 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Beyond Words: Self-Supervised Visual Learning for Multimodal Large Language Models
Dec 17, 2025Multimodal Large Language Models (MLLMs) have recently demonstrated impressive capabilities in connecting vision and language, yet their proficiency in fundamental visual reasoning tasks remains limited. This limitation can be attributed to the fact that MLLMs learn visual understanding primarily from textual descriptions, which constitute a subjective and inherently incomplete supervisory signal. Furthermore, the modest scale of multimodal instruction tuning compared to massive text-only pre-training leads MLLMs to overfit language priors while overlooking visual details. To address these issues, we introduce JARVIS, a JEPA-inspired framework for self-supervised visual enhancement in MLLMs. Specifically, we integrate the I-JEPA learning paradigm into the standard vision-language alignment pipeline of MLLMs training. Our approach leverages frozen vision foundation models as context and target encoders, while training the predictor, implemented as the early layers of an LLM, to learn structural and semantic regularities from images without relying exclusively on language supervision. Extensive experiments on standard MLLM benchmarks show that JARVIS consistently improves performance on vision-centric benchmarks across different LLM families, without degrading multimodal reasoning abilities. Our source code is publicly available at: https://github.com/aimagelab/JARVIS.
Lost in Translation? Vocabulary Alignment for Source-Free Domain Adaptation in Open-Vocabulary Semantic Segmentation
Sep 18, 2025



We introduce VocAlign, a novel source-free domain adaptation framework specifically designed for VLMs in open-vocabulary semantic segmentation. Our method adopts a student-teacher paradigm enhanced with a vocabulary alignment strategy, which improves pseudo-label generation by incorporating additional class concepts. To ensure efficiency, we use Low-Rank Adaptation (LoRA) to fine-tune the model, preserving its original capabilities while minimizing computational overhead. In addition, we propose a Top-K class selection mechanism for the student model, which significantly reduces memory requirements while further improving adaptation performance. Our approach achieves a notable 6.11 mIoU improvement on the CityScapes dataset and demonstrates superior performance on zero-shot segmentation benchmarks, setting a new standard for source-free adaptation in the open-vocabulary setting.
Semantic Library Adaptation: LoRA Retrieval and Fusion for Open-Vocabulary Semantic Segmentation
Mar 27, 2025Open-vocabulary semantic segmentation models associate vision and text to label pixels from an undefined set of classes using textual queries, providing versatile performance on novel datasets. However, large shifts between training and test domains degrade their performance, requiring fine-tuning for effective real-world applications. We introduce Semantic Library Adaptation (SemLA), a novel framework for training-free, test-time domain adaptation. SemLA leverages a library of LoRA-based adapters indexed with CLIP embeddings, dynamically merging the most relevant adapters based on proximity to the target domain in the embedding space. This approach constructs an ad-hoc model tailored to each specific input without additional training. Our method scales efficiently, enhances explainability by tracking adapter contributions, and inherently protects data privacy, making it ideal for sensitive applications. Comprehensive experiments on a 20-domain benchmark built over 10 standard datasets demonstrate SemLA's superior adaptability and performance across diverse settings, establishing a new standard in domain adaptation for open-vocabulary semantic segmentation.
To Adapt or Not to Adapt? Real-Time Adaptation for Semantic Segmentation
Aug 07, 2023
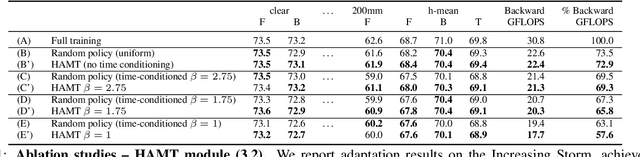
The goal of Online Domain Adaptation for semantic segmentation is to handle unforeseeable domain changes that occur during deployment, like sudden weather events. However, the high computational costs associated with brute-force adaptation make this paradigm unfeasible for real-world applications. In this paper we propose HAMLET, a Hardware-Aware Modular Least Expensive Training framework for real-time domain adaptation. Our approach includes a hardware-aware back-propagation orchestration agent (HAMT) and a dedicated domain-shift detector that enables active control over when and how the model is adapted (LT). Thanks to these advancements, our approach is capable of performing semantic segmentation while simultaneously adapting at more than 29FPS on a single consumer-grade GPU. Our framework's encouraging accuracy and speed trade-off is demonstrated on OnDA and SHIFT benchmarks through experimental results.
Online Domain Adaptation for Semantic Segmentation in Ever-Changing Conditions
Jul 21, 2022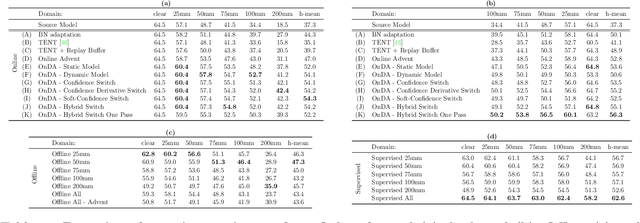



