 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-label Correction and Learning For Semi-Supervised Object Detection
Mar 06, 2023



Pseudo-Labeling has emerged as a simple yet effective technique for semi-supervised object detection (SSOD). However, the inevitable noise problem in pseudo-labels significantly degrades the performance of SSOD methods. Recent advances effectively alleviate the classification noise in SSOD, while the localization noise which is a non-negligible part of SSOD is not well-addressed. In this paper, we analyse the localization noise from the generation and learning phases, and propose two strategies, namely pseudo-label correction and noise-unaware learning. For pseudo-label correction, we introduce a multi-round refining method and a multi-vote weighting method. The former iteratively refines the pseudo boxes to improve the stability of predictions, while the latter smoothly self-corrects pseudo boxes by weighing the scores of surrounding jittered boxes. For noise-unaware learning, we introduce a loss weight function that is negatively correlated with the Intersection over Union (IoU) in the regression task, which pulls the predicted boxes closer to the object and improves localization accuracy. Our proposed method, Pseudo-label Correction and Learning (PCL), is extensively evaluated on the MS COCO and PASCAL VOC benchmarks. On MS COCO, PCL outperforms the supervised baseline by 12.16, 12.11, and 9.57 mAP and the recent SOTA (SoftTeacher) by 3.90, 2.54, and 2.43 mAP under 1\%, 5\%, and 10\% labeling ratios, respectively. On PASCAL VOC, PCL improves the supervised baseline by 5.64 mAP and the recent SOTA (Unbiased Teacherv2) by 1.04 mAP on AP$^{50}$.
Multi-Scale Cost Volumes Cascade Network for Stereo Matching
Feb 03, 2021


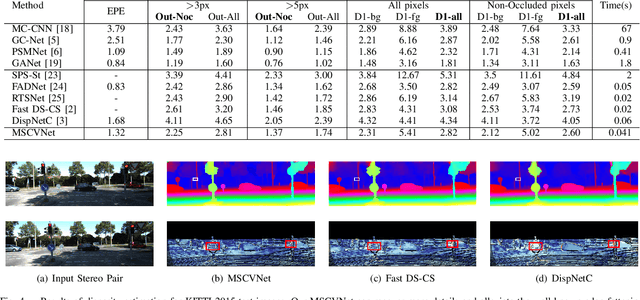
Stereo matching is essential for robot navigation. However, the accuracy of current widely used traditional methods is low, while methods based on CNN need expensive computational cost and running time. This is because different cost volumes play a crucial role in balancing speed and accuracy. Thus we propose MSCVNet, which combines traditional methods and CNN to improve the quality of cost volume. Concretely, our network first generates multiple 3D cost volumes with different resolutions and then uses 2D convolutions to construct a novel cascade hourglass network for cost aggregation. Meanwhile, we design an algorithm to distinguish and calculate the loss for discontinuous areas of disparity result. According to the KITTI official website, our network is much faster than most top-performing methods(24*than CSPN, 44*than GANet, etc.). Meanwhile, compared to traditional methods(SPS-St, SGM) and other real-time stereo matching networks(Fast DS-CS, DispNetC, and RTSNet, etc.), our network achieves a big improvement in accuracy, demonstrating the effectiveness of our proposed method.
Parallax Attention for Unsupervised Stereo Correspondence Learning
Sep 16, 2020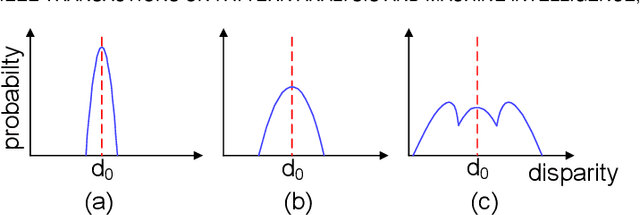
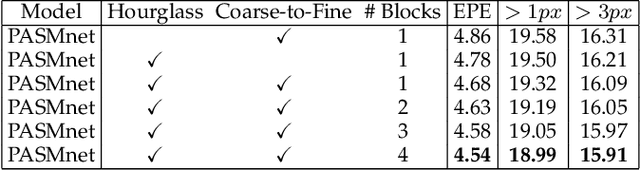
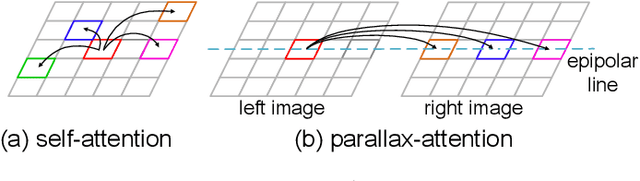

