 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Trick, No Treat: Pursuits and Challenges Towards Simulation-free Training of Neural Samplers
Feb 10, 2025



We consider the sampling problem, where the aim is to draw samples from a distribution whose density is known only up to a normalization constant. Recent breakthroughs in generative modeling to approximate a high-dimensional data distribution have sparked significant interest in developing neural network-based methods for this challenging problem. However, neural samplers typically incur heavy computational overhead due to simulating trajectories during training. This motivates the pursuit of simulation-free training procedures of neural samplers. In this work, we propose an elegant modification to previous methods, which allows simulation-free training with the help of a time-dependent normalizing flow. However, it ultimately suffers from severe mode collapse. On closer inspection, we find that nearly all successful neural samplers rely on Langevin preconditioning to avoid mode collapsing. We systematically analyze several popular methods with various objective functions and demonstrate that, in the absence of Langevin preconditioning, most of them fail to adequately cover even a simple target. Finally, we draw attention to a strong baseline by combining the state-of-the-art MCMC method, Parallel Tempering (PT), with an additional generative model to shed light on future explorations of neural samplers.
Iterative Importance Fine-tuning of Diffusion Models
Feb 06, 2025Diffusion models are an important tool for generative modelling, serving as effective priors in applications such as imaging and protein design. A key challenge in applying diffusion models for downstream tasks is efficiently sampling from resulting posterior distributions, which can be addressed using the $h$-transform. This work introduces a self-supervised algorithm for fine-tuning diffusion models by estimating the $h$-transform, enabling amortised conditional sampling. Our method iteratively refines the $h$-transform using a synthetic dataset resampled with path-based importance weights. We demonstrate the effectiveness of this framework on class-conditional sampling and reward fine-tuning for text-to-image diffusion models.
DEFT: Efficient Finetuning of Conditional Diffusion Models by Learning the Generalised $h$-transform
Jun 03, 2024Generative modelling paradigms based on denoising diffusion processes have emerged as a leading candidate for conditional sampling in inverse problems. In many real-world applications, we often have access to large, expensively trained unconditional diffusion models, which we aim to exploit for improving conditional sampling. Most recent approaches are motivated heuristically and lack a unifying framework, obscuring connections between them. Further, they often suffer from issues such as being very sensitive to hyperparameters, being expensive to train or needing access to weights hidden behind a closed API. In this work, we unify conditional training and sampling using the mathematically well-understood Doob's h-transform. This new perspective allows us to unify many existing methods under a common umbrella. Under this framework, we propose DEFT (Doob's h-transform Efficient FineTuning), a new approach for conditional generation that simply fine-tunes a very small network to quickly learn the conditional $h$-transform, while keeping the larger unconditional network unchanged. DEFT is much faster than existing baselines while achieving state-of-the-art performance across a variety of linear and non-linear benchmarks. On image reconstruction tasks, we achieve speedups of up to 1.6$\times$, while having the best perceptual quality on natural images and reconstruction performance on medical images.
Warm Start Marginal Likelihood Optimisation for Iterative Gaussian Processes
May 28, 2024



Gaussian processes are a versatile probabilistic machine learning model whose effectiveness often depends on good hyperparameters, which are typically learned by maximising the marginal likelihood. In this work, we consider iterative methods, which use iterative linear system solvers to approximate marginal likelihood gradients up to a specified numerical precision, allowing a trade-off between compute time and accuracy of a solution. We introduce a three-level hierarchy of marginal likelihood optimisation for iterative Gaussian processes, and identify that the computational costs are dominated by solving sequential batches of large positive-definite systems of linear equations. We then propose to amortise computations by reusing solutions of linear system solvers as initialisations in the next step, providing a $\textit{warm start}$. Finally, we discuss the necessary conditions and quantify the consequences of warm starts and demonstrate their effectiveness on regression tasks, where warm starts achieve the same results as the conventional procedure while providing up to a $16 \times$ average speed-up among datasets.
Improving Linear System Solvers for Hyperparameter Optimisation in Iterative Gaussian Processes
May 28, 2024



Scaling hyperparameter optimisation to very large datasets remains an open problem in the Gaussian process community. This paper focuses on iterative methods, which use linear system solvers, like conjugate gradients, alternating projections or stochastic gradient descent, to construct an estimate of the marginal likelihood gradient. We discuss three key improvements which are applicable across solvers: (i) a pathwise gradient estimator, which reduces the required number of solver iterations and amortises the computational cost of making predictions, (ii) warm starting linear system solvers with the solution from the previous step, which leads to faster solver convergence at the cost of negligible bias, (iii) early stopping linear system solvers after a limited computational budget, which synergises with warm starting, allowing solver progress to accumulate over multiple marginal likelihood steps. These techniques provide speed-ups of up to $72\times$ when solving to tolerance, and decrease the average residual norm by up to $7\times$ when stopping early.
A Generative Model of Symmetry Transformations
Mar 04, 2024Correctly capturing the symmetry transformations of data can lead to efficient models with strong generalization capabilities, though methods incorporating symmetries often require prior knowledge. While recent advancements have been made in learning those symmetries directly from the dataset, most of this work has focused on the discriminative setting. In this paper, we construct a generative model that explicitly aims to capture symmetries in the data, resulting in a model that learns which symmetries are present in an interpretable way. We provide a simple algorithm for efficiently learning our generative model and demonstrate its ability to capture symmetries under affine and color transformations. Combining our symmetry model with existing generative models results in higher marginal test-log-likelihoods and robustness to data sparsification.
Stochastic Gradient Descent for Gaussian Processes Done Right
Oct 31, 2023



