 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree energy Estimation on Any State Space
May 29, 2026Free energy estimation is a fundamental yet challenging problem, from physics to statistics. Classical approaches rely on thermodynamic transformations, ranging from direct estimation, quasistatic integration, to finite-time averaging. Recent work [He and Du et al., 2025] learns neural transports to significantly accelerate the efficiency in the finite-time regime. In this paper, we generalize this framework to arbitrary state spaces. Building on this view, we develop a generalized neural transport learning approach for efficient estimation. Experiments validate the effectiveness and efficiency of the proposed method beyond continuous settings, extending to discrete and multimodal spaces as well as autoregressive settings. Beyond free energy estimation, we establish algebraic identities and reveal a group-theoretic structure linking infinitesimal time reversal and generalized Doob's $h$-transforms, showing that their compositions form a generalized dihedral group.
CMAD: Cooperative Multi-Agent Diffusion via Stochastic Optimal Control
Feb 11, 2026Continuous-time generative models have achieved remarkable success in image restoration and synthesis. However, controlling the composition of multiple pre-trained models remains an open challenge. Current approaches largely treat composition as an algebraic composition of probability densities, such as via products or mixtures of experts. This perspective assumes the target distribution is known explicitly, which is almost never the case. In this work, we propose a different paradigm that formulates compositional generation as a cooperative Stochastic Optimal Control problem. Rather than combining probability densities, we treat pre-trained diffusion models as interacting agents whose diffusion trajectories are jointly steered, via optimal control, toward a shared objective defined on their aggregated output. We validate our framework on conditional MNIST generation and compare it against a naive inference-time DPS-style baseline replacing learned cooperative control with per-step gradient guidance.
Sampling from Energy distributions with Target Concrete Score Identity
Oct 27, 2025We introduce the Target Concrete Score Identity Sampler (TCSIS), a method for sampling from unnormalized densities on discrete state spaces by learning the reverse dynamics of a Continuous-Time Markov Chain (CTMC). Our approach builds on a forward in time CTMC with a uniform noising kernel and relies on the proposed Target Concrete Score Identity, which relates the concrete score, the ratio of marginal probabilities of two states, to a ratio of expectations of Boltzmann factors under the forward uniform diffusion kernel. This formulation enables Monte Carlo estimation of the concrete score without requiring samples from the target distribution or computation of the partition function. We approximate the concrete score with a neural network and propose two algorithms: Self-Normalized TCSIS and Unbiased TCSIS. Finally, we demonstrate the effectiveness of TCSIS on problems from statistical physics.
The impact of fine tuning in LLaMA on hallucinations for named entity extraction in legal documentation
Jun 10, 2025


