 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical initialization of wide and deep neural networks through partial Jacobians: general theory and applications to LayerNorm
Paper and Code
Nov 30, 2021
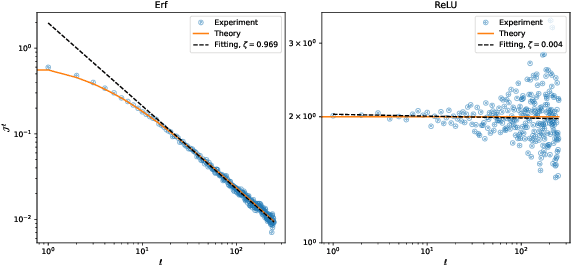
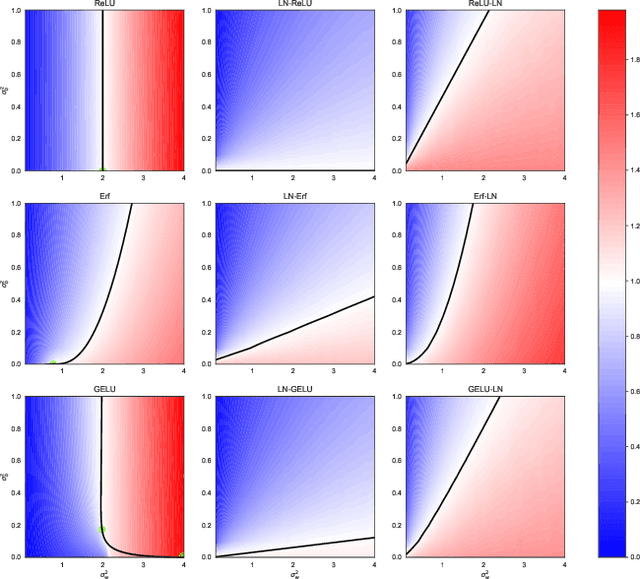
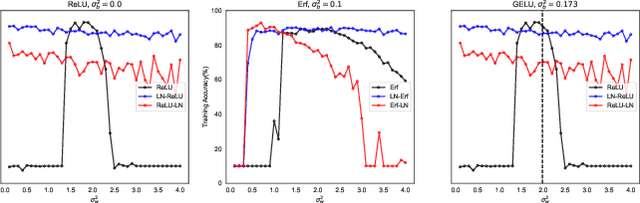
Deep neural networks are notorious for defying theoretical treatment. However, when the number of parameters in each layer tends to infinity the network function is a Gaussian process (GP) and quantitatively predictive description is possible. Gaussian approximation allows to formulate criteria for selecting hyperparameters, such as variances of weights and biases, as well as the learning rate. These criteria rely on the notion of criticality defined for deep neural networks. In this work we describe a new way to diagnose (both theoretically and empirically) this criticality. To that end, we introduce partial Jacobians of a network, defined as derivatives of preactivations in layer $l$ with respect to preactivations in layer $l_0<l$. These quantities are particularly useful when the network architecture involves many different layers. We discuss various properties of the partial Jacobians such as their scaling with depth and relation to the neural tangent kernel (NTK). We derive the recurrence relations for the partial Jacobians and utilize them to analyze criticality of deep MLP networks with (and without) LayerNorm. We find that the normalization layer changes the optimal values of hyperparameters and critical exponents. We argue that LayerNorm is more stable when applied to preactivations, rather than activations due to larger correlation depth.