We study the optimisation problem associated with Gaussian process regression using squared loss. The most common approach to this problem is to apply an exact solver, such as conjugate gradient descent, either directly, or to a reduced-order version of the problem. Recently, driven by successes in deep learning, stochastic gradient descent has gained traction as an alternative. In this paper, we show that when done right$\unicode{x2014}$by which we mean using specific insights from the optimisation and kernel communities$\unicode{x2014}$this approach is highly effective. We thus introduce a particular stochastic dual gradient descent algorithm, that may be implemented with a few lines of code using any deep learning framework. We explain our design decisions by illustrating their advantage against alternatives with ablation studies and show that the new method is highly competitive. Our evaluations on standard regression benchmarks and a Bayesian optimisation task set our approach apart from preconditioned conjugate gradients, variational Gaussian process approximations, and a previous version of stochastic gradient descent for Gaussian processes. On a molecular binding affinity prediction task, our method places Gaussian process regression on par in terms of performance with state-of-the-art graph neural networks.
Sampling from Gaussian Process Posteriors using Stochastic Gradient Descent
Jun 20, 2023Gaussian processes are a powerful framework for quantifying uncertainty and for sequential decision-making but are limited by the requirement of solving linear systems. In general, this has a cubic cost in dataset size and is sensitive to conditioning. We explore stochastic gradient algorithms as a computationally efficient method of approximately solving these linear systems: we develop low-variance optimization objectives for sampling from the posterior and extend these to inducing points. Counterintuitively, stochastic gradient descent often produces accurate predictions, even in cases where it does not converge quickly to the optimum. We explain this through a spectral characterization of the implicit bias from non-convergence. We show that stochastic gradient descent produces predictive distributions close to the true posterior both in regions with sufficient data coverage, and in regions sufficiently far away from the data. Experimentally, stochastic gradient descent achieves state-of-the-art performance on sufficiently large-scale or ill-conditioned regression tasks. Its uncertainty estimates match the performance of significantly more expensive baselines on a large-scale Bayesian~optimization~task.
Kernel Regression with Infinite-Width Neural Networks on Millions of Examples
Mar 09, 2023Neural kernels have drastically increased performance on diverse and nonstandard data modalities but require significantly more compute, which previously limited their application to smaller datasets. In this work, we address this by massively parallelizing their computation across many GPUs. We combine this with a distributed, preconditioned conjugate gradients algorithm to enable kernel regression at a large scale (i.e. up to five million examples). Using this approach, we study scaling laws of several neural kernels across many orders of magnitude for the CIFAR-5m dataset. Using data augmentation to expand the original CIFAR-10 training dataset by a factor of 20, we obtain a test accuracy of 91.2\% (SotA for a pure kernel method). Moreover, we explore neural kernels on other data modalities, obtaining results on protein and small molecule prediction tasks that are competitive with SotA methods.
Sampling-based inference for large linear models, with application to linearised Laplace
Oct 10, 2022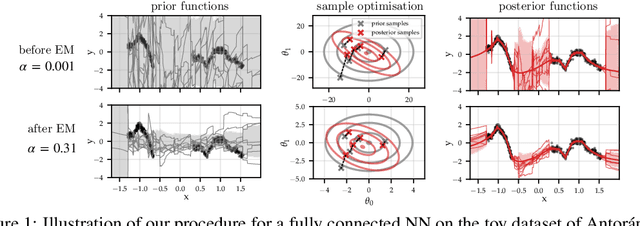
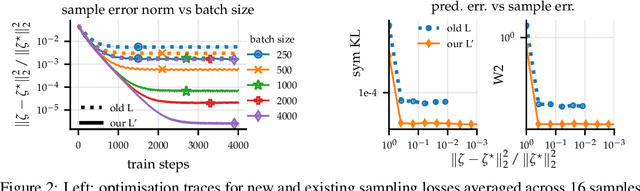

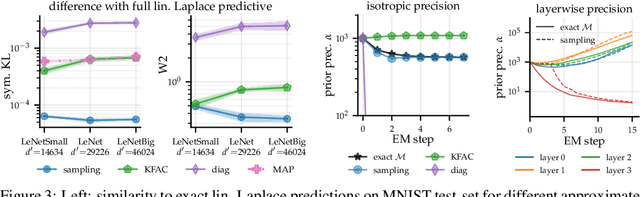
Large-scale linear models are ubiquitous throughout machine learning, with contemporary application as surrogate models for neural network uncertainty quantification; that is, the linearised Laplace method. Alas, the computational cost associated with Bayesian linear models constrains this method's application to small networks, small output spaces and small datasets. We address this limitation by introducing a scalable sample-based Bayesian inference method for conjugate Gaussian multi-output linear models, together with a matching method for hyperparameter (regularisation) selection. Furthermore, we use a classic feature normalisation method (the g-prior) to resolve a previously highlighted pathology of the linearised Laplace method. Together, these contributions allow us to perform linearised neural network inference with ResNet-18 on CIFAR100 (11M parameters, 100 output dimensions x 50k datapoints) and with a U-Net on a high-resolution tomographic reconstruction task (2M parameters, 251k output dimensions).