networks that generalize on arbitrary modular polynomials. (iii) We hypothesize a classification of modular polynomials into learnable and non-learnable via neural networks training; and provide experimental evidence supporting our claims.
Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks
Jun 04, 2024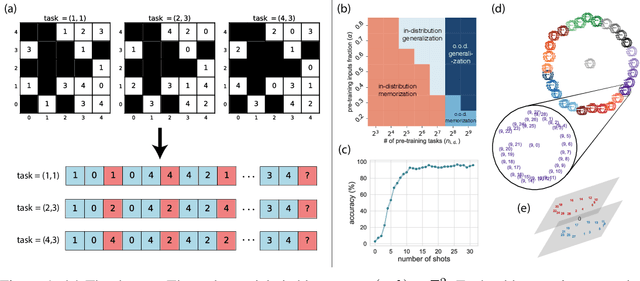
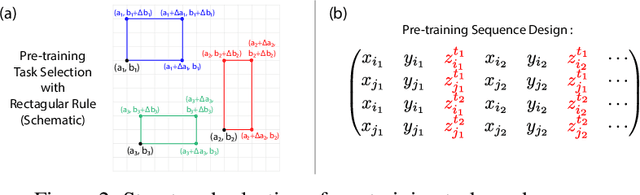
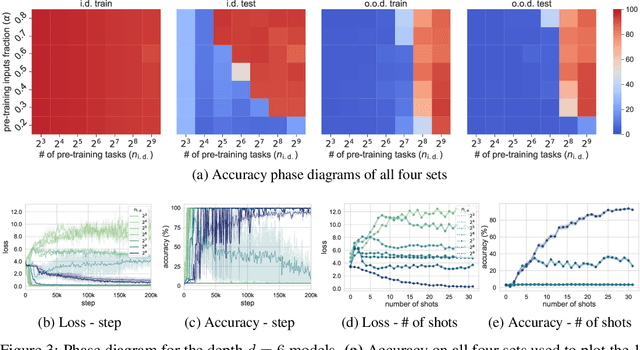
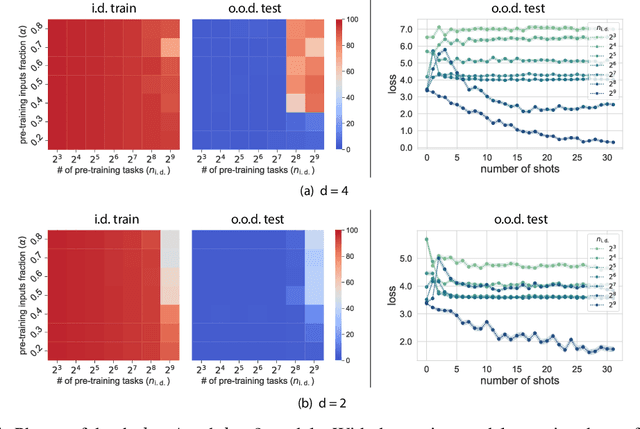
Large language models can solve tasks that were not present in the training set. This capability is believed to be due to in-context learning and skill composition. In this work, we study the emergence of in-context learning and skill composition in a collection of modular arithmetic tasks. Specifically, we consider a finite collection of linear modular functions $z = a \, x + b \, y \;\mathrm{mod}\; p$ labeled by the vector $(a, b) \in \mathbb{Z}_p^2$. We use some of these tasks for pre-training and the rest for out-of-distribution testing. We empirically show that a GPT-style transformer exhibits a transition from in-distribution to out-of-distribution generalization as the number of pre-training tasks increases. We find that the smallest model capable of out-of-distribution generalization requires two transformer blocks, while for deeper models, the out-of-distribution generalization phase is \emph{transient}, necessitating early stopping. Finally, we perform an interpretability study of the pre-trained models, revealing the highly structured representations in both phases; and discuss the learnt algorithm.
To grok or not to grok: Disentangling generalization and memorization on corrupted algorithmic datasets
Oct 19, 2023



Robust generalization is a major challenge in deep learning, particularly when the number of trainable parameters is very large. In general, it is very difficult to know if the network has memorized a particular set of examples or understood the underlying rule (or both). Motivated by this challenge, we study an interpretable model where generalizing representations are understood analytically, and are easily distinguishable from the memorizing ones. Namely, we consider two-layer neural networks trained on modular arithmetic tasks where ($\xi \cdot 100\%$) of labels are corrupted (\emph{i.e.} some results of the modular operations in the training set are incorrect). We show that (i) it is possible for the network to memorize the corrupted labels \emph{and} achieve $100\%$ generalization at the same time; (ii) the memorizing neurons can be identified and pruned, lowering the accuracy on corrupted data and improving the accuracy on uncorrupted data; (iii) regularization methods such as weight decay, dropout and BatchNorm force the network to ignore the corrupted data during optimization, and achieve $100\%$ accuracy on the uncorrupted dataset; and (iv) the effect of these regularization methods is (``mechanistically'') interpretable: weight decay and dropout force all the neurons to learn generalizing representations, while BatchNorm de-amplifies the output of memorizing neurons and amplifies the output of the generalizing ones. Finally, we show that in the presence of regularization, the training dynamics involves two consecutive stages: first, the network undergoes the \emph{grokking} dynamics reaching high train \emph{and} test accuracy; second, it unlearns the memorizing representations, where train accuracy suddenly jumps from $100\%$ to $100 (1-\xi)\%$.
