 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisible Structure Retrieval for Lightweight Image-Based Relocalisation
Nov 16, 2025Accurate camera pose estimation from an image observation in a previously mapped environment is commonly done through structure-based methods: by finding correspondences between 2D keypoints on the image and 3D structure points in the map. In order to make this correspondence search tractable in large scenes, existing pipelines either rely on search heuristics, or perform image retrieval to reduce the search space by comparing the current image to a database of past observations. However, these approaches result in elaborate pipelines or storage requirements that grow with the number of past observations. In this work, we propose a new paradigm for making structure-based relocalisation tractable. Instead of relying on image retrieval or search heuristics, we learn a direct mapping from image observations to the visible scene structure in a compact neural network. Given a query image, a forward pass through our novel visible structure retrieval network allows obtaining the subset of 3D structure points in the map that the image views, thus reducing the search space of 2D-3D correspondences. We show that our proposed method enables performing localisation with an accuracy comparable to the state of the art, while requiring lower computational and storage footprint.
Quantifying Epistemic Uncertainty in Absolute Pose Regression
Apr 09, 2025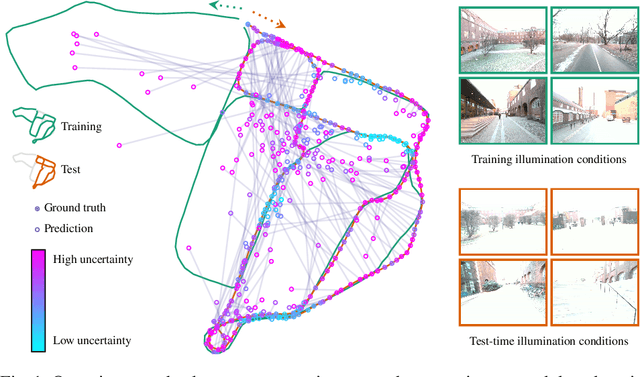
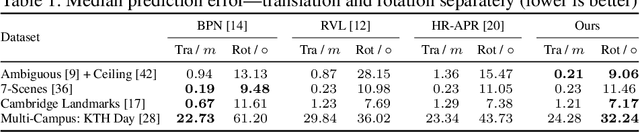

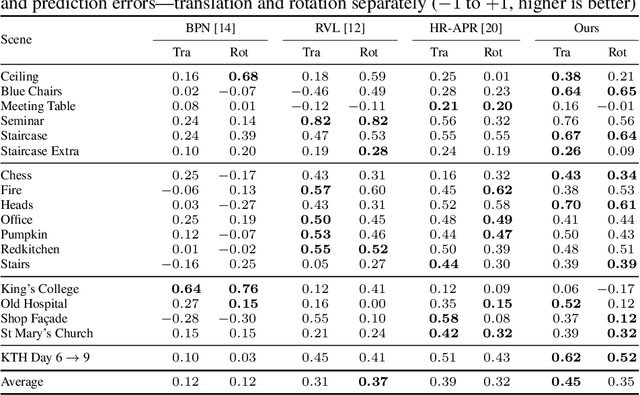
Visual relocalization is the task of estimating the camera pose given an image it views. Absolute pose regression offers a solution to this task by training a neural network, directly regressing the camera pose from image features. While an attractive solution in terms of memory and compute efficiency, absolute pose regression's predictions are inaccurate and unreliable outside the training domain. In this work, we propose a novel method for quantifying the epistemic uncertainty of an absolute pose regression model by estimating the likelihood of observations within a variational framework. Beyond providing a measure of confidence in predictions, our approach offers a unified model that also handles observation ambiguities, probabilistically localizing the camera in the presence of repetitive structures. Our method outperforms existing approaches in capturing the relation between uncertainty and prediction error.
