 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute Value Weighting in K-Modes Clustering
Jan 03, 2007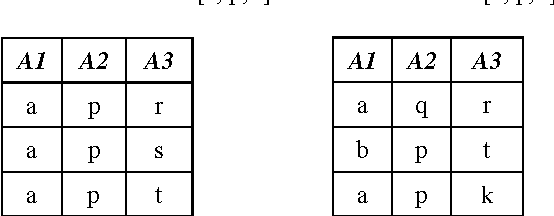
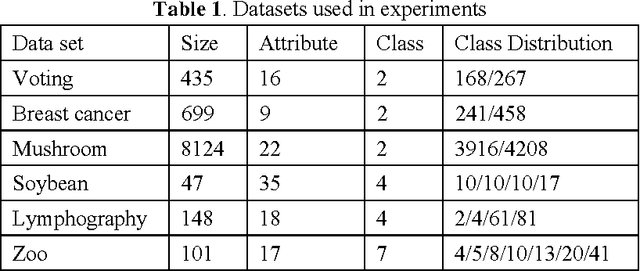
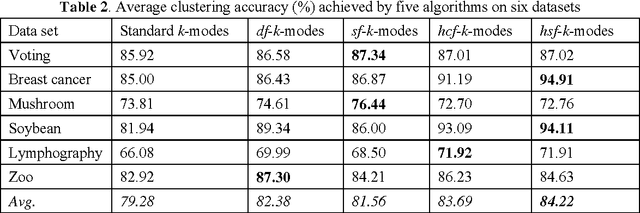
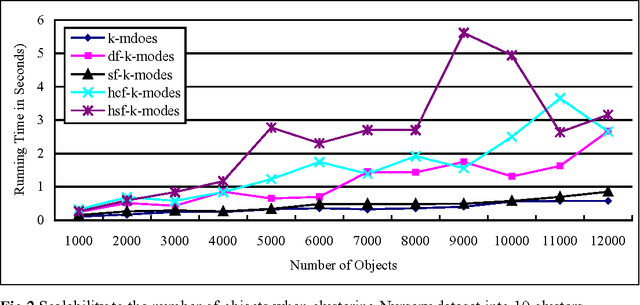
In this paper, the traditional k-modes clustering algorithm is extended by weighting attribute value matches in dissimilarity computation. The use of attribute value weighting technique makes it possible to generate clusters with stronger intra-similarities, and therefore achieve better clustering performance. Experimental results on real life datasets show that these value weighting based k-modes algorithms are superior to the standard k-modes algorithm with respect to clustering accuracy.
K-ANMI: A Mutual Information Based Clustering Algorithm for Categorical Data
Nov 03, 2005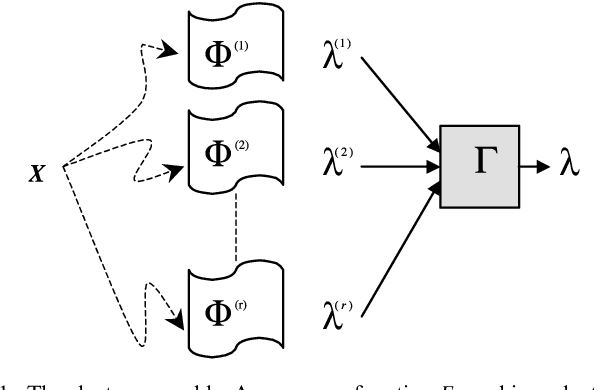
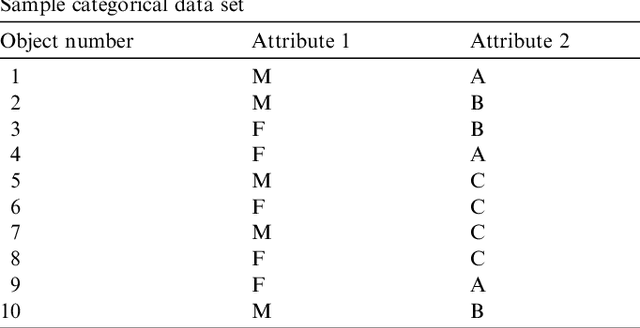
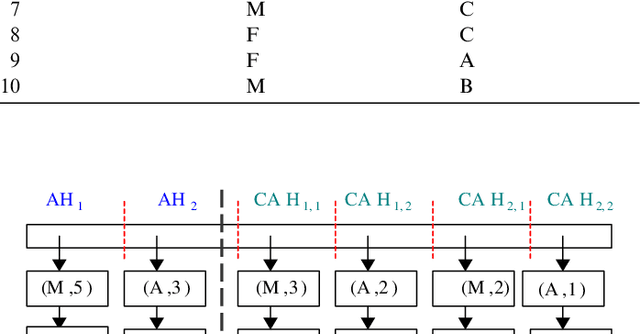
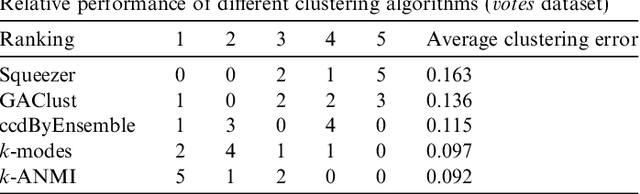
Clustering categorical data is an integral part of data mining and has attracted much attention recently. In this paper, we present k-ANMI, a new efficient algorithm for clustering categorical data. The k-ANMI algorithm works in a way that is similar to the popular k-means algorithm, and the goodness of clustering in each step is evaluated using a mutual information based criterion (namely, Average Normalized Mutual Information-ANMI) borrowed from cluster ensemble. Experimental results on real datasets show that k-ANMI algorithm is competitive with those state-of-art categorical data clustering algorithms with respect to clustering accuracy.
K-Histograms: An Efficient Clustering Algorithm for Categorical Dataset
Sep 13, 2005Clustering categorical data is an integral part of data mining and has attracted much attention recently. In this paper, we present k-histogram, a new efficient algorithm for clustering categorical data. The k-histogram algorithm extends the k-means algorithm to categorical domain by replacing the means of clusters with histograms, and dynamically updates histograms in the clustering process. Experimental results on real datasets show that k-histogram algorithm can produce better clustering results than k-modes algorithm, the one related with our work most closely.
