 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDERAIL: Diagnostic Environments for Reward And Imitation Learning
Paper and Code

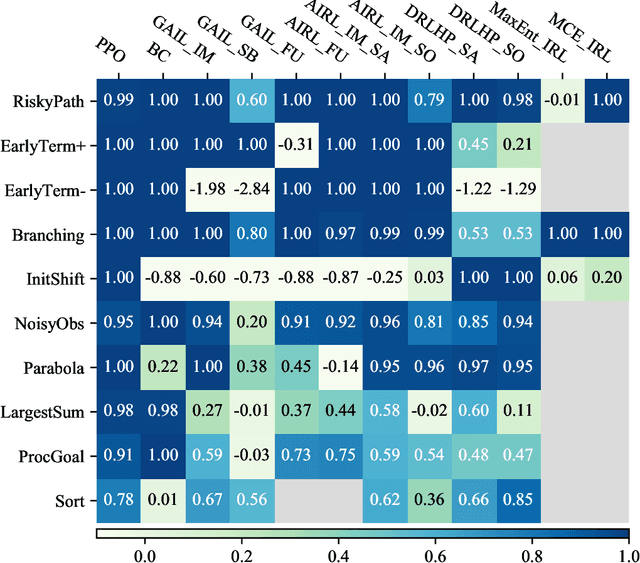


The objective of many real-world tasks is complex and difficult to procedurally specify. This makes it necessary to use reward or imitation learning algorithms to infer a reward or policy directly from human data. Existing benchmarks for these algorithms focus on realism, testing in complex environments. Unfortunately, these benchmarks are slow, unreliable and cannot isolate failures. As a complementary approach, we develop a suite of simple diagnostic tasks that test individual facets of algorithm performance in isolation. We evaluate a range of common reward and imitation learning algorithms on our tasks. Our results confirm that algorithm performance is highly sensitive to implementation details. Moreover, in a case-study into a popular preference-based reward learning implementation, we illustrate how the suite can pinpoint design flaws and rapidly evaluate candidate solutions. The environments are available at https://github.com/HumanCompatibleAI/seals .