Conditional Variational Autoencoders for Probabilistic Pose Regression
Oct 07, 2024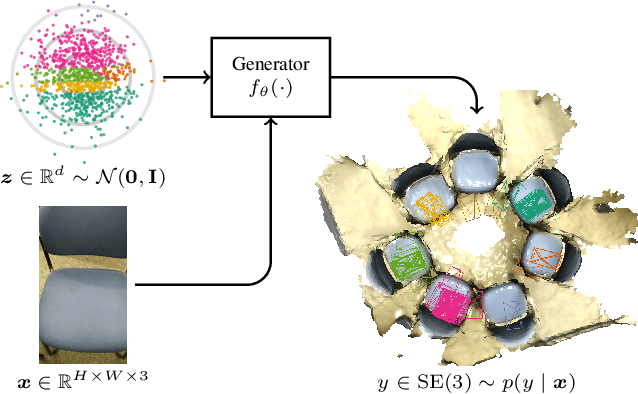
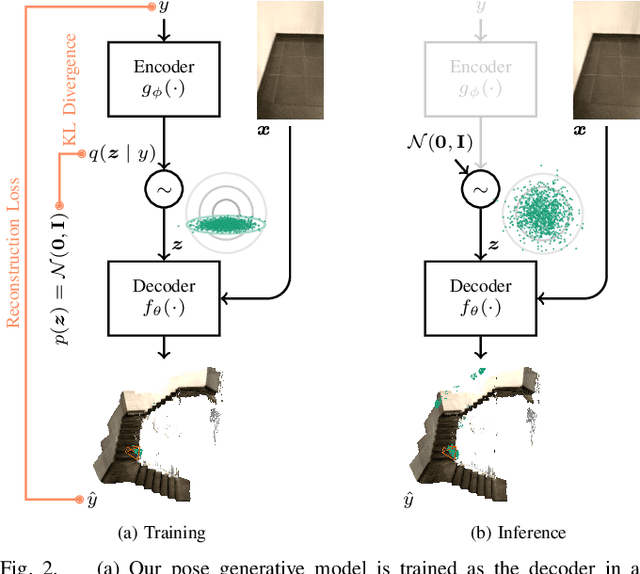
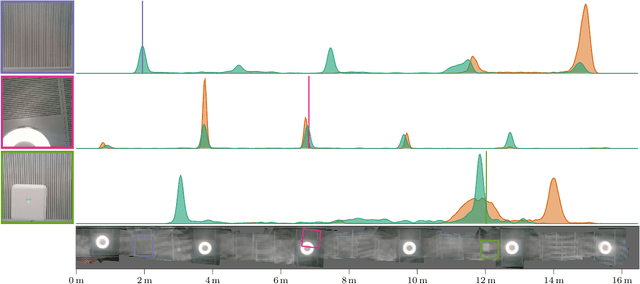
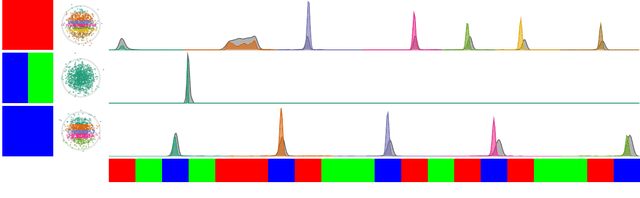
Robots rely on visual relocalization to estimate their pose from camera images when they lose track. One of the challenges in visual relocalization is repetitive structures in the operation environment of the robot. This calls for probabilistic methods that support multiple hypotheses for robot's pose. We propose such a probabilistic method to predict the posterior distribution of camera poses given an observed image. Our proposed training strategy results in a generative model of camera poses given an image, which can be used to draw samples from the pose posterior distribution. Our method is streamlined and well-founded in theory and outperforms existing methods on localization in presence of ambiguities.
A Probabilistic Framework for Visual Localization in Ambiguous Scenes
Jan 05, 2023



Visual localization allows autonomous robots to relocalize when losing track of their pose by matching their current observation with past ones. However, ambiguous scenes pose a challenge for such systems, as repetitive structures can be viewed from many distinct, equally likely camera poses, which means it is not sufficient to produce a single best pose hypothesis. In this work, we propose a probabilistic framework that for a given image predicts the arbitrarily shaped posterior distribution of its camera pose. We do this via a novel formulation of camera pose regression using variational inference, which allows sampling from the predicted distribution. Our method outperforms existing methods on localization in ambiguous scenes. Code and data will be released at https://github.com/efreidun/vapor.
