 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResumeAtlas: Revisiting Resume Classification with Large-Scale Datasets and Large Language Models
Paper and Code
Jun 26, 2024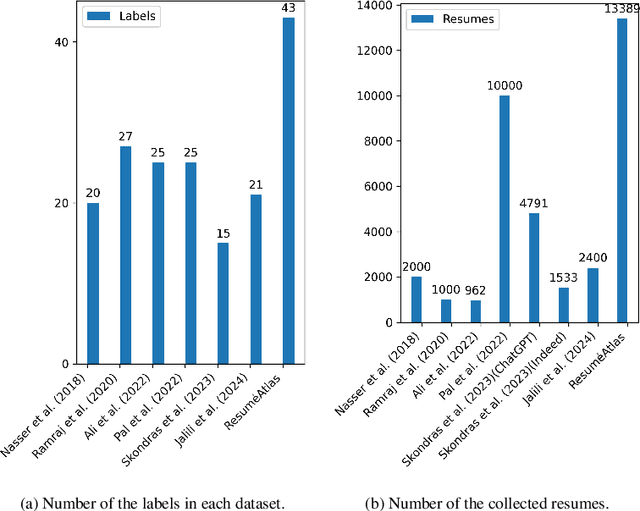

The increasing reliance on online recruitment platforms coupled with the adoption of AI technologies has highlighted the critical need for efficient resume classification methods. However, challenges such as small datasets, lack of standardized resume templates, and privacy concerns hinder the accuracy and effectiveness of existing classification models. In this work, we address these challenges by presenting a comprehensive approach to resume classification. We curated a large-scale dataset of 13,389 resumes from diverse sources and employed Large Language Models (LLMs) such as BERT and Gemma1.1 2B for classification. Our results demonstrate significant improvements over traditional machine learning approaches, with our best model achieving a top-1 accuracy of 92\% and a top-5 accuracy of 97.5\%. These findings underscore the importance of dataset quality and advanced model architectures in enhancing the accuracy and robustness of resume classification systems, thus advancing the field of online recruitment practices.