AutoInit: Automatic Initialization via Jacobian Tuning
Jun 27, 2022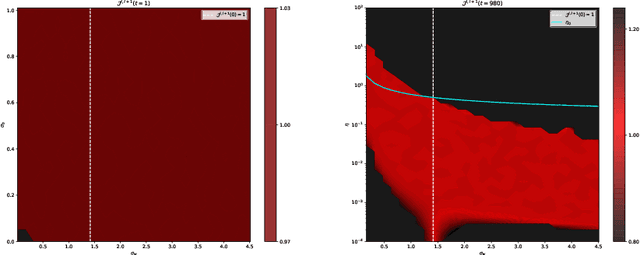
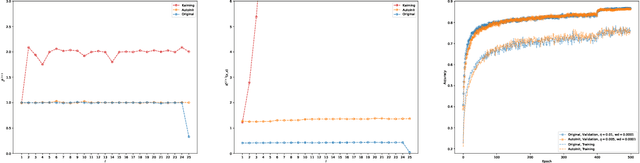
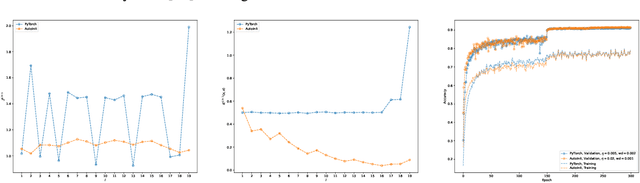
Good initialization is essential for training Deep Neural Networks (DNNs). Oftentimes such initialization is found through a trial and error approach, which has to be applied anew every time an architecture is substantially modified, or inherited from smaller size networks leading to sub-optimal initialization. In this work we introduce a new and cheap algorithm, that allows one to find a good initialization automatically, for general feed-forward DNNs. The algorithm utilizes the Jacobian between adjacent network blocks to tune the network hyperparameters to criticality. We solve the dynamics of the algorithm for fully connected networks with ReLU and derive conditions for its convergence. We then extend the discussion to more general architectures with BatchNorm and residual connections. Finally, we apply our method to ResMLP and VGG architectures, where the automatic one-shot initialization found by our method shows good performance on vision tasks.
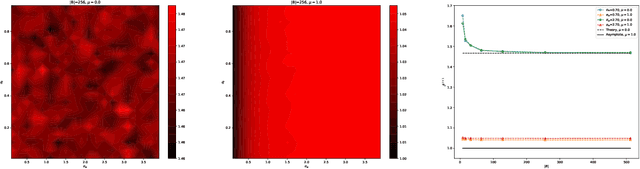
Critical initialization of wide and deep neural networks through partial Jacobians: general theory and applications to LayerNorm
Nov 30, 2021
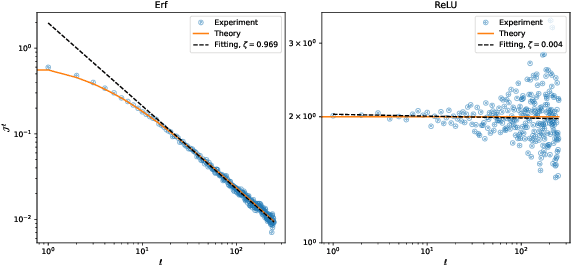
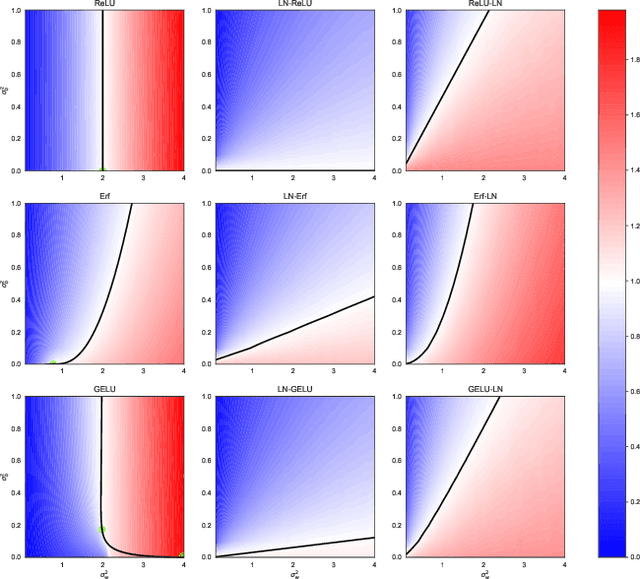
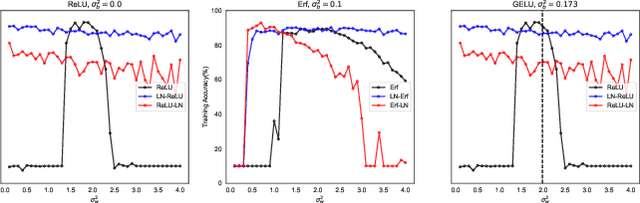
Deep neural networks are notorious for defying theoretical treatment. However, when the number of parameters in each layer tends to infinity the network function is a Gaussian process (GP) and quantitatively predictive description is possible. Gaussian approximation allows to formulate criteria for selecting hyperparameters, such as variances of weights and biases, as well as the learning rate. These criteria rely on the notion of criticality defined for deep neural networks. In this work we describe a new way to diagnose (both theoretically and empirically) this criticality. To that end, we introduce partial Jacobians of a network, defined as derivatives of preactivations in layer $l$ with respect to preactivations in layer $l_0<l$. These quantities are particularly useful when the network architecture involves many different layers. We discuss various properties of the partial Jacobians such as their scaling with depth and relation to the neural tangent kernel (NTK). We derive the recurrence relations for the partial Jacobians and utilize them to analyze criticality of deep MLP networks with (and without) LayerNorm. We find that the normalization layer changes the optimal values of hyperparameters and critical exponents. We argue that LayerNorm is more stable when applied to preactivations, rather than activations due to larger correlation depth.