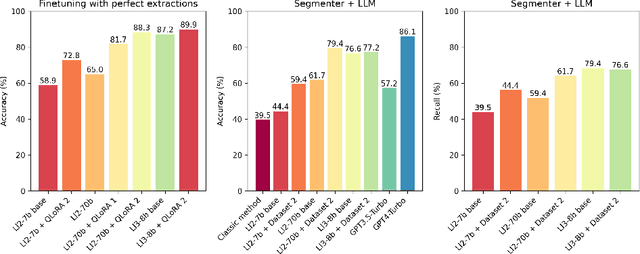
The extraction of information about traffic accidents from legal documents is crucial for quantifying insurance company costs. Extracting entities such as percentages of physical and/or psychological disability and the involved compensation amounts is a challenging process, even for experts, due to the subtle arguments and reasoning in the court decision. A two-step procedure is proposed: first, segmenting the document identifying the most relevant segments, and then extracting the entities. For text segmentation, two methodologies are compared: a classic method based on regular expressions and a second approach that divides the document into blocks of n-tokens, which are then vectorized using multilingual models for semantic searches (text-embedding-ada-002/MiniLM-L12-v2 ). Subsequently, large language models (LLaMA-2 7b, 70b, LLaMA-3 8b, and GPT-4 Turbo) are applied with prompting to the selected segments for entity extraction. For the LLaMA models, fine-tuning is performed using LoRA. LLaMA-2 7b, even with zero temperature, shows a significant number of hallucinations in extractions which are an important contention point for named entity extraction. This work shows that these hallucinations are substantially reduced after finetuning the model. The performance of the methodology based on segment vectorization and subsequent use of LLMs significantly surpasses the classic method which achieves an accuracy of 39.5%. Among open-source models, LLaMA-2 70B with finetuning achieves the highest accuracy 79.4%, surpassing its base version 61.7%. Notably, the base LLaMA-3 8B model already performs comparably to the finetuned LLaMA-2 70B model, achieving 76.6%, highlighting the rapid progress in model development. Meanwhile, GPT-4 Turbo achieves the highest accuracy at 86.1%.
Path Integral Optimiser: Global Optimisation via Neural Schrödinger-Föllmer Diffusion
Jun 07, 2025We present an early investigation into the use of neural diffusion processes for global optimisation, focusing on Zhang et al.'s Path Integral Sampler. One can use the Boltzmann distribution to formulate optimization as solving a Schr\"odinger bridge sampling problem, then apply Girsanov's theorem with a simple (single-point) prior to frame it in stochastic control terms, and compute the solution's integral terms via a neural approximation (a Fourier MLP). We provide theoretical bounds for this optimiser, results on toy optimisation tasks, and a summary of the stochastic theory motivating the model. Ultimately, we found the optimiser to display promising per-step performance at optimisation tasks between 2 and 1,247 dimensions, but struggle to explore higher-dimensional spaces when faced with a 15.9k parameter model, indicating a need for work on adaptation in such environments.
RNE: a plug-and-play framework for diffusion density estimation and inference-time control
Jun 06, 2025



In this paper, we introduce the Radon-Nikodym Estimator (RNE), a flexible, plug-and-play framework for diffusion inference-time density estimation and control, based on the concept of the density ratio between path distributions. RNE connects and unifies a variety of existing density estimation and inference-time control methods under a single and intuitive perspective, stemming from basic variational inference and probabilistic principles therefore offering both theoretical clarity and practical versatility. Experiments demonstrate that RNE achieves promising performances in diffusion density estimation and inference-time control tasks, including annealing, composition of diffusion models, and reward-tilting.
FEAT: Free energy Estimators with Adaptive Transport
Apr 15, 2025



We present Free energy Estimators with Adaptive Transport (FEAT), a novel framework for free energy estimation -- a critical challenge across scientific domains. FEAT leverages learned transports implemented via stochastic interpolants and provides consistent, minimum-variance estimators based on escorted Jarzynski equality and controlled Crooks theorem, alongside variational upper and lower bounds on free energy differences. Unifying equilibrium and non-equilibrium methods under a single theoretical framework, FEAT establishes a principled foundation for neural free energy calculations. Experimental validation on toy examples, molecular simulations, and quantum field theory demonstrates improvements over existing learning-based methods.
No Trick, No Treat: Pursuits and Challenges Towards Simulation-free Training of Neural Samplers
Feb 10, 2025



