 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLOWER: Democratizing Generalist Robot Policies with Efficient Vision-Language-Action Flow Policies
Sep 05, 2025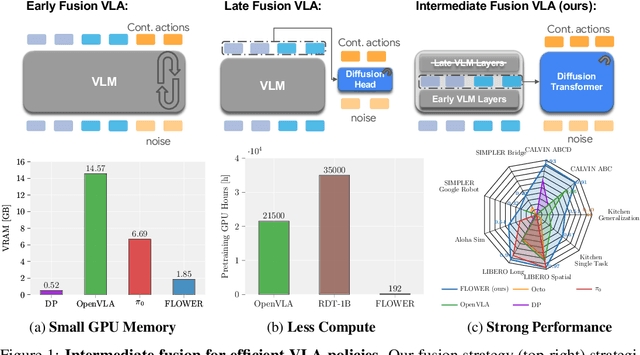

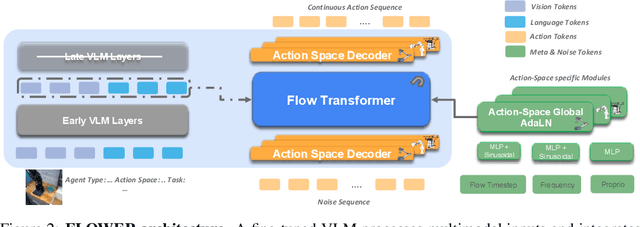
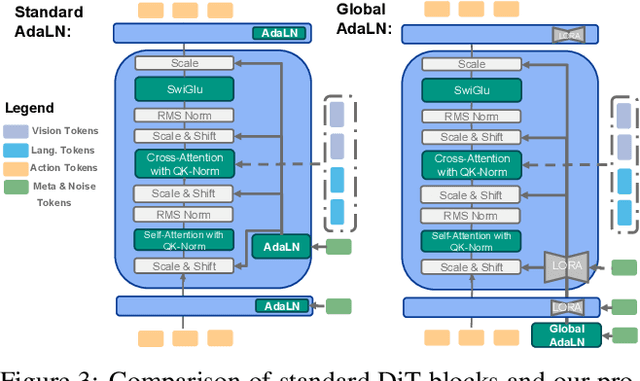
Developing efficient Vision-Language-Action (VLA) policies is crucial for practical robotics deployment, yet current approaches face prohibitive computational costs and resource requirements. Existing diffusion-based VLA policies require multi-billion-parameter models and massive datasets to achieve strong performance. We tackle this efficiency challenge with two contributions: intermediate-modality fusion, which reallocates capacity to the diffusion head by pruning up to $50\%$ of LLM layers, and action-specific Global-AdaLN conditioning, which cuts parameters by $20\%$ through modular adaptation. We integrate these advances into a novel 950 M-parameter VLA called FLOWER. Pretrained in just 200 H100 GPU hours, FLOWER delivers competitive performance with bigger VLAs across $190$ tasks spanning ten simulation and real-world benchmarks and demonstrates robustness across diverse robotic embodiments. In addition, FLOWER achieves a new SoTA of 4.53 on the CALVIN ABC benchmark. Demos, code and pretrained weights are available at https://intuitive-robots.github.io/flower_vla/.
BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Jun 06, 2025We present the B-spline Encoded Action Sequence Tokenizer (BEAST), a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-splines. In contrast to existing action tokenizers based on vector quantization or byte pair encoding, BEAST requires no separate tokenizer training and consistently produces tokens of uniform length, enabling fast action sequence generation via parallel decoding. Leveraging our B-spline formulation, BEAST inherently ensures generating smooth trajectories without discontinuities between adjacent segments. We extensively evaluate BEAST by integrating it with three distinct model architectures: a Variational Autoencoder (VAE) with continuous tokens, a decoder-only Transformer with discrete tokens, and Florence-2, a pretrained Vision-Language Model with an encoder-decoder architecture, demonstrating BEAST's compatibility and scalability with large pretrained models. We evaluate BEAST across three established benchmarks consisting of 166 simulated tasks and on three distinct robot settings with a total of 8 real-world tasks. Experimental results demonstrate that BEAST (i) significantly reduces both training and inference computational costs, and (ii) consistently generates smooth, high-frequency control signals suitable for continuous control tasks while (iii) reliably achieves competitive task success rates compared to state-of-the-art methods.