Dense FixMatch: a simple semi-supervised learning method for pixel-wise prediction tasks
Oct 18, 2022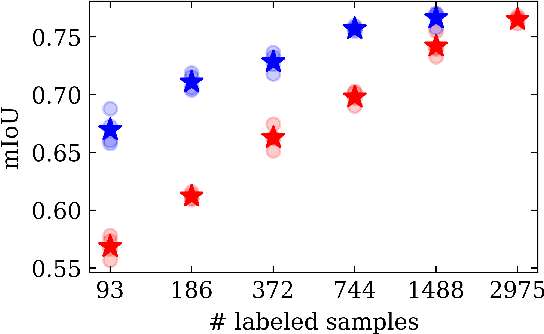

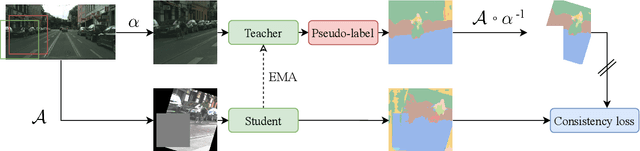

We propose Dense FixMatch, a simple method for online semi-supervised learning of dense and structured prediction tasks combining pseudo-labeling and consistency regularization via strong data augmentation. We enable the application of FixMatch in semi-supervised learning problems beyond image classification by adding a matching operation on the pseudo-labels. This allows us to still use the full strength of data augmentation pipelines, including geometric transformations. We evaluate it on semi-supervised semantic segmentation on Cityscapes and Pascal VOC with different percentages of labeled data and ablate design choices and hyper-parameters. Dense FixMatch significantly improves results compared to supervised learning using only labeled data, approaching its performance with 1/4 of the labeled samples.
An analysis of over-sampling labeled data in semi-supervised learning with FixMatch
Jan 03, 2022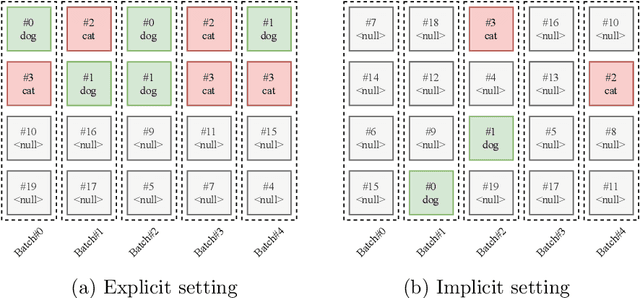
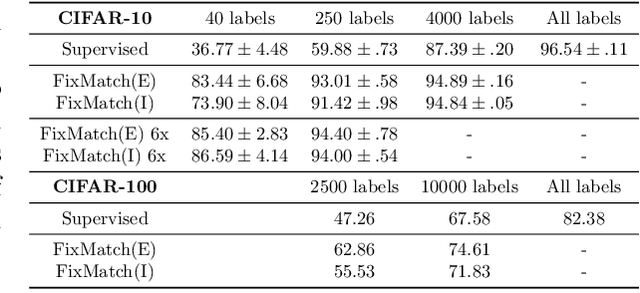
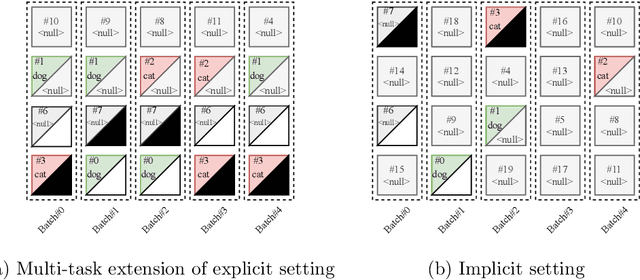
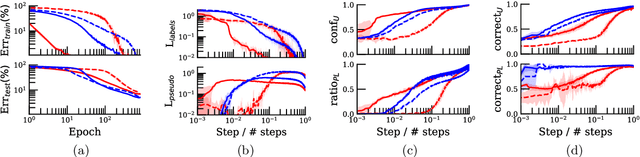
Most semi-supervised learning methods over-sample labeled data when constructing training mini-batches. This paper studies whether this common practice improves learning and how. We compare it to an alternative setting where each mini-batch is uniformly sampled from all the training data, labeled or not, which greatly reduces direct supervision from true labels in typical low-label regimes. However, this simpler setting can also be seen as more general and even necessary in multi-task problems where over-sampling labeled data would become intractable. Our experiments on semi-supervised CIFAR-10 image classification using FixMatch show a performance drop when using the uniform sampling approach which diminishes when the amount of labeled data or the training time increases. Further, we analyse the training dynamics to understand how over-sampling of labeled data compares to uniform sampling. Our main finding is that over-sampling is especially beneficial early in training but gets less important in the later stages when more pseudo-labels become correct. Nevertheless, we also find that keeping some true labels remains important to avoid the accumulation of confirmation errors from incorrect pseudo-labels.