We consider the sampling problem, where the aim is to draw samples from a distribution whose density is known only up to a normalization constant. Recent breakthroughs in generative modeling to approximate a high-dimensional data distribution have sparked significant interest in developing neural network-based methods for this challenging problem. However, neural samplers typically incur heavy computational overhead due to simulating trajectories during training. This motivates the pursuit of simulation-free training procedures of neural samplers. In this work, we propose an elegant modification to previous methods, which allows simulation-free training with the help of a time-dependent normalizing flow. However, it ultimately suffers from severe mode collapse. On closer inspection, we find that nearly all successful neural samplers rely on Langevin preconditioning to avoid mode collapsing. We systematically analyze several popular methods with various objective functions and demonstrate that, in the absence of Langevin preconditioning, most of them fail to adequately cover even a simple target. Finally, we draw attention to a strong baseline by combining the state-of-the-art MCMC method, Parallel Tempering (PT), with an additional generative model to shed light on future explorations of neural samplers.
Debiasing Guidance for Discrete Diffusion with Sequential Monte Carlo
Feb 10, 2025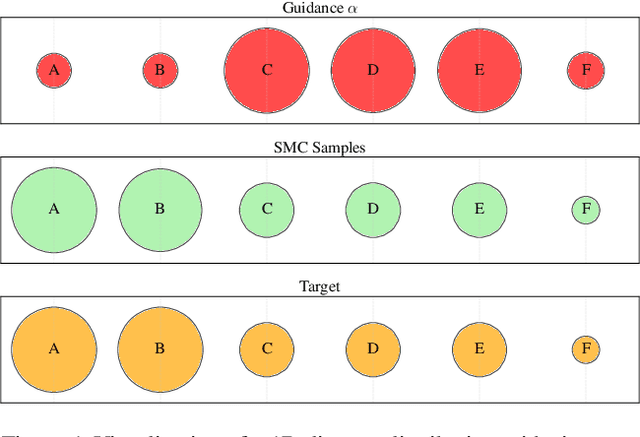
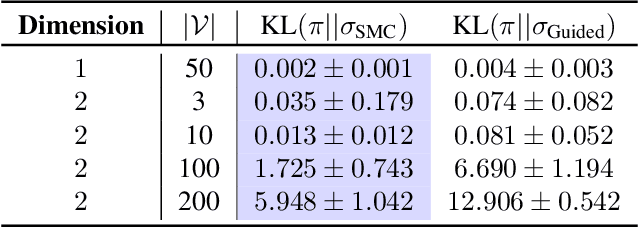
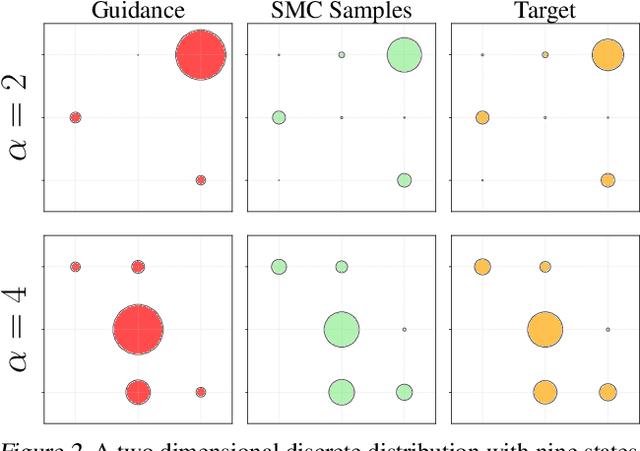

Discrete diffusion models are a class of generative models that produce samples from an approximated data distribution within a discrete state space. Often, there is a need to target specific regions of the data distribution. Current guidance methods aim to sample from a distribution with mass proportional to $p_0(x_0) p(\zeta|x_0)^\alpha$ but fail to achieve this in practice. We introduce a Sequential Monte Carlo algorithm that generates unbiasedly from this target distribution, utilising the learnt unconditional and guided process. We validate our approach on low-dimensional distributions, controlled images and text generations. For text generation, our method provides strong control while maintaining low perplexity compared to guidance-based approaches.
Iterative Importance Fine-tuning of Diffusion Models
Feb 06, 2025Diffusion models are an important tool for generative modelling, serving as effective priors in applications such as imaging and protein design. A key challenge in applying diffusion models for downstream tasks is efficiently sampling from resulting posterior distributions, which can be addressed using the $h$-transform. This work introduces a self-supervised algorithm for fine-tuning diffusion models by estimating the $h$-transform, enabling amortised conditional sampling. Our method iteratively refines the $h$-transform using a synthetic dataset resampled with path-based importance weights. We demonstrate the effectiveness of this framework on class-conditional sampling and reward fine-tuning for text-to-image diffusion models.