Vlearn: Off-Policy Learning with Efficient State-Value Function Estimation
Mar 07, 2024



Existing off-policy reinforcement learning algorithms typically necessitate an explicit state-action-value function representation, which becomes problematic in high-dimensional action spaces. These algorithms often encounter challenges where they struggle with the curse of dimensionality, as maintaining a state-action-value function in such spaces becomes data-inefficient. In this work, we propose a novel off-policy trust region optimization approach, called Vlearn, that eliminates the requirement for an explicit state-action-value function. Instead, we demonstrate how to efficiently leverage just a state-value function as the critic, thus overcoming several limitations of existing methods. By doing so, Vlearn addresses the computational challenges posed by high-dimensional action spaces. Furthermore, Vlearn introduces an efficient approach to address the challenges associated with pure state-value function learning in the off-policy setting. This approach not only simplifies the implementation of off-policy policy gradient algorithms but also leads to consistent and robust performance across various benchmark tasks. Specifically, by removing the need for a state-action-value function Vlearn simplifies the learning process and allows for more efficient exploration and exploitation in complex environments
Open the Black Box: Step-based Policy Updates for Temporally-Correlated Episodic Reinforcement Learning
Jan 21, 2024Current advancements in reinforcement learning (RL) have predominantly focused on learning step-based policies that generate actions for each perceived state. While these methods efficiently leverage step information from environmental interaction, they often ignore the temporal correlation between actions, resulting in inefficient exploration and unsmooth trajectories that are challenging to implement on real hardware. Episodic RL (ERL) seeks to overcome these challenges by exploring in parameters space that capture the correlation of actions. However, these approaches typically compromise data efficiency, as they treat trajectories as opaque \emph{black boxes}. In this work, we introduce a novel ERL algorithm, Temporally-Correlated Episodic RL (TCE), which effectively utilizes step information in episodic policy updates, opening the 'black box' in existing ERL methods while retaining the smooth and consistent exploration in parameter space. TCE synergistically combines the advantages of step-based and episodic RL, achieving comparable performance to recent ERL methods while maintaining data efficiency akin to state-of-the-art (SoTA) step-based RL.
MP3: Movement Primitive-Based (Re-)Planning Policy
Jul 02, 2023

We introduce a novel deep reinforcement learning (RL) approach called Movement Primitive-based Planning Policy (MP3). By integrating movement primitives (MPs) into the deep RL framework, MP3 enables the generation of smooth trajectories throughout the whole learning process while effectively learning from sparse and non-Markovian rewards. Additionally, MP3 maintains the capability to adapt to changes in the environment during execution. Although many early successes in robot RL have been achieved by combining RL with MPs, these approaches are often limited to learning single stroke-based motions, lacking the ability to adapt to task variations or adjust motions during execution. Building upon our previous work, which introduced an episode-based RL method for the non-linear adaptation of MP parameters to different task variations, this paper extends the approach to incorporating replanning strategies. This allows adaptation of the MP parameters throughout motion execution, addressing the lack of online motion adaptation in stochastic domains requiring feedback. We compared our approach against state-of-the-art deep RL and RL with MPs methods. The results demonstrated improved performance in sophisticated, sparse reward settings and in domains requiring replanning.
Reinforcement Learning from Multiple Sensors via Joint Representations
Feb 10, 2023In many scenarios, observations from more than one sensor modality are available for reinforcement learning (RL). For example, many agents can perceive their internal state via proprioceptive sensors but must infer the environment's state from high-dimensional observations such as images. For image-based RL, a variety of self-supervised representation learning approaches exist to improve performance and sample complexity. These approaches learn the image representation in isolation. However, including proprioception can help representation learning algorithms to focus on relevant aspects and guide them toward finding better representations. Hence, in this work, we propose using Recurrent State Space Models to fuse all available sensory information into a single consistent representation. We combine reconstruction-based and contrastive approaches for training, which allows using the most appropriate method for each sensor modality. For example, we can use reconstruction for proprioception and a contrastive loss for images. We demonstrate the benefits of utilizing proprioception in learning representations for RL on a large set of experiments. Furthermore, we show that our joint representations significantly improve performance compared to a post hoc combination of image representations and proprioception.