Real-Time Semantic Stereo Matching
Oct 01, 2019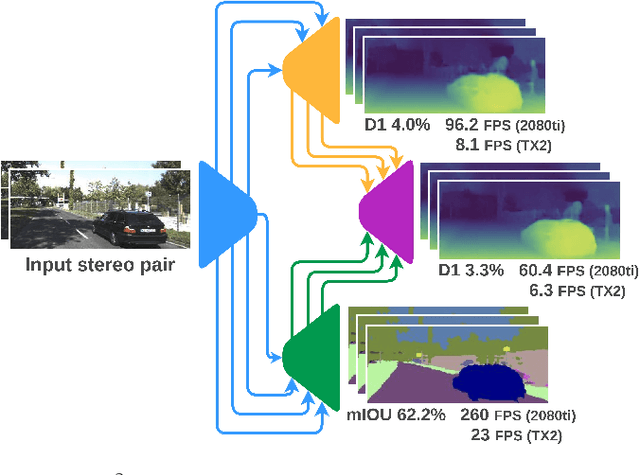
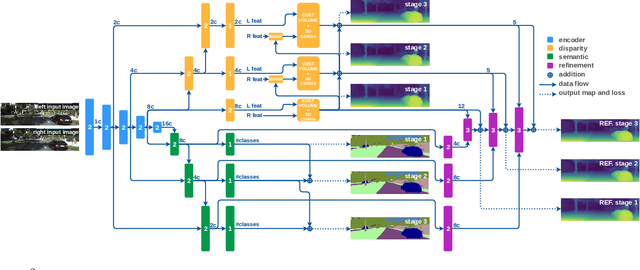

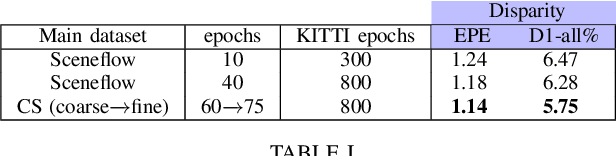
Scene understanding is paramount in robotics, self-navigation, augmented reality, and many other fields. To fully accomplish this task, an autonomous agent has to infer the 3D structure of the sensed scene (to know where it looks at) and its content (to know what it sees). To tackle the two tasks, deep neural networks trained to infer semantic segmentation and depth from stereo images are often the preferred choices. Specifically, Semantic Stereo Matching can be tackled by either standalone models trained for the two tasks independently or joint end-to-end architectures. Nonetheless, as proposed so far, both solutions are inefficient because requiring two forward passes in the former case or due to the complexity of a single network in the latter, although jointly tackling both tasks is usually beneficial in terms of accuracy. In this paper, we propose a single compact and lightweight architecture for real-time semantic stereo matching. Our framework relies on coarse-to-fine estimations in a multi-stage fashion, allowing: i) very fast inference even on embedded devices, with marginal drops in accuracy, compared to state-of-the-art networks, ii) trade accuracy for speed, according to the specific application requirements. Experimental results on high-end GPUs as well as on an embedded Jetson TX2 confirm the superiority of semantic stereo matching compared to standalone tasks and highlight the versatility of our framework on any hardware and for any application.
