 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRo-JEPA: Learning Modular Arithmetic in Latent Space
May 31, 2026Can neural networks learn abstract algebraic rules, or do they merely memorize training patterns? We investigate this using MNIST digits as states and modular arithmetic operations as actions in a JEPA-style latent world model. Standard supervised baselines and JEPA models with additive operation embeddings fit seen operations but fail to extrapolate reliably to unseen ones. To bridge this gap, we introduce a block-rotation predictor that imposes the circular structure of modulo-10 arithmetic in latent space. This enables strong zero-shot generalization, with the best ResNet-based JEPA block-rotation model achieving 99.46\% zero-shot and 99.46\% rollout accuracy. Our results suggest that latent world models can learn symbolic transformation rules when architecture matches the structure of the problem. Our code can be \href{https://github.com/DL-World-Models/mnist-math}{accessed here}.
AI Art Neural Constellation: Revealing the Collective and Contrastive State of AI-Generated and Human Art
Feb 04, 2024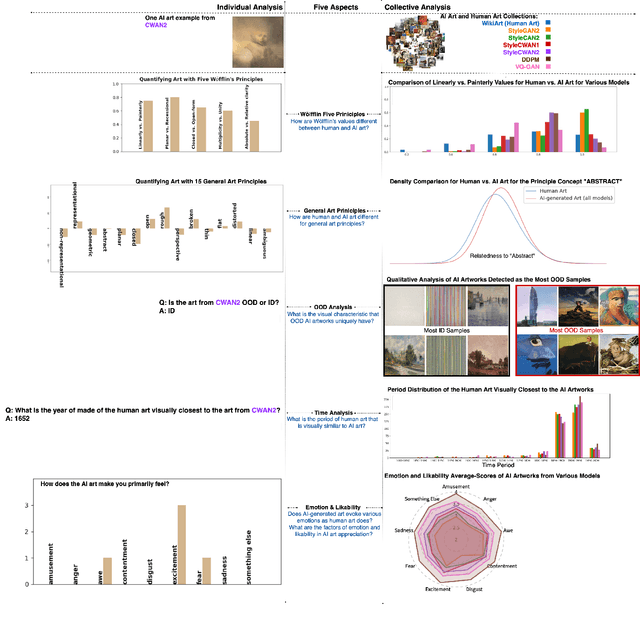
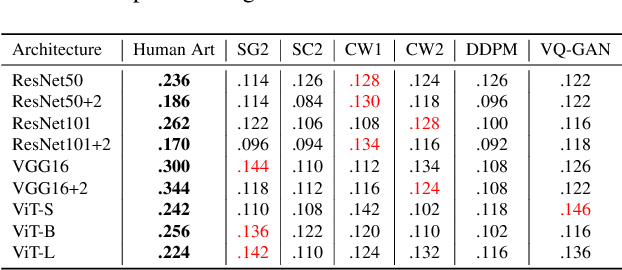
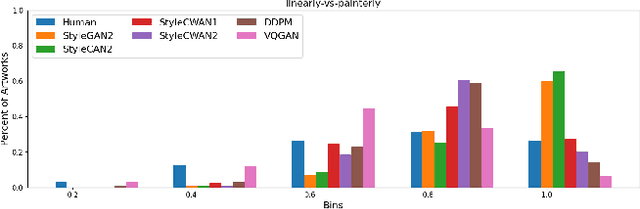
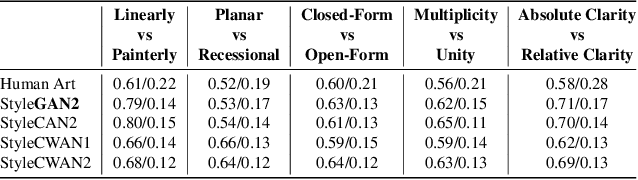
Discovering the creative potentials of a random signal to various artistic expressions in aesthetic and conceptual richness is a ground for the recent success of generative machine learning as a way of art creation. To understand the new artistic medium better, we conduct a comprehensive analysis to position AI-generated art within the context of human art heritage. Our comparative analysis is based on an extensive dataset, dubbed ``ArtConstellation,'' consisting of annotations about art principles, likability, and emotions for 6,000 WikiArt and 3,200 AI-generated artworks. After training various state-of-the-art generative models, art samples are produced and compared with WikiArt data on the last hidden layer of a deep-CNN trained for style classification. We actively examined the various art principles to interpret the neural representations and used them to drive the comparative knowledge about human and AI-generated art. A key finding in the semantic analysis is that AI-generated artworks are visually related to the principle concepts for modern period art made in 1800-2000. In addition, through Out-Of-Distribution (OOD) and In-Distribution (ID) detection in CLIP space, we find that AI-generated artworks are ID to human art when they depict landscapes and geometric abstract figures, while detected as OOD when the machine art consists of deformed and twisted figures. We observe that machine-generated art is uniquely characterized by incomplete and reduced figuration. Lastly, we conducted a human survey about emotional experience. Color composition and familiar subjects are the key factors of likability and emotions in art appreciation. We propose our whole methodologies and collected dataset as our analytical framework to contrast human and AI-generated art, which we refer to as ``ArtNeuralConstellation''. Code is available at: https://github.com/faixan-khan/ArtNeuralConstellation
Imaginative Walks: Generative Random Walk Deviation Loss for Improved Unseen Learning Representation
Apr 20, 2021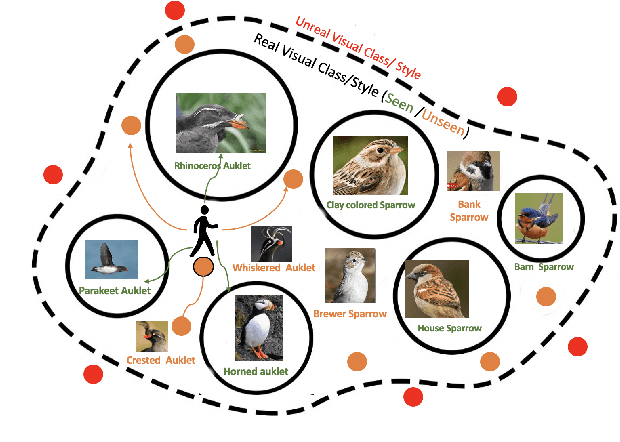


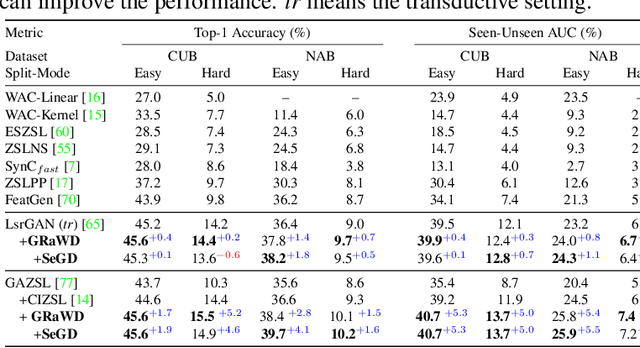
We propose a novel loss for generative models, dubbed as GRaWD (Generative Random Walk Deviation), to improve learning representations of unexplored visual spaces. Quality learning representation of unseen classes (or styles) is crucial to facilitate novel image generation and better generative understanding of unseen visual classes (a.k.a. Zero-Shot Learning, ZSL). By generating representations of unseen classes from their semantic descriptions, such as attributes or text, Generative ZSL aims at identifying unseen categories discriminatively from seen ones. We define GRaWD by constructing a dynamic graph, including the seen class/style centers and generated samples in the current mini-batch. Our loss starts a random walk probability from each center through visual generations produced from hallucinated unseen classes. As a deviation signal, we encourage the random walk to eventually land after t steps in a feature representation that is hard to classify to any of the seen classes. We show that our loss can improve unseen class representation quality on four text-based ZSL benchmarks on CUB and NABirds datasets and three attribute-based ZSL benchmarks on AWA2, SUN, and aPY datasets. We also study our loss's ability to produce meaningful novel visual art generations on WikiArt dataset. Our experiments and human studies show that our loss can improve StyleGAN1 and StyleGAN2 generation quality, creating novel art that is significantly more preferred. Code will be made available.