Unsupervised Domain Adaptation (UDA) aims at reducing the domain gap between training and testing data and is, in most cases, carried out in offline manner. However, domain changes may occur continuously and unpredictably during deployment (e.g. sudden weather changes). In such conditions, deep neural networks witness dramatic drops in accuracy and offline adaptation may not be enough to contrast it. In this paper, we tackle Online Domain Adaptation (OnDA) for semantic segmentation. We design a pipeline that is robust to continuous domain shifts, either gradual or sudden, and we evaluate it in the case of rainy and foggy scenarios. Our experiments show that our framework can effectively adapt to new domains during deployment, while not being affected by catastrophic forgetting of the previous domains.
Real-Time Semantic Stereo Matching
Oct 01, 2019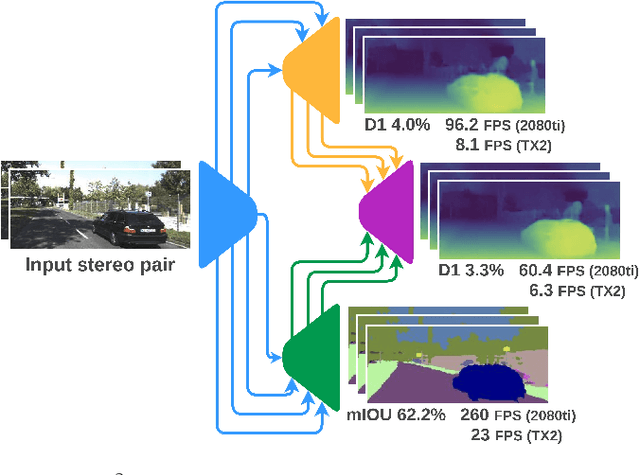
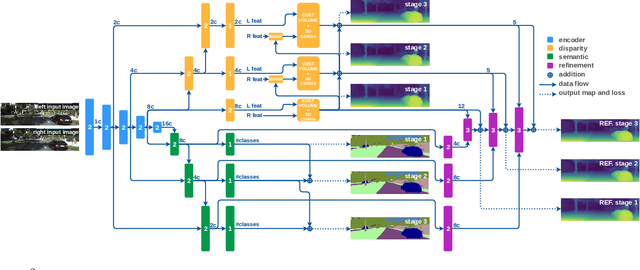

Scene understanding is paramount in robotics, self-navigation, augmented reality, and many other fields. To fully accomplish this task, an autonomous agent has to infer the 3D structure of the sensed scene (to know where it looks at) and its content (to know what it sees). To tackle the two tasks, deep neural networks trained to infer semantic segmentation and depth from stereo images are often the preferred choices. Specifically, Semantic Stereo Matching can be tackled by either standalone models trained for the two tasks independently or joint end-to-end architectures. Nonetheless, as proposed so far, both solutions are inefficient because requiring two forward passes in the former case or due to the complexity of a single network in the latter, although jointly tackling both tasks is usually beneficial in terms of accuracy. In this paper, we propose a single compact and lightweight architecture for real-time semantic stereo matching. Our framework relies on coarse-to-fine estimations in a multi-stage fashion, allowing: i) very fast inference even on embedded devices, with marginal drops in accuracy, compared to state-of-the-art networks, ii) trade accuracy for speed, according to the specific application requirements. Experimental results on high-end GPUs as well as on an embedded Jetson TX2 confirm the superiority of semantic stereo matching compared to standalone tasks and highlight the versatility of our framework on any hardware and for any application.
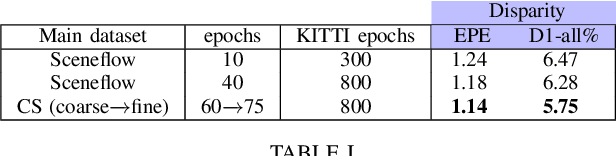
Enhancing self-supervised monocular depth estimation with traditional visual odometry
Aug 12, 2019
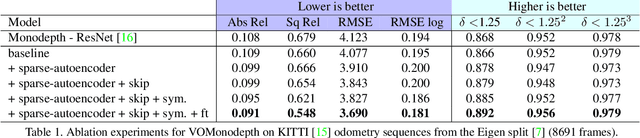
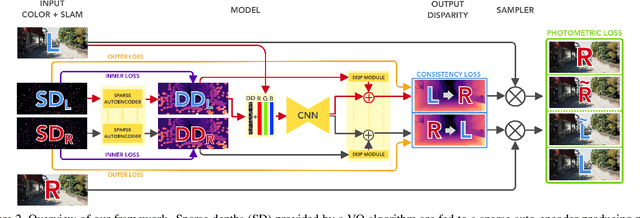
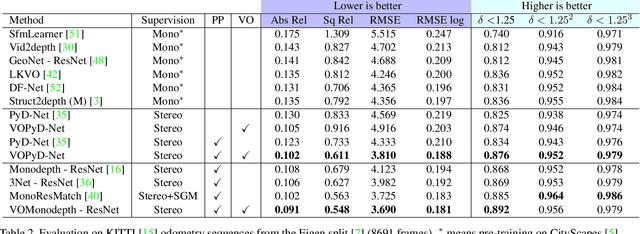
Estimating depth from a single image represents an attractive alternative to more traditional approaches leveraging multiple cameras. In this field, deep learning yielded outstanding results at the cost of needing large amounts of data labeled with precise depth measurements for training. An issue softened by self-supervised approaches leveraging monocular sequences or stereo pairs in place of expensive ground truth depth annotations. This paper enables to further improve monocular depth estimation by integrating into existing self-supervised networks a geometrical prior. Specifically, we propose a sparsity-invariant autoencoder able to process the output of conventional visual odometry algorithms working in synergy with depth-from-mono networks. Experimental results on the KITTI dataset show that by exploiting the geometrical prior, our proposal: i) outperforms existing approaches in the literature and ii) couples well with both compact and complex depth-from-mono architectures, allowing for its deployment on high-end GPUs as well as on embedded devices (e.g., NVIDIA Jetson TX2).