Stereo image pairs encode 3D scene cues into stereo correspondences between the left and right images. To exploit 3D cues within stereo images, recent CNN based methods commonly use cost volume techniques to capture stereo correspondence over large disparities. However, since disparities can vary significantly for stereo cameras with different baselines, focal lengths and resolutions, the fixed maximum disparity used in cost volume techniques hinders them to handle different stereo image pairs with large disparity variations. In this paper, we propose a generic parallax-attention mechanism (PAM) to capture stereo correspondence regardless of disparity variations. Our PAM integrates epipolar constraints with attention mechanism to calculate feature similarities along the epipolar line to capture stereo correspondence. Based on our PAM, we propose a parallax-attention stereo matching network (PASMnet) and a parallax-attention stereo image super-resolution network (PASSRnet) for stereo matching and stereo image super-resolution tasks. Moreover, we introduce a new and large-scale dataset named Flickr1024 for stereo image super-resolution. Experimental results show that our PAM is generic and can effectively learn stereo correspondence under large disparity variations in an unsupervised manner. Comparative results show that our PASMnet and PASSRnet achieve the state-of-the-art performance.
Learning Parallax Attention for Stereo Image Super-Resolution
Mar 19, 2019

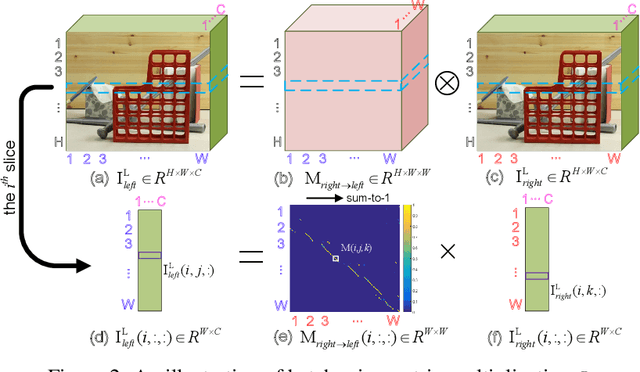
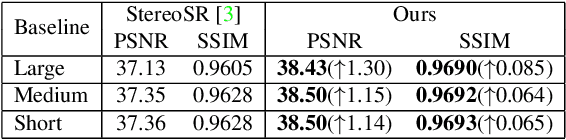
Stereo image pairs can be used to improve the performance of super-resolution (SR) since additional information is provided from a second viewpoint. However, it is challenging to incorporate this information for SR since disparities between stereo images vary significantly. In this paper, we propose a parallax-attention stereo superresolution network (PASSRnet) to integrate the information from a stereo image pair for