Enhancing self-supervised monocular depth estimation with traditional visual odometry
Aug 12, 2019
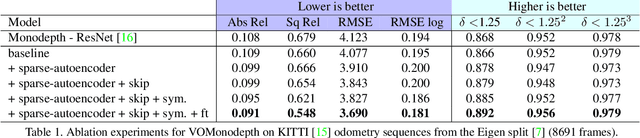
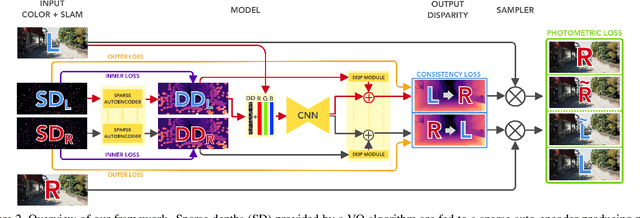
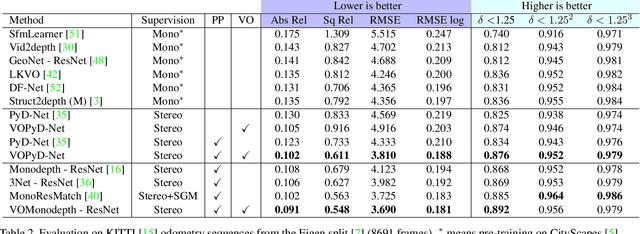
Estimating depth from a single image represents an attractive alternative to more traditional approaches leveraging multiple cameras. In this field, deep learning yielded outstanding results at the cost of needing large amounts of data labeled with precise depth measurements for training. An issue softened by self-supervised approaches leveraging monocular sequences or stereo pairs in place of expensive ground truth depth annotations. This paper enables to further improve monocular depth estimation by integrating into existing self-supervised networks a geometrical prior. Specifically, we propose a sparsity-invariant autoencoder able to process the output of conventional visual odometry algorithms working in synergy with depth-from-mono networks. Experimental results on the KITTI dataset show that by exploiting the geometrical prior, our proposal: i) outperforms existing approaches in the literature and ii) couples well with both compact and complex depth-from-mono architectures, allowing for its deployment on high-end GPUs as well as on embedded devices (e.g., NVIDIA Jetson TX2).
GANtruth - an unpaired image-to-image translation method for driving scenarios
Nov 26, 2018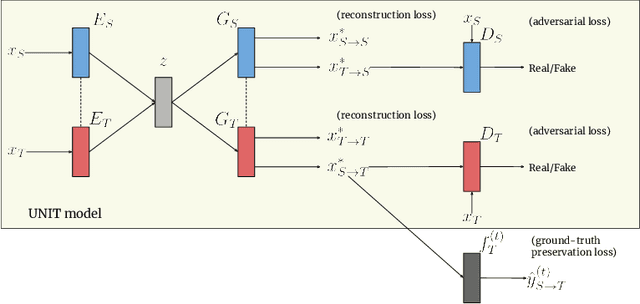
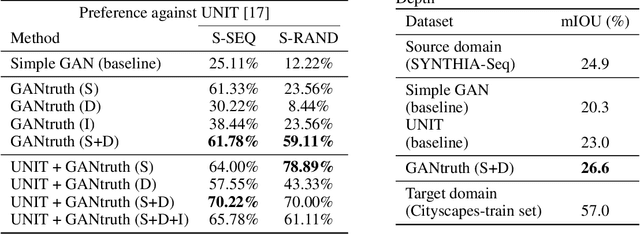


Synthetic image translation has significant potentials in autonomous transportation systems. That is due to the expense of data collection and annotation as well as the unmanageable diversity of real-words situations. The main issue with unpaired image-to-image translation is the ill-posed nature of the problem. In this work, we propose a novel method for constraining the output space of unpaired image-to-image translation. We make the assumption that the environment of the source domain is known (e.g. synthetically generated), and we propose to explicitly enforce preservation of the ground-truth labels on the translated images. We experiment on preserving ground-truth information such as semantic segmentation, disparity, and instance segmentation. We show significant evidence that our method achieves improved performance over the state-of-the-art model of UNIT for translating images from SYNTHIA to Cityscapes. The generated images are perceived as more realistic in human surveys and outperforms UNIT when used in a domain adaptation scenario for semantic segmentation.
Feature Descriptors for Tracking by Detection: a Benchmark
Jul 21, 2016



In this paper, we provide an extensive evaluation of the performance of local descriptors for tracking applications. Many different descriptors have been proposed in the literature for a wide range of application in computer vision such as object recognition and 3D reconstruction. More recently, due to fast key-point detectors, local image features can be used in online tracking frameworks. However, while much effort has been spent on evaluating their performance in terms of distinctiveness and robustness to image transformations, very little has been done in the contest of tracking. Our evaluation is performed in terms of distinctiveness, tracking precision and tracking speed. Our results show that binary descriptors like ORB or BRISK have comparable results to SIFT or AKAZE due to a higher number of key-points.