Deep Black-Box Reinforcement Learning with Movement Primitives
Oct 18, 2022
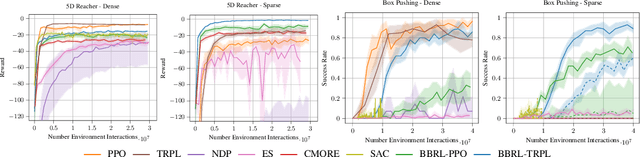
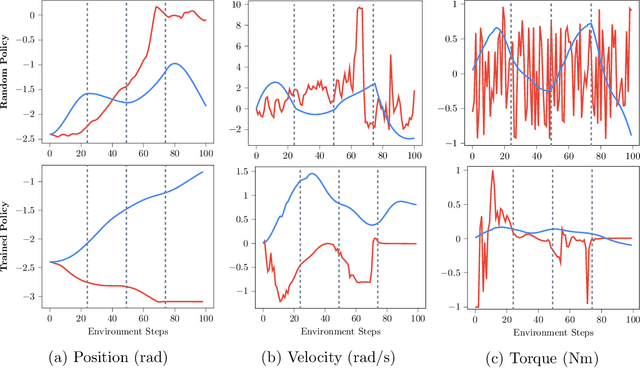
\Episode-based reinforcement learning (ERL) algorithms treat reinforcement learning (RL) as a black-box optimization problem where we learn to select a parameter vector of a controller, often represented as a movement primitive, for a given task descriptor called a context. ERL offers several distinct benefits in comparison to step-based RL. It generates smooth control trajectories, can handle non-Markovian reward definitions, and the resulting exploration in parameter space is well suited for solving sparse reward settings. Yet, the high dimensionality of the movement primitive parameters has so far hampered the effective use of deep RL methods. In this paper, we present a new algorithm for deep ERL. It is based on differentiable trust region layers, a successful on-policy deep RL algorithm. These layers allow us to specify trust regions for the policy update that are solved exactly for each state using convex optimization, which enables policies learning with the high precision required for the ERL. We compare our ERL algorithm to state-of-the-art step-based algorithms in many complex simulated robotic control tasks. In doing so, we investigate different reward formulations - dense, sparse, and non-Markovian. While step-based algorithms perform well only on dense rewards, ERL performs favorably on sparse and non-Markovian rewards. Moreover, our results show that the sparse and the non-Markovian rewards are also often better suited to define the desired behavior, allowing us to obtain considerably higher quality policies compared to step-based RL.
ProDMPs: A Unified Perspective on Dynamic and Probabilistic Movement Primitives
Oct 04, 2022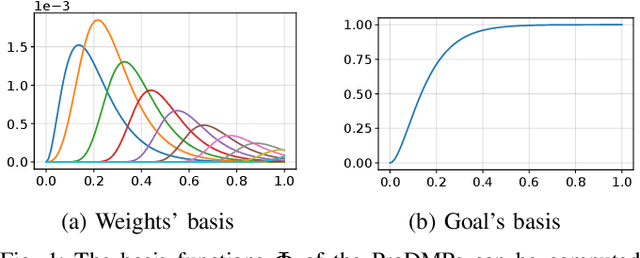
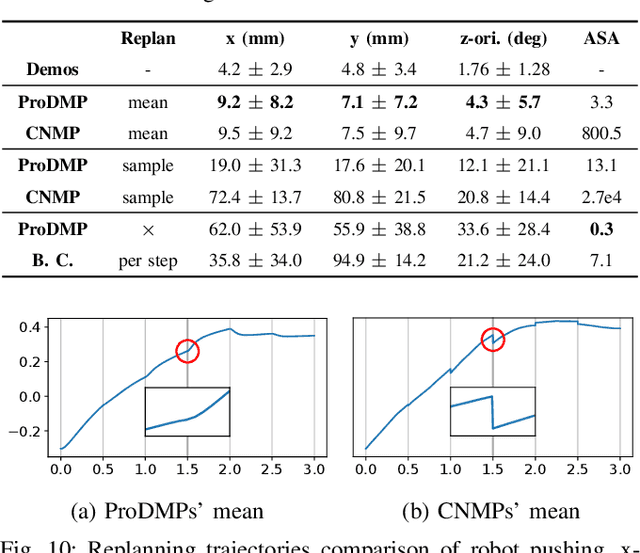
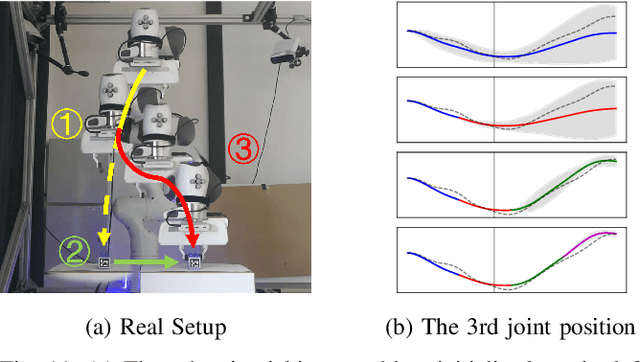
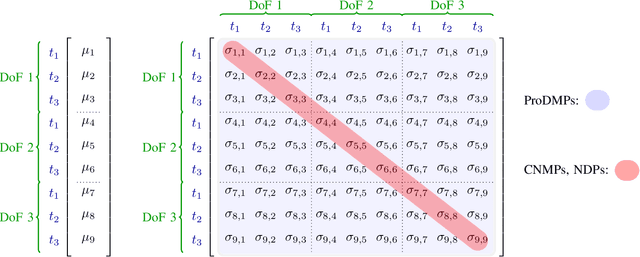
Movement Primitives (MPs) are a well-known concept to represent and generate modular trajectories. MPs can be broadly categorized into two types: (a) dynamics-based approaches that generate smooth trajectories from any initial state, e. g., Dynamic Movement Primitives (DMPs), and (b) probabilistic approaches that capture higher-order statistics of the motion, e. g., Probabilistic Movement Primitives (ProMPs). To date, however, there is no method that unifies both, i. e. that can generate smooth trajectories from an arbitrary initial state while capturing higher-order statistics. In this paper, we introduce a unified perspective of both approaches by solving the ODE underlying the DMPs. We convert expensive online numerical integration of DMPs into basis functions that can be computed offline. These basis functions can be used to represent trajectories or trajectory distributions similar to ProMPs while maintaining all the properties of dynamical systems. Since we inherit the properties of both methodologies, we call our proposed model Probabilistic Dynamic Movement Primitives (ProDMPs). Additionally, we embed ProDMPs in deep neural network architecture and propose a new cost function for efficient end-to-end learning of higher-order trajectory statistics. To this end, we leverage Bayesian Aggregation for non-linear iterative conditioning on sensory inputs. Our proposed model achieves smooth trajectory generation, goal-attractor convergence, correlation analysis, non-linear conditioning, and online re-planing in one framework.