Clustering Mixed Numeric and Categorical Data: A Cluster Ensemble Approach
Sep 05, 2005Clustering is a widely used technique in data mining applications for discovering patterns in underlying data. Most traditional clustering algorithms are limited to handling datasets that contain either numeric or categorical attributes. However, datasets with mixed types of attributes are common in real life data mining applications. In this paper, we propose a novel divide-and-conquer technique to solve this problem. First, the original mixed dataset is divided into two sub-datasets: the pure categorical dataset and the pure numeric dataset. Next, existing well established clustering algorithms designed for different types of datasets are employed to produce corresponding clusters. Last, the clustering results on the categorical and numeric dataset are combined as a categorical dataset, on which the categorical data clustering algorithm is used to get the final clusters. Our contribution in this paper is to provide an algorithm framework for the mixed attributes clustering problem, in which existing clustering algorithms can be easily integrated, the capabilities of different kinds of clustering algorithms and characteristics of different types of datasets could be fully exploited. Comparisons with other clustering algorithms on real life datasets illustrate the superiority of our approach.
A Fast Greedy Algorithm for Outlier Mining
Jul 27, 2005

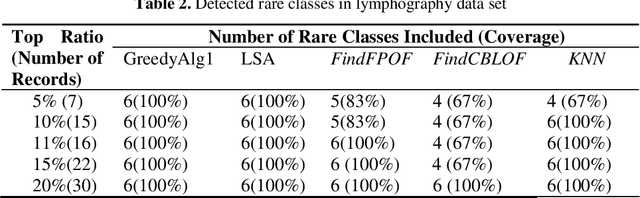
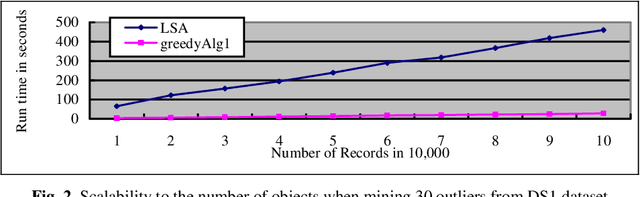
The task of outlier detection is to find small groups of data objects that are exceptional when compared with rest large amount of data. In [38], the problem of outlier detection in categorical data is defined as an optimization problem and a local-search heuristic based algorithm (LSA) is presented. However, as is the case with most iterative type algorithms, the LSA algorithm is still very time-consuming on very large datasets. In this paper, we present a very fast greedy algorithm for mining outliers under the same optimization model. Experimental results on real datasets and large synthetic datasets show that: (1) Our algorithm has comparable performance with respect to those state-of-art outlier detection algorithms on identifying true outliers and (2) Our algorithm can be an order of magnitude faster than LSA algorithm.
A Unified Subspace Outlier Ensemble Framework for Outlier Detection in High Dimensional Spaces
May 24, 2005The task of outlier detection is to find small groups of data objects that are exceptional when compared with rest large amount of data. Detection of such outliers is important for many applications such as fraud detection and customer migration. Most such applications are high dimensional domains in which the data may contain hundreds of dimensions. However, the outlier detection problem itself is not well defined and none of the existing definitions are widely accepted, especially in high dimensional space. In this paper, our first contribution is to propose a unified framework for outlier detection in high dimensional spaces from an ensemble-learning viewpoint. In our new framework, the outlying-ness of each data object is measured by fusing outlier factors in different subspaces using a combination function. Accordingly, we show that all existing researches on outlier detection can be regarded as special cases in the unified framework with respect to the set of subspaces considered and the type of combination function used. In addition, to demonstrate the usefulness of the ensemble-learning based outlier detection framework, we developed a very simple and fast algorithm, namely SOE1 (Subspace Outlier Ensemble using 1-dimensional Subspaces) in which only subspaces with one dimension is used for mining outliers from large categorical datasets. The SOE1 algorithm needs only two scans over the dataset and hence is very appealing in real data mining applications. Experimental results on real datasets and large synthetic datasets show that: (1) SOE1 has comparable performance with respect to those state-of-art outlier detection algorithms on identifying true outliers and (2) SOE1 can be an order of magnitude faster than one of the fastest outlier detection algorithms known so far.
An Optimization Model for Outlier Detection in Categorical Data
Mar 29, 2005The task of outlier detection is to find small groups of data objects that are exceptional when compared with rest large amount of data. Detection of such outliers is important for many applications such as fraud detection and customer migration. Most existing methods are designed for numeric data. They will encounter problems with real-life applications that contain categorical data. In this paper, we formally define the problem of outlier detection in categorical data as an optimization problem from a global viewpoint. Moreover, we present a local-search heuristic based algorithm for efficiently finding feasible solutions. Experimental results on real datasets and large synthetic datasets demonstrate the superiority of our model and algorithm.
Data Mining for Actionable Knowledge: A Survey
Jan 27, 2005The data mining process consists of a series of steps ranging from data cleaning, data selection and transformation, to pattern evaluation and visualization. One of the central problems in data mining is to make the mined patterns or knowledge actionable. Here, the term actionable refers to the mined patterns suggest concrete and profitable actions to the decision-maker. That is, the user can do something to bring direct benefits (increase in profits, reduction in cost, improvement in efficiency, etc.) to the organization's advantage. However, there has been written no comprehensive survey available on this topic. The goal of this paper is to fill the void. In this paper, we first present two frameworks for mining actionable knowledge that are inexplicitly adopted by existing research methods. Then we try to situate some of the research on this topic from two different viewpoints: 1) data mining tasks and 2) adopted framework. Finally, we specify issues that are either not addressed or insufficiently studied yet and conclude the paper.
Clustering Categorical Data Streams
Dec 13, 2004

The data stream model has been defined for new classes of applications involving massive data being generated at a fast pace. Web click stream analysis and detection of network intrusions are two examples. Cluster analysis on data streams becomes more difficult, because the data objects in a data stream must be accessed in order and can be read only once or few times with limited resources. Recently, a few clustering algorithms have been developed for analyzing numeric data streams. However, to our knowledge to date, no algorithm exists for clustering categorical data streams. In this paper, we propose an efficient clustering algorithm for analyzing categorical data streams. It has been proved that the proposed algorithm uses small memory footprints. We provide empirical analysis on the performance of the algorithm in clustering both synthetic and real data streams
A Link Clustering Based Approach for Clustering Categorical Data
Dec 04, 2004Categorical data clustering (CDC) and link clustering (LC) have been considered as separate research and application areas. The main focus of this paper is to investigate the commonalities between these two problems and the uses of these commonalities for the creation of new clustering algorithms for categorical data based on cross-fertilization between the two disjoint research fields. More precisely, we formally transform the CDC problem into an LC problem, and apply LC approach for clustering categorical data. Experimental results on real datasets show that LC based clustering method is competitive with existing CDC algorithms with respect to clustering accuracy.
* 10 pages