SR. Specifically, we introduce a parallax-attention mechanism with a global receptive field along the epipolar line to handle different stereo images with large disparity variations. We also propose a new and the largest dataset for stereo image SR (namely, Flickr1024). Extensive experiments demonstrate that the parallax-attention mechanism can capture correspondence between stereo images to improve SR performance with a small computational and memory cost. Comparative results show that our PASSRnet achieves the state-of-the-art performance on the Middlebury, KITTI 2012 and KITTI 2015 datasets.
Learning for Disparity Estimation through Feature Constancy
Mar 28, 2018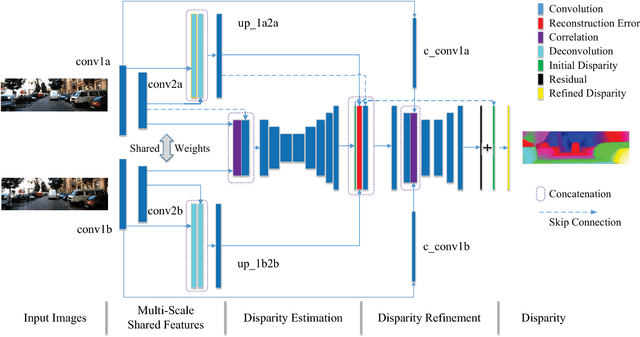
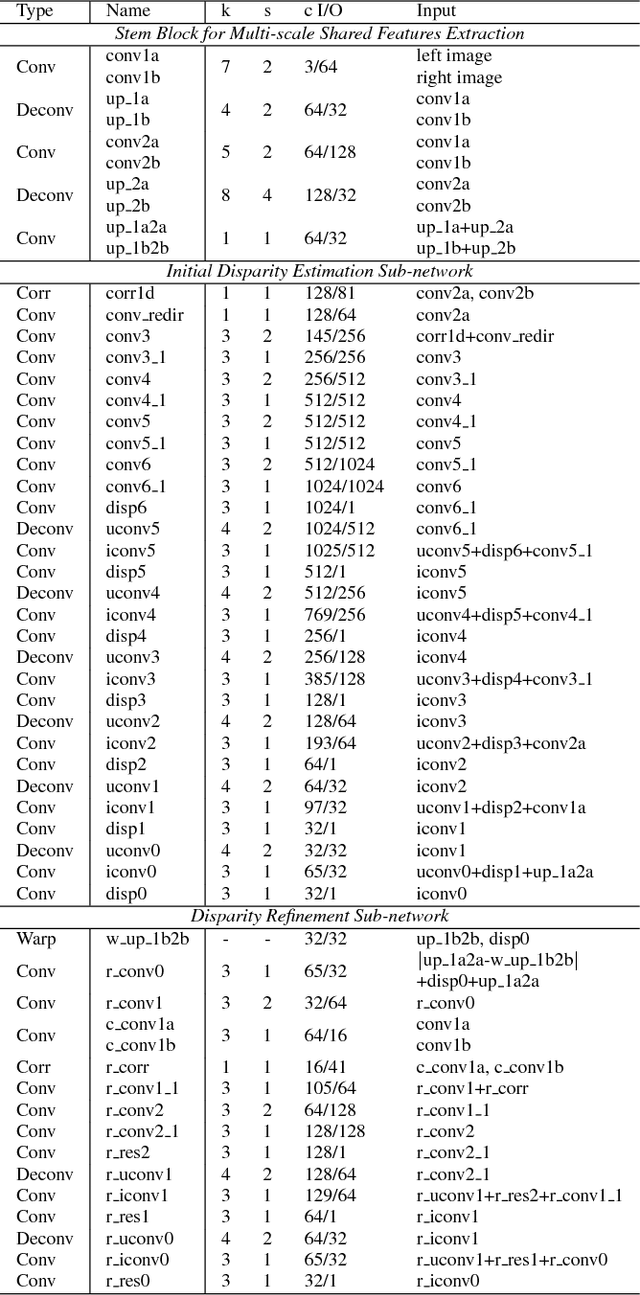

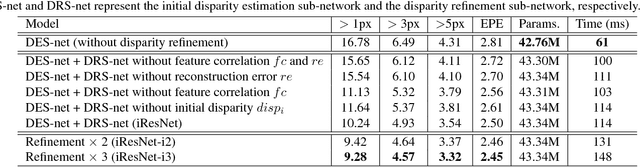
Stereo matching algorithms usually consist of four steps, including matching cost calculation, matching cost aggregation, disparity calculation, and disparity refinement. Existing CNN-based methods only adopt CNN to solve parts of the four steps, or use different networks to deal with different steps, making them difficult to obtain the overall optimal solution. In this paper, we propose a network architecture to incorporate all steps of stereo matching. The network consists of three parts. The first part calculates the multi-scale shared features. The second part performs matching cost calculation, matching cost aggregation and disparity calculation to estimate the initial disparity using shared features. The initial disparity and the shared features are used to calculate the feature constancy that measures correctness of the correspondence between two input images. The initial disparity and the feature constancy are then fed to a sub-network to refine the initial disparity. The proposed method has been evaluated on the Scene Flow and KITTI datasets. It achieves the state-of-the-art performance on the KITTI 2012 and KITTI 2015 benchmarks while maintaining a very fast running time.