 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Semantic Stereo Matching
Oct 01, 2019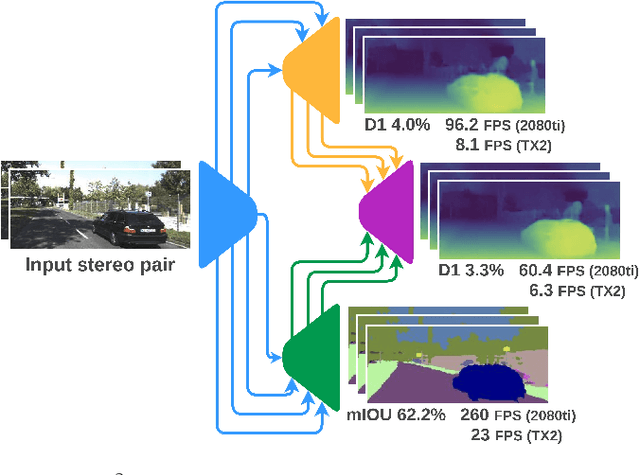
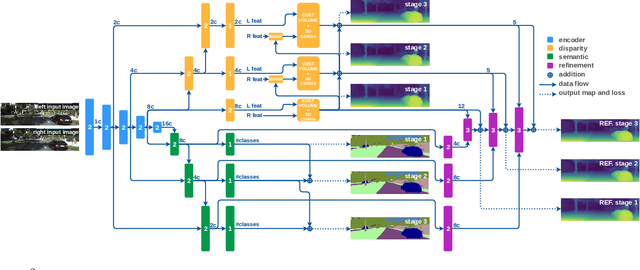

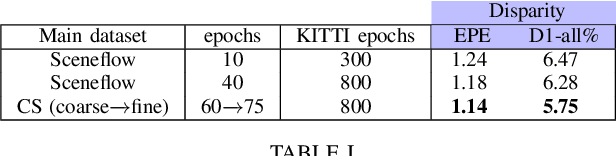
Scene understanding is paramount in robotics, self-navigation, augmented reality, and many other fields. To fully accomplish this task, an autonomous agent has to infer the 3D structure of the sensed scene (to know where it looks at) and its content (to know what it sees). To tackle the two tasks, deep neural networks trained to infer semantic segmentation and depth from stereo images are often the preferred choices. Specifically, Semantic Stereo Matching can be tackled by either standalone models trained for the two tasks independently or joint end-to-end architectures. Nonetheless, as proposed so far, both solutions are inefficient because requiring two forward passes in the former case or due to the complexity of a single network in the latter, although jointly tackling both tasks is usually beneficial in terms of accuracy. In this paper, we propose a single compact and lightweight architecture for real-time semantic stereo matching. Our framework relies on coarse-to-fine estimations in a multi-stage fashion, allowing: i) very fast inference even on embedded devices, with marginal drops in accuracy, compared to state-of-the-art networks, ii) trade accuracy for speed, according to the specific application requirements. Experimental results on high-end GPUs as well as on an embedded Jetson TX2 confirm the superiority of semantic stereo matching compared to standalone tasks and highlight the versatility of our framework on any hardware and for any application.
Enhancing self-supervised monocular depth estimation with traditional visual odometry
Aug 12, 2019
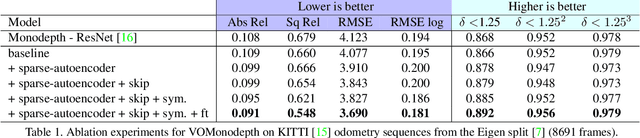
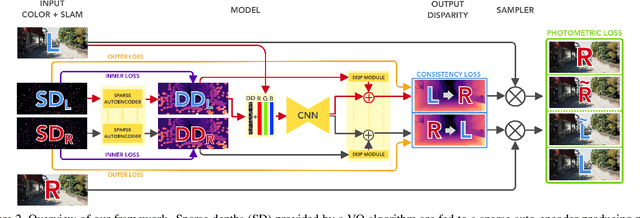
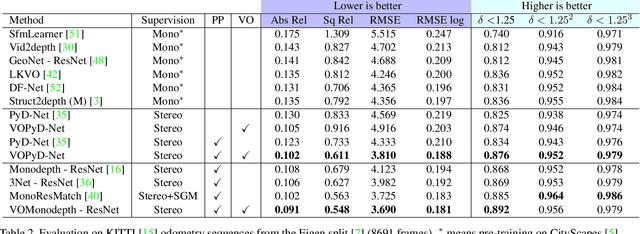
Estimating depth from a single image represents an attractive alternative to more traditional approaches leveraging multiple cameras. In this field, deep learning yielded outstanding results at the cost of needing large amounts of data labeled with precise depth measurements for training. An issue softened by self-supervised approaches leveraging monocular sequences or stereo pairs in place of expensive ground truth depth annotations. This paper enables to further improve monocular depth estimation by integrating into existing self-supervised networks a geometrical prior. Specifically, we propose a sparsity-invariant autoencoder able to process the output of conventional visual odometry algorithms working in synergy with depth-from-mono networks. Experimental results on the KITTI dataset show that by exploiting the geometrical prior, our proposal: i) outperforms existing approaches in the literature and ii) couples well with both compact and complex depth-from-mono architectures, allowing for its deployment on high-end GPUs as well as on embedded devices (e.g., NVIDIA Jetson TX2).