Differentiable Trust Region Layers for Deep Reinforcement Learning
Jan 22, 2021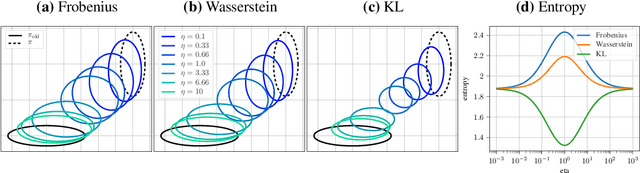
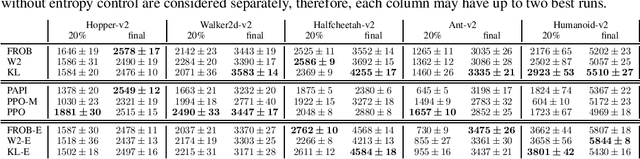
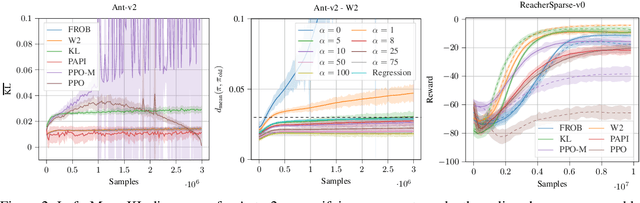
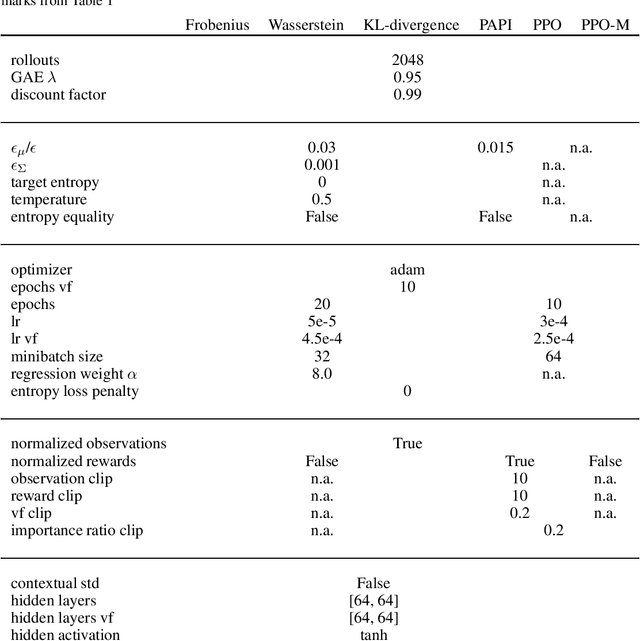
Trust region methods are a popular tool in reinforcement learning as they yield robust policy updates in continuous and discrete action spaces. However, enforcing such trust regions in deep reinforcement learning is difficult. Hence, many approaches, such as Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO), are based on approximations. Due to those approximations, they violate the constraints or fail to find the optimal solution within the trust region. Moreover, they are difficult to implement, lack sufficient exploration, and have been shown to depend on seemingly unrelated implementation choices. In this work, we propose differentiable neural network layers to enforce trust regions for deep Gaussian policies via closed-form projections. Unlike existing methods, those layers formalize trust regions for each state individually and can complement existing reinforcement learning algorithms. We derive trust region projections based on the Kullback-Leibler divergence, the Wasserstein L2 distance, and the Frobenius norm for Gaussian distributions. We empirically demonstrate that those projection layers achieve similar or better results than existing methods while being almost agnostic to specific implementation choices.