Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-ANMI: A Mutual Information Based Clustering Algorithm for Categorical Data
Paper and Code
Nov 03, 2005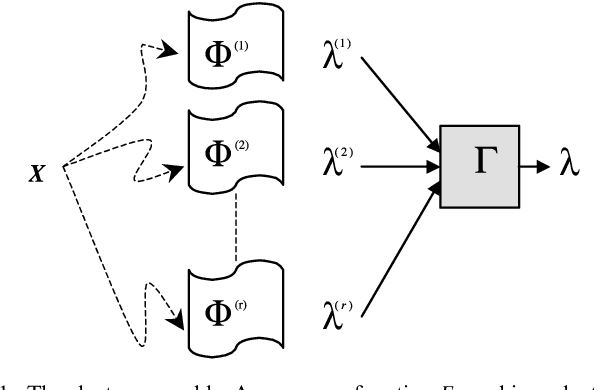
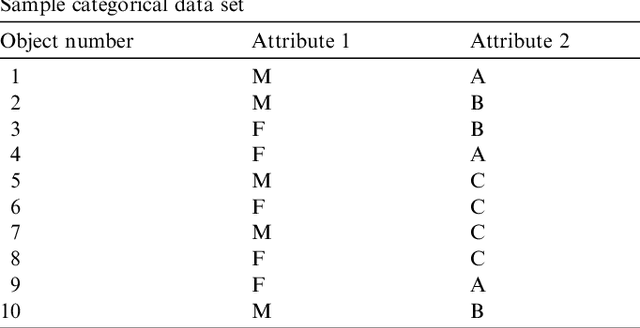
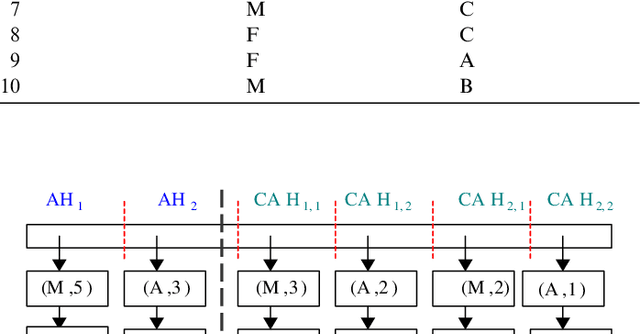
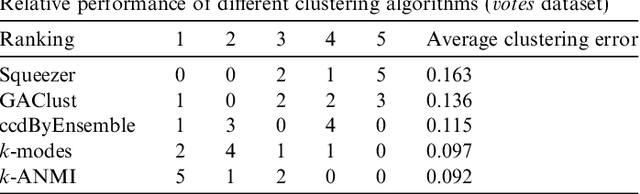
Clustering categorical data is an integral part of data mining and has attracted much attention recently. In this paper, we present k-ANMI, a new efficient algorithm for clustering categorical data. The k-ANMI algorithm works in a way that is similar to the popular k-means algorithm, and the goodness of clustering in each step is evaluated using a mutual information based criterion (namely, Average Normalized Mutual Information-ANMI) borrowed from cluster ensemble. Experimental results on real datasets show that k-ANMI algorithm is competitive with those state-of-art categorical data clustering algorithms with respect to clustering accuracy.
